 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness by Augmenting Training Sentences with Predicate-Argument Structures
Oct 23, 2020
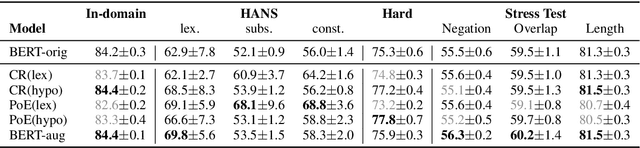


Existing NLP datasets contain various biases, and models tend to quickly learn those biases, which in turn limits their robustness. Existing approaches to improve robustness against dataset biases mostly focus on changing the training objective so that models learn less from biased examples. Besides, they mostly focus on addressing a specific bias, and while they improve the performance on adversarial evaluation sets of the targeted bias, they may bias the model in other ways, and therefore, hurt the overall robustness. In this paper, we propose to augment the input sentences in the training data with their corresponding predicate-argument structures, which provide a higher-level abstraction over different realizations of the same meaning and help the model to recognize important parts of sentences. We show that without targeting a specific bias, our sentence augmentation improves the robustness of transformer models against multiple biases. In addition, we show that models can still be vulnerable to the lexical overlap bias, even when the training data does not contain this bias, and that the sentence augmentation also improves the robustness in this scenario. We will release our adversarial datasets to evaluate bias in such a scenario as well as our augmentation scripts at https://github.com/UKPLab/data-augmentation-for-robustness.