 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiFormer3D: Grid-Free Time-Domain Reconstruction of Head-Related Impulse Responses with a Spatially Encoded Transformer
Mar 30, 2026Individualized head-related impulse responses (HRIRs) enable binaural rendering, but dense per-listener measurements are costly. We address HRIR spatial up-sampling from sparse per-listener measurements: given a few measured HRIRs for a listener, predict HRIRs at unmeasured target directions. Prior learning methods often work in the frequency domain, rely on minimum-phase assumptions or separate timing models, and use a fixed direction grid, which can degrade temporal fidelity and spatial continuity. We propose BiFormer3D, a time-domain, grid-free binaural Transformer for reconstructing HRIRs at arbitrary directions from sparse inputs. It uses sinusoidal spatial features, a Conv1D refinement module, and auxiliary interaural time difference (ITD) and interaural level difference (ILD) heads. On SONICOM, it improves normalized mean squared error (NMSE), cosine distance, and ITD/ILD errors over prior methods; ablations validate modules and show minimum-phase pre-processing is unnecessary.
RIR-Former: Coordinate-Guided Transformer for Continuous Reconstruction of Room Impulse Responses
Feb 03, 2026Room impulse responses (RIRs) are essential for many acoustic signal processing tasks, yet measuring them densely across space is often impractical. In this work, we propose RIR-Former, a grid-free, one-step feed-forward model for RIR reconstruction. By introducing a sinusoidal encoding module into a transformer backbone, our method effectively incorporates microphone position information, enabling interpolation at arbitrary array locations. Furthermore, a segmented multi-branch decoder is designed to separately handle early reflections and late reverberation, improving reconstruction across the entire RIR. Experiments on diverse simulated acoustic environments demonstrate that RIR-Former consistently outperforms state-of-the-art baselines in terms of normalized mean square error (NMSE) and cosine distance (CD), under varying missing rates and array configurations. These results highlight the potential of our approach for practical deployment and motivate future work on scaling from randomly spaced linear arrays to complex array geometries, dynamic acoustic scenes, and real-world environments.
Source Localization by Multidimensional Steered Response Power Mapping with Sparse Bayesian Learning
May 20, 2024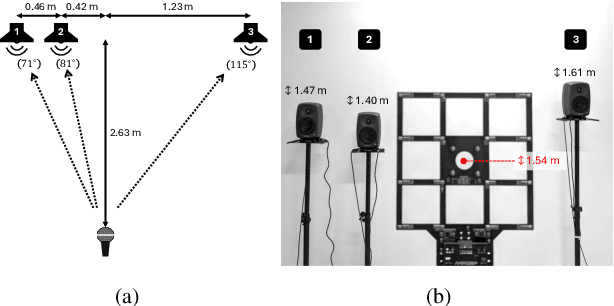
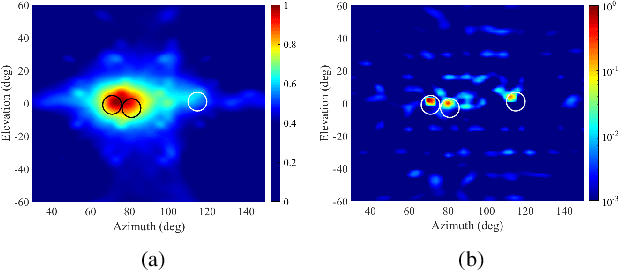
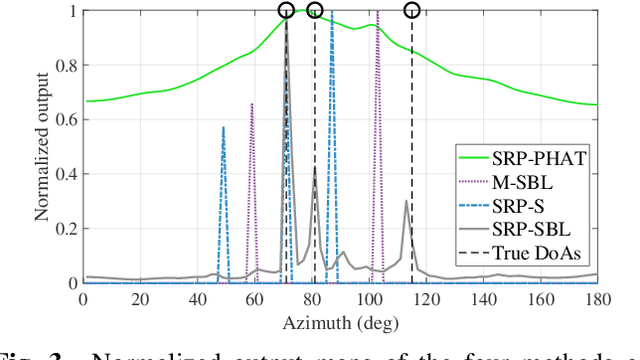
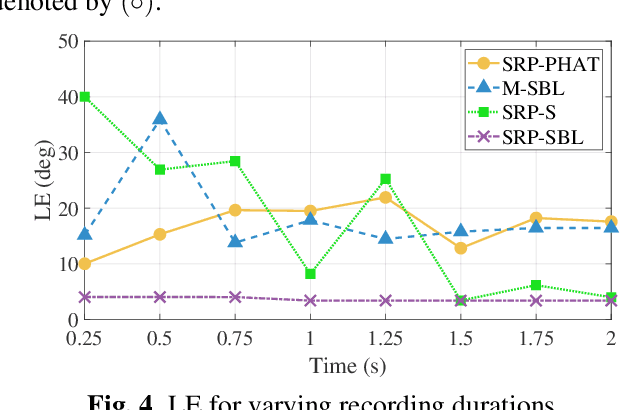
We propose an advance Steered Response Power (SRP) method for localizing multiple sources. While conventional SRP performs well in adverse conditions, it remains to struggle in scenarios with closely neighboring sources, resulting in ambiguous SRP maps. We address this issue by applying sparsity optimization in SRP to obtain high-resolution maps. Our approach represents SRP maps as multidimensional matrices to preserve time-frequency information and further improve performance in unfavorable conditions. We use multi-dictionary Sparse Bayesian Learning to localize sources without needing prior knowledge of their quantity. We validate our method through practical experiments with a 16-channel planar microphone array and compare against three other SRP and sparsity-based methods. Our multidimensional SRP approach outperforms conventional SRP and the current state-of-the-art sparse SRP methods for localizing closely spaced sources in a reverberant room.
Head-Related Transfer Function Interpolation with a Spherical CNN
Sep 15, 2023Head-related transfer functions (HRTFs) are crucial for spatial soundfield reproduction in virtual reality applications. However, obtaining personalized, high-resolution HRTFs is a time-consuming and costly task. Recently, deep learning-based methods showed promise in interpolating high-resolution HRTFs from sparse measurements. Some of these methods treat HRTF interpolation as an image super-resolution task, which neglects spatial acoustic features. This paper proposes a spherical convolutional neural network method for HRTF interpolation. The proposed method realizes the convolution process by decomposing and reconstructing HRTF through the Spherical Harmonics (SHs). The SHs, an orthogonal function set defined on a sphere, allow the convolution layers to effectively capture the spatial features of HRTFs, which are sampled on a sphere. Simulation results demonstrate the effectiveness of the proposed method in achieving accurate interpolation from sparse measurements, outperforming the SH method and learning-based methods.
Circumvent spherical Bessel function nulls for open sphere microphone arrays with physics informed neural network
Aug 01, 2023Open sphere microphone arrays (OSMAs) are simple to design and do not introduce scattering fields, and thus can be advantageous than other arrays for implementing spatial acoustic algorithms under spherical model decomposition. However, an OSMA suffers from spherical Bessel function nulls which make it hard to obtain some sound field coefficients at certain frequencies. This paper proposes to assist an OSMA for sound field analysis with physics informed neural network (PINN). A PINN models the measurement of an OSMA and predicts the sound field on another sphere whose radius is different from that of the OSMA. Thanks to the fact that spherical Bessel function nulls vary with radius, the sound field coefficients which are hard to obtain based on the OSMA measurement directly can be obtained based on the prediction. Simulations confirm the effectiveness of this approach and compare it with the rigid sphere approach.
Physics Informed Neural Network for Head-Related Transfer Function Upsampling
Jul 27, 2023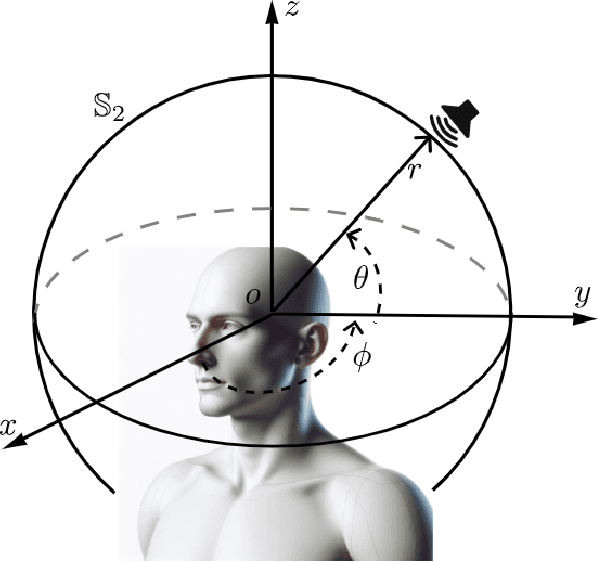
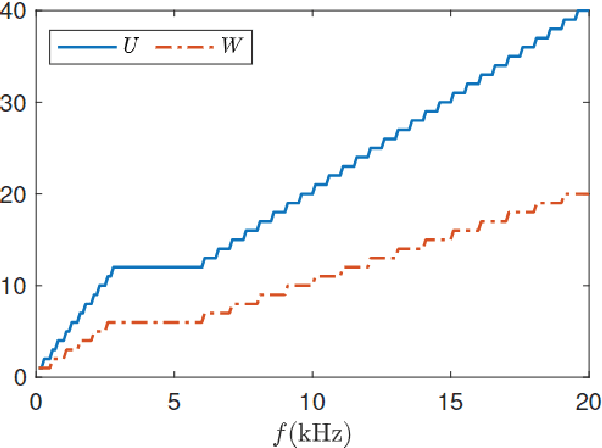
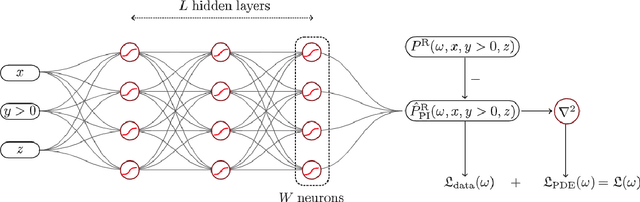
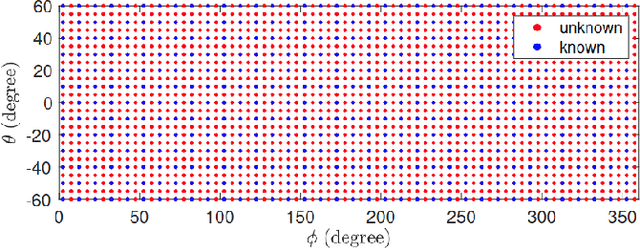
Head-related transfer functions (HRTFs) capture the spatial and spectral features that a person uses to localize sound sources in space and thus are vital for creating an authentic virtual acoustic experience. However, practical HRTF measurement systems can only provide an incomplete measurement of a person's HRTFs, and this necessitates HRTF upsampling. This paper proposes a physics-informed neural network (PINN) method for HRTF upsampling. Unlike other upsampling methods which are based on the measured HRTFs only, the PINN method exploits the Helmholtz equation as additional information for constraining the upsampling process. This helps the PINN method to generate physically amiable upsamplings which generalize beyond the measured HRTFs. Furthermore, the width and the depth of the PINN are set according to the dimensionality of HRTFs under spherical harmonic (SH) decomposition and the Helmholtz equation. This makes the PINN have an appropriate level of expressiveness and thus does not suffer from under-fitting and over-fitting problems. Numerical experiments confirm the superior performance of the PINN method for HRTF upsampling in both interpolation and extrapolation scenarios over several datasets in comparison with the SH methods.
GMM based multi-stage Wiener filtering for low SNR speech enhancement
Jun 19, 2022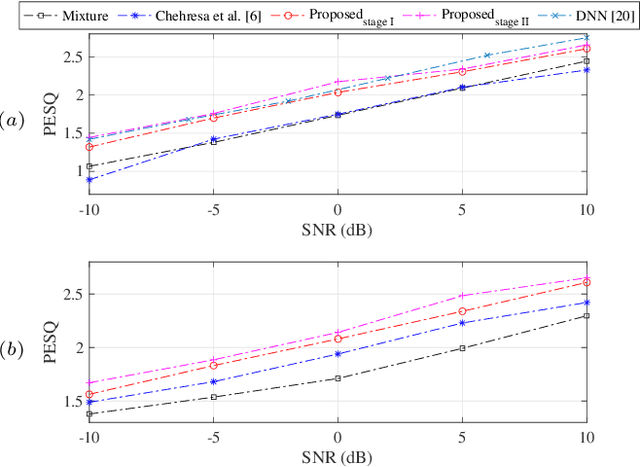
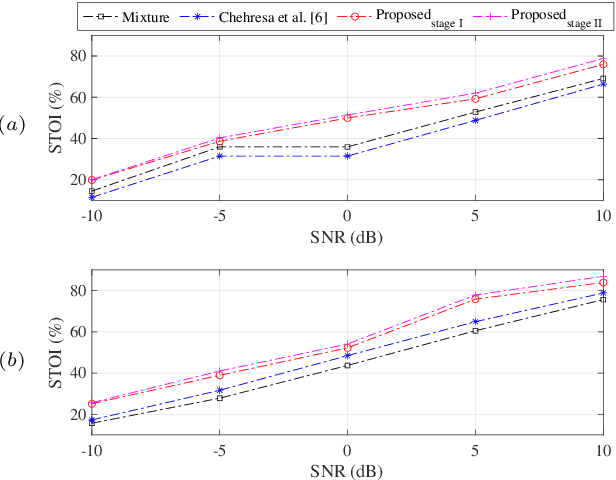
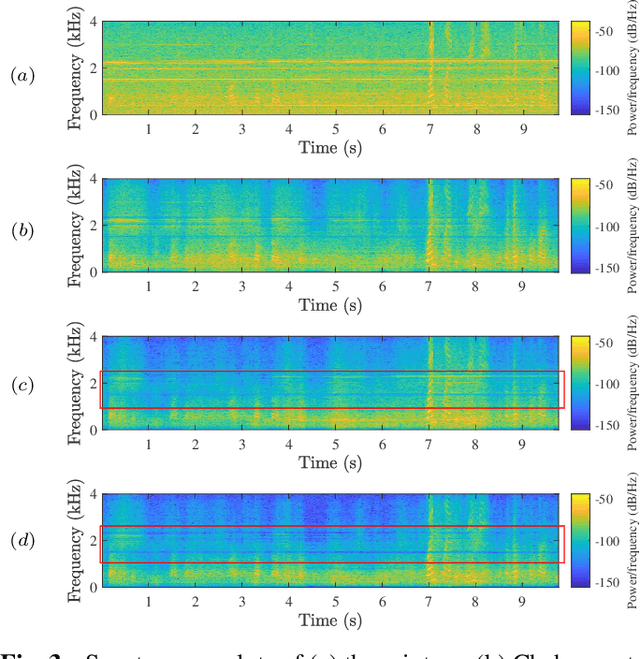
This paper proposes a single-channel speech enhancement method to reduce the noise and enhance speech at low signal-to-noise ratio (SNR) levels and non-stationary noise conditions. Specifically, we focus on modeling the noise using a Gaussian mixture model (GMM) based on a multi-stage process with a parametric Wiener filter. The proposed noise model estimates a more accurate noise power spectral density (PSD), and allows for better generalization under various noise conditions compared to traditional Wiener filtering methods. Simulations show that the proposed approach can achieve better performance in terms of speech quality (PESQ) and intelligibility (STOI) at low SNR levels.
A time-domain nearfield frequency-invariant beamforming method
May 18, 2021

Most existing beamforming methods are frequency-domain methods, and are designed for enhancing a farfield target source over a narrow frequency band. They have found diverse applications and are still under active development. However, they struggle to achieve desired performance if the target source is in the nearfield with a broadband output. This paper proposes a time-domain nearfield frequency-invariant beamforming method. The time-domain implementation makes the beamformer output suitable for further use by real-time applications, the nearfield focusing enables the beamforming method to suppress an interference even if it is in the same direction as the target source, and the frequency-invariant beampattern makes the beamforming method suitable for enhancing the target source over a broad frequency band. These three features together make the beamforming method suitable for real-time broadband nearfield source enhancement, such as speech enhancement in room environments. The beamformer design process is separated from the sound field measurement process, and such that a designed beamformer applies to sensor arrays with various structures. The beamformer design process is further simplified by decomposing it into several independent parts. Simulation results confirm the performance of the proposed beamforming method.