 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Named Entity Recognition for Marathi Documents
Oct 11, 2024



The demand for sophisticated natural language processing (NLP) methods, particularly Named Entity Recognition (NER), has increased due to the exponential growth of Marathi-language digital content. In particular, NER is essential for recognizing distant entities and for arranging and understanding unstructured Marathi text data. With an emphasis on managing long-range entities, this paper offers a comprehensive analysis of current NER techniques designed for Marathi documents. It dives into current practices and investigates the BERT transformer model's potential for long-range Marathi NER. Along with analyzing the effectiveness of earlier methods, the report draws comparisons between NER in English literature and suggests adaptation strategies for Marathi literature. The paper discusses the difficulties caused by Marathi's particular linguistic traits and contextual subtleties while acknowledging NER's critical role in NLP. To conclude, this project is a major step forward in improving Marathi NER techniques, with potential wider applications across a range of NLP tasks and domains.
L3Cube-MahaSum: A Comprehensive Dataset and BART Models for Abstractive Text Summarization in Marathi
Oct 11, 2024

We present the MahaSUM dataset, a large-scale collection of diverse news articles in Marathi, designed to facilitate the training and evaluation of models for abstractive summarization tasks in Indic languages. The dataset, containing 25k samples, was created by scraping articles from a wide range of online news sources and manually verifying the abstract summaries. Additionally, we train an IndicBART model, a variant of the BART model tailored for Indic languages, using the MahaSUM dataset. We evaluate the performance of our trained models on the task of abstractive summarization and demonstrate their effectiveness in producing high-quality summaries in Marathi. Our work contributes to the advancement of natural language processing research in Indic languages and provides a valuable resource for future research in this area using state-of-the-art models. The dataset and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP
Leveraging Parameter Efficient Training Methods for Low Resource Text Classification: A Case Study in Marathi
Aug 06, 2024
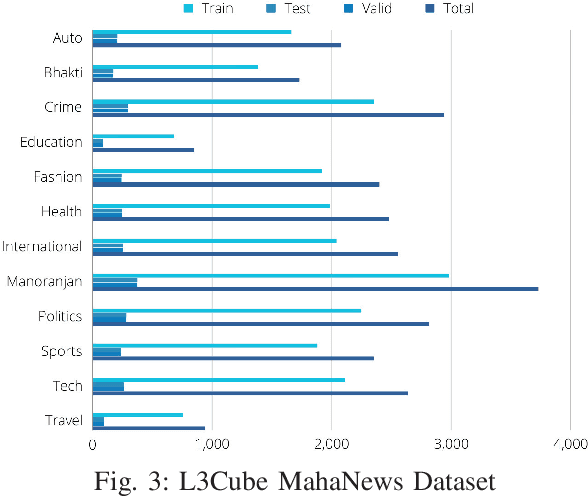
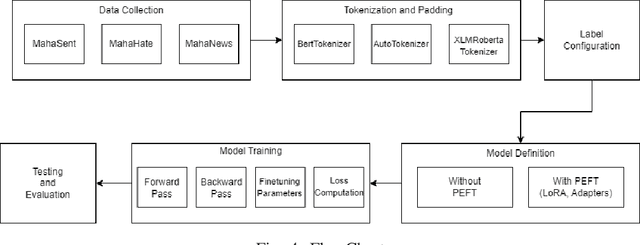

With the surge in digital content in low-resource languages, there is an escalating demand for advanced Natural Language Processing (NLP) techniques tailored to these languages. BERT (Bidirectional Encoder Representations from Transformers), serving as the foundational framework for numerous NLP architectures and language models, is increasingly employed for the development of low-resource NLP models. Parameter Efficient Fine-Tuning (PEFT) is a method for fine-tuning Large Language Models (LLMs) and reducing the training parameters to some extent to decrease the computational costs needed for training the model and achieve results comparable to a fully fine-tuned model. In this work, we present a study of PEFT methods for the Indic low-resource language Marathi. We conduct a comprehensive analysis of PEFT methods applied to various monolingual and multilingual Marathi BERT models. These approaches are evaluated on prominent text classification datasets like MahaSent, MahaHate, and MahaNews. The incorporation of PEFT techniques is demonstrated to significantly expedite the training speed of the models, addressing a critical aspect of model development and deployment. In this study, we explore Low-Rank Adaptation of Large Language Models (LoRA) and adapter methods for low-resource text classification. We show that these methods are competitive with full fine-tuning and can be used without loss in accuracy. This study contributes valuable insights into the effectiveness of Marathi BERT models, offering a foundation for the continued advancement of NLP capabilities in Marathi and similar Indic languages.