 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Parameter Efficient Training Methods for Low Resource Text Classification: A Case Study in Marathi
Paper and Code

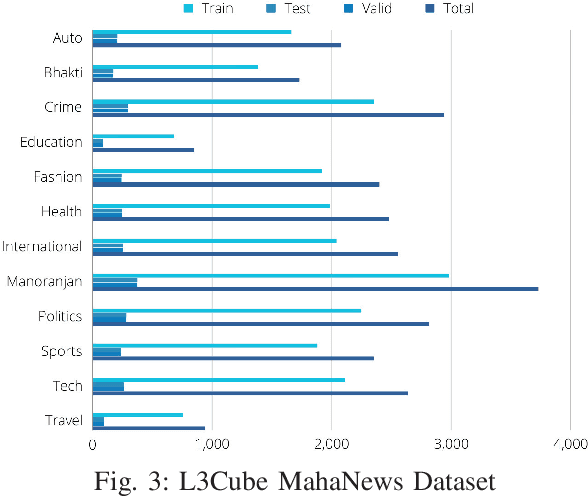
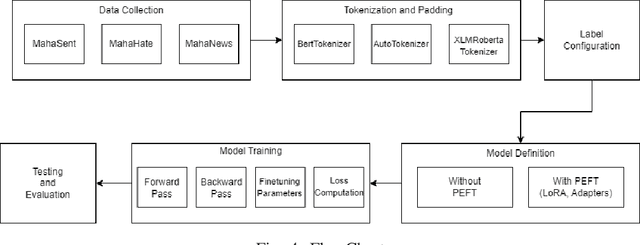

With the surge in digital content in low-resource languages, there is an escalating demand for advanced Natural Language Processing (NLP) techniques tailored to these languages. BERT (Bidirectional Encoder Representations from Transformers), serving as the foundational framework for numerous NLP architectures and language models, is increasingly employed for the development of low-resource NLP models. Parameter Efficient Fine-Tuning (PEFT) is a method for fine-tuning Large Language Models (LLMs) and reducing the training parameters to some extent to decrease the computational costs needed for training the model and achieve results comparable to a fully fine-tuned model. In this work, we present a study of PEFT methods for the Indic low-resource language Marathi. We conduct a comprehensive analysis of PEFT methods applied to various monolingual and multilingual Marathi BERT models. These approaches are evaluated on prominent text classification datasets like MahaSent, MahaHate, and MahaNews. The incorporation of PEFT techniques is demonstrated to significantly expedite the training speed of the models, addressing a critical aspect of model development and deployment. In this study, we explore Low-Rank Adaptation of Large Language Models (LoRA) and adapter methods for low-resource text classification. We show that these methods are competitive with full fine-tuning and can be used without loss in accuracy. This study contributes valuable insights into the effectiveness of Marathi BERT models, offering a foundation for the continued advancement of NLP capabilities in Marathi and similar Indic languages.