 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation in Indian Languages: Challenges and Resolution
Aug 01, 2018



English to Indian language machine translation poses the challenge of structural and morphological divergence. This paper describes English to Indian language statistical machine translation using pre-ordering and suffix separation. The pre-ordering uses rules to transfer the structure of the source sentences prior to training and translation. This syntactic restructuring helps statistical machine translation to tackle the structural divergence and hence better translation quality. The suffix separation is used to tackle the morphological divergence between English and highly agglutinative Indian languages. We demonstrate that the use of pre-ordering and suffix separation helps in improving the quality of English to Indian Language machine translation.
Recurrent Neural Network based Part-of-Speech Tagger for Code-Mixed Social Media Text
Nov 16, 2016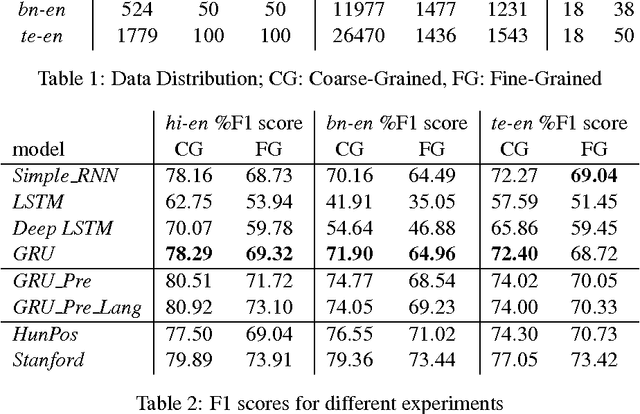

This paper describes Centre for Development of Advanced Computing's (CDACM) submission to the shared task-'Tool Contest on POS tagging for Code-Mixed Indian Social Media (Facebook, Twitter, and Whatsapp) Text', collocated with ICON-2016. The shared task was to predict Part of Speech (POS) tag at word level for a given text. The code-mixed text is generated mostly on social media by multilingual users. The presence of the multilingual words, transliterations, and spelling variations make such content linguistically complex. In this paper, we propose an approach to POS tag code-mixed social media text using Recurrent Neural Network Language Model (RNN-LM) architecture. We submitted the results for Hindi-English (hi-en), Bengali-English (bn-en), and Telugu-English (te-en) code-mixed data.
* 7 pages, Published at the Tool Contest on POS tagging for Indian Social Media Text, ICON 2016
Experiments with POS Tagging Code-mixed Indian Social Media Text
Oct 31, 2016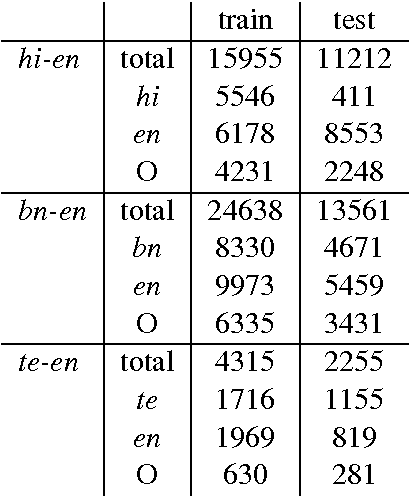


This paper presents Centre for Development of Advanced Computing Mumbai's (CDACM) submission to the NLP Tools Contest on Part-Of-Speech (POS) Tagging For Code-mixed Indian Social Media Text (POSCMISMT) 2015 (collocated with ICON 2015). We submitted results for Hindi (hi), Bengali (bn), and Telugu (te) languages mixed with English (en). In this paper, we have described our approaches to the POS tagging techniques, we exploited for this task. Machine learning has been used to POS tag the mixed language text. For POS tagging, distributed representations of words in vector space (word2vec) for feature extraction and Log-linear models have been tried. We report our work on all three languages hi, bn, and te mixed with en.
* 3 Pages, Published in the Proceedings of the Tool Contest on POS Tagging for Code-mixed Indian Social Media (Facebook, Twitter, and Whatsapp) Text
Statistical Machine Translation for Indian Languages: Mission Hindi 2
Oct 25, 2016
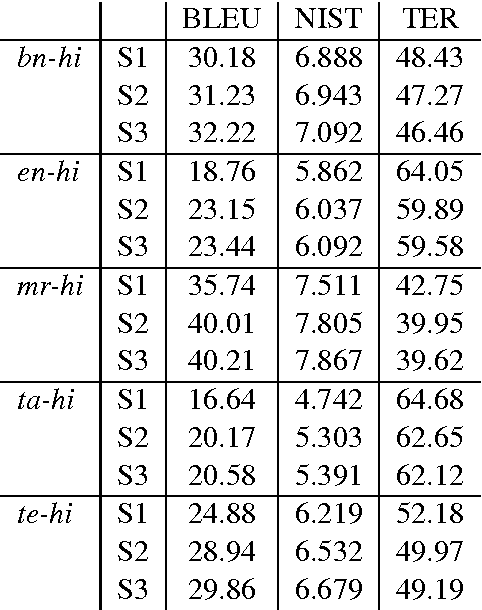
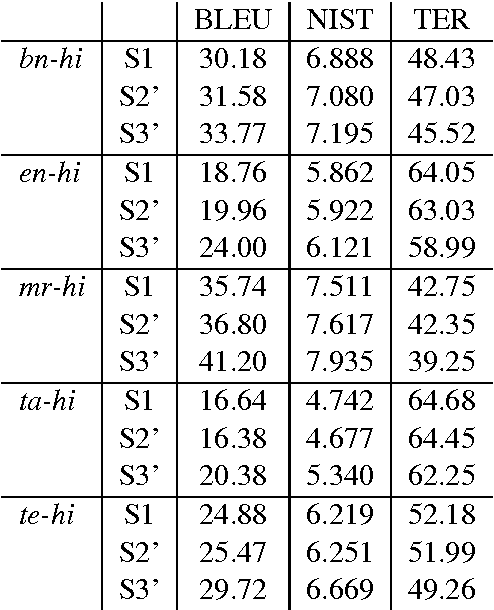
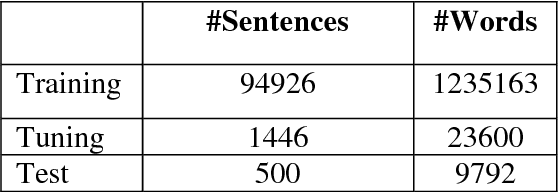
This paper presents Centre for Development of Advanced Computing Mumbai's (CDACM) submission to NLP Tools Contest on Statistical Machine Translation in Indian Languages (ILSMT) 2015 (collocated with ICON 2015). The aim of the contest was to collectively explore the effectiveness of Statistical Machine Translation (SMT) while translating within Indian languages and between English and Indian languages. In this paper, we report our work on all five language pairs, namely Bengali-Hindi (\bnhi), Marathi-Hindi (\mrhi), Tamil-Hindi (\tahi), Telugu-Hindi (\tehi), and English-Hindi (\enhi) for Health, Tourism, and General domains. We have used suffix separation, compound splitting and preordering prior to SMT training and testing.
* 4 pages, Published in the Proceedings of NLP Tools Contest: Statistical Machine Translation in Indian Languages
Reordering rules for English-Hindi SMT
Oct 24, 2016


Reordering is a preprocessing stage for Statistical Machine Translation (SMT) system where the words of the source sentence are reordered as per the syntax of the target language. We are proposing a rich set of rules for better reordering. The idea is to facilitate the training process by better alignments and parallel phrase extraction for a phrase-based SMT system. Reordering also helps the decoding process and hence improving the machine translation quality. We have observed significant improvements in the translation quality by using our approach over the baseline SMT. We have used BLEU, NIST, multi-reference word error rate, multi-reference position independent error rate for judging the improvements. We have exploited open source SMT toolkit MOSES to develop the system.
Statistical Machine Translation for Indian Languages: Mission Hindi
Oct 24, 2016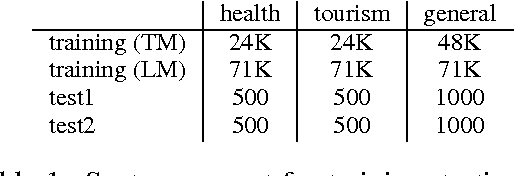

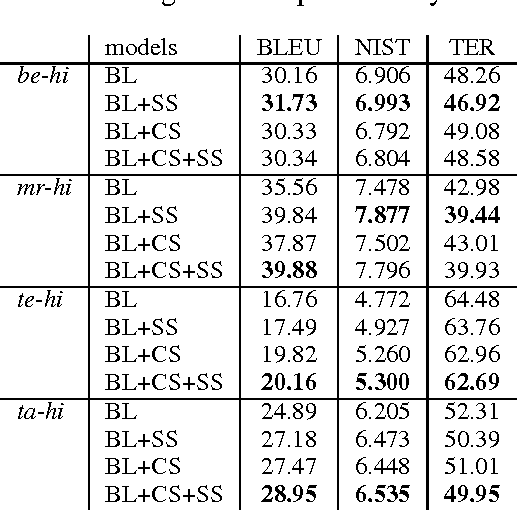

This paper discusses Centre for Development of Advanced Computing Mumbai's (CDACM) submission to the NLP Tools Contest on Statistical Machine Translation in Indian Languages (ILSMT) 2014 (collocated with ICON 2014). The objective of the contest was to explore the effectiveness of Statistical Machine Translation (SMT) for Indian language to Indian language and English-Hindi machine translation. In this paper, we have proposed that suffix separation and word splitting for SMT from agglutinative languages to Hindi significantly improves over the baseline (BL). We have also shown that the factored model with reordering outperforms the phrase-based SMT for English-Hindi (\enhi). We report our work on all five pairs of languages, namely Bengali-Hindi (\bnhi), Marathi-Hindi (\mrhi), Tamil-Hindi (\tahi), Telugu-Hindi (\tehi), and \enhi for Health, Tourism, and General domains.