 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReordering rules for English-Hindi SMT
Oct 24, 2016


Reordering is a preprocessing stage for Statistical Machine Translation (SMT) system where the words of the source sentence are reordered as per the syntax of the target language. We are proposing a rich set of rules for better reordering. The idea is to facilitate the training process by better alignments and parallel phrase extraction for a phrase-based SMT system. Reordering also helps the decoding process and hence improving the machine translation quality. We have observed significant improvements in the translation quality by using our approach over the baseline SMT. We have used BLEU, NIST, multi-reference word error rate, multi-reference position independent error rate for judging the improvements. We have exploited open source SMT toolkit MOSES to develop the system.
Statistical Machine Translation for Indian Languages: Mission Hindi
Oct 24, 2016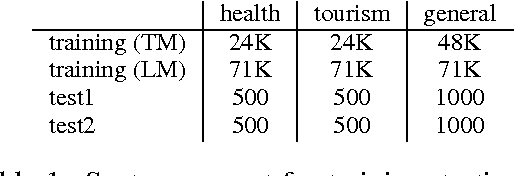

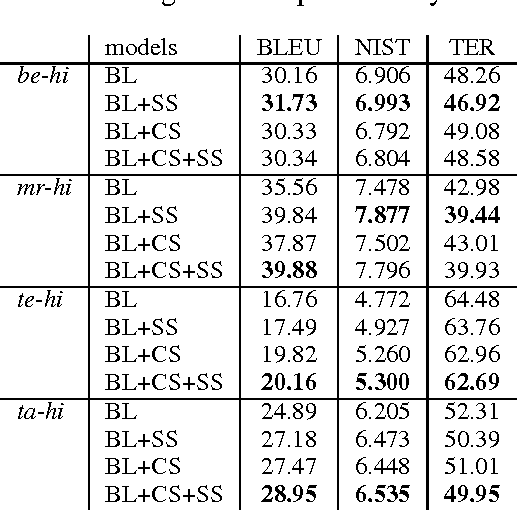

This paper discusses Centre for Development of Advanced Computing Mumbai's (CDACM) submission to the NLP Tools Contest on Statistical Machine Translation in Indian Languages (ILSMT) 2014 (collocated with ICON 2014). The objective of the contest was to explore the effectiveness of Statistical Machine Translation (SMT) for Indian language to Indian language and English-Hindi machine translation. In this paper, we have proposed that suffix separation and word splitting for SMT from agglutinative languages to Hindi significantly improves over the baseline (BL). We have also shown that the factored model with reordering outperforms the phrase-based SMT for English-Hindi (\enhi). We report our work on all five pairs of languages, namely Bengali-Hindi (\bnhi), Marathi-Hindi (\mrhi), Tamil-Hindi (\tahi), Telugu-Hindi (\tehi), and \enhi for Health, Tourism, and General domains.
Translation Quality Estimation using Recurrent Neural Network
Oct 21, 2016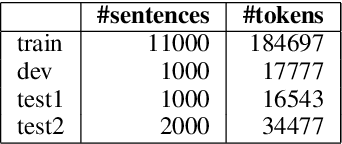
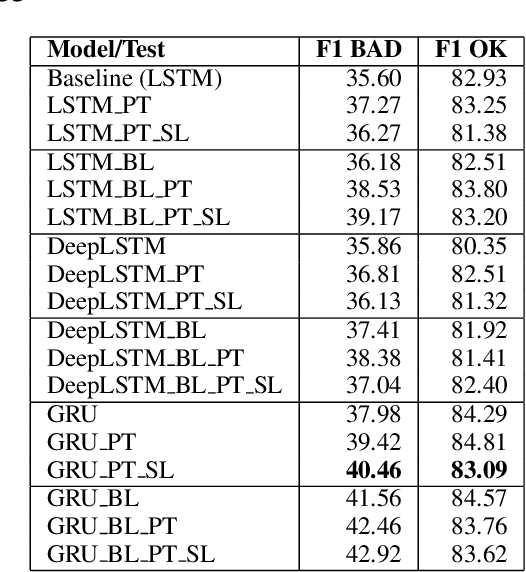
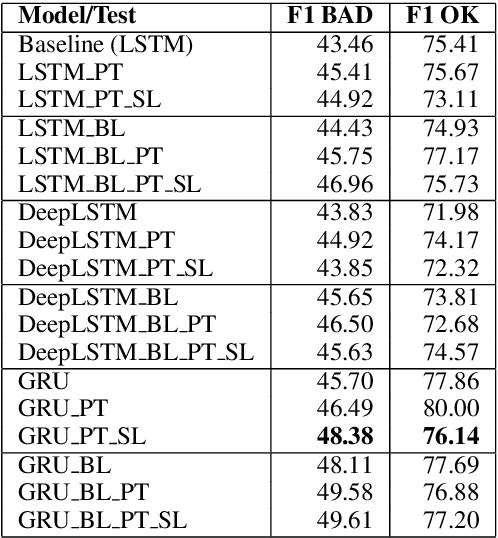

This paper describes our submission to the shared task on word/phrase level Quality Estimation (QE) in the First Conference on Statistical Machine Translation (WMT16). The objective of the shared task was to predict if the given word/phrase is a correct/incorrect (OK/BAD) translation in the given sentence. In this paper, we propose a novel approach for word level Quality Estimation using Recurrent Neural Network Language Model (RNN-LM) architecture. RNN-LMs have been found very effective in different Natural Language Processing (NLP) applications. RNN-LM is mainly used for vector space language modeling for different NLP problems. For this task, we modify the architecture of RNN-LM. The modified system predicts a label (OK/BAD) in the slot rather than predicting the word. The input to the system is a word sequence, similar to the standard RNN-LM. The approach is language independent and requires only the translated text for QE. To estimate the phrase level quality, we use the output of the word level QE system.