Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiments with POS Tagging Code-mixed Indian Social Media Text
Paper and Code
Oct 31, 2016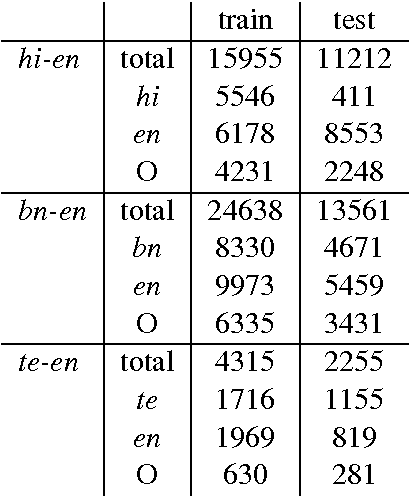


This paper presents Centre for Development of Advanced Computing Mumbai's (CDACM) submission to the NLP Tools Contest on Part-Of-Speech (POS) Tagging For Code-mixed Indian Social Media Text (POSCMISMT) 2015 (collocated with ICON 2015). We submitted results for Hindi (hi), Bengali (bn), and Telugu (te) languages mixed with English (en). In this paper, we have described our approaches to the POS tagging techniques, we exploited for this task. Machine learning has been used to POS tag the mixed language text. For POS tagging, distributed representations of words in vector space (word2vec) for feature extraction and Log-linear models have been tried. We report our work on all three languages hi, bn, and te mixed with en.
* In the Proceedings of the 12th International Conference on Natural
Language Processing (ICON 2015) * 3 Pages, Published in the Proceedings of the Tool Contest on POS
Tagging for Code-mixed Indian Social Media (Facebook, Twitter, and Whatsapp)
Text
View paper on