 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel methods library for pattern analysis and machine learning in python
May 27, 2020
Kernel methods have proven to be powerful techniques for pattern analysis and machine learning (ML) in a variety of domains. However, many of their original or advanced implementations remain in Matlab. With the incredible rise and adoption of Python in the ML and data science world, there is a clear need for a well-defined library that enables not only the use of popular kernels, but also allows easy definition of customized kernels to fine-tune them for diverse applications. The kernelmethods library fills that important void in the python ML ecosystem in a domain-agnostic fashion, allowing the sample data type to be anything from numerical, categorical, graphs or a combination of them. In addition, this library provides a number of well-defined classes to make various kernel-based operations efficient (for large scale datasets), modular (for ease of domain adaptation), and inter-operable (across different ecosystems). The library is available at https://github.com/raamana/kernelmethods.
Assessing and tuning brain decoders: cross-validation, caveats, and guidelines
Nov 07, 2016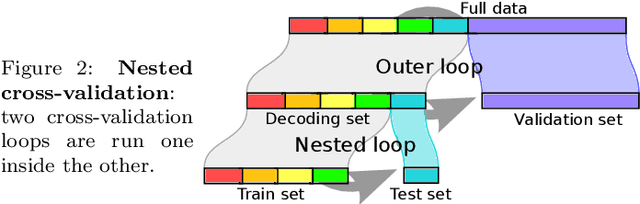
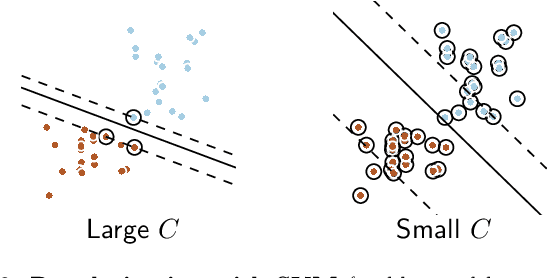
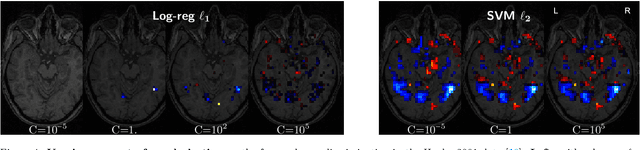

Decoding, ie prediction from brain images or signals, calls for empirical evaluation of its predictive power. Such evaluation is achieved via cross-validation, a method also used to tune decoders' hyper-parameters. This paper is a review on cross-validation procedures for decoding in neuroimaging. It includes a didactic overview of the relevant theoretical considerations. Practical aspects are highlighted with an extensive empirical study of the common decoders in within-and across-subject predictions, on multiple datasets --anatomical and functional MRI and MEG-- and simulations. Theory and experiments outline that the popular " leave-one-out " strategy leads to unstable and biased estimates, and a repeated random splits method should be preferred. Experiments outline the large error bars of cross-validation in neuroimaging settings: typical confidence intervals of 10%. Nested cross-validation can tune decoders' parameters while avoiding circularity bias. However we find that it can be more favorable to use sane defaults, in particular for non-sparse decoders.