 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting High-dimensional Nonlinear Optimization with Conditional GANs
Feb 20, 2021



Many mathematical optimization algorithms fail to sufficiently explore the solution space of high-dimensional nonlinear optimization problems due to the curse of dimensionality. This paper proposes generative models as a complement to optimization algorithms to improve performance in problems with high dimensionality. To demonstrate this method, a conditional generative adversarial network (C-GAN) is used to augment the solutions produced by a genetic algorithm (GA) for a 311-dimensional nonconvex multi-objective mixed-integer nonlinear optimization. The C-GAN, composed of two networks with three fully connected hidden layers, is trained on solutions generated by the GA, and then given sets of desired labels (i.e., objective function values), generates complementary solutions corresponding to those labels. Six experiments are conducted to evaluate the capabilities of the proposed method. The generated complementary solutions are compared to the original solutions in terms of optimality and diversity. The generative model generates solutions with objective functions up to 100% better, and with hypervolumes up to 100% higher, than the original solutions. These findings show that a C-GAN with even a simple training approach and simple architecture can highly improve the diversity and optimality of solutions found by an optimization algorithm for a high-dimensional nonlinear optimization problem.
Ising-Based Louvain Method: Clustering Large Graphs with Specialized Hardware
Dec 06, 2020


Recent advances in specialized hardware for solving optimization problems such quantum computers, quantum annealers, and CMOS annealers give rise to new ways for solving real-word complex problems. However, given current and near-term hardware limitations, the number of variables required to express a large real-world problem easily exceeds the hardware capabilities, thus hybrid methods are usually developed in order to utilize the hardware. In this work, we advocate for the development of hybrid methods that are built on top of the frameworks of existing state-of-art heuristics, thereby improving these methods. We demonstrate this by building on the so called Louvain method, which is one of the most popular algorithms for the Community detection problem and develop and Ising-based Louvain method. The proposed method outperforms two state-of-the-art community detection algorithms in clustering several small to large-scale graphs. The results show promise in adapting the same optimization approach to other unsupervised learning heuristics to improve their performance.
When in Doubt, Ask: Generating Answerable and Unanswerable Questions, Unsupervised
Oct 19, 2020
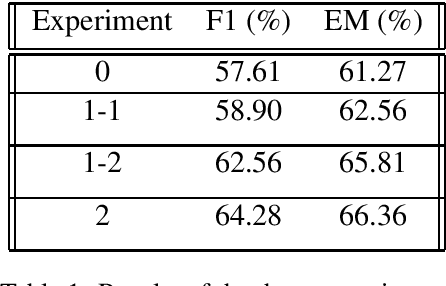


Question Answering (QA) is key for making possible a robust communication between human and machine. Modern language models used for QA have surpassed the human-performance in several essential tasks; however, these models require large amounts of human-generated training data which are costly and time-consuming to create. This paper studies augmenting human-made datasets with synthetic data as a way of surmounting this problem. A state-of-the-art model based on deep transformers is used to inspect the impact of using synthetic answerable and unanswerable questions to complement a well-known human-made dataset. The results indicate a tangible improvement in the performance of the language model (measured in terms of F1 and EM scores) trained on the mixed dataset. Specifically, unanswerable question-answers prove more effective in boosting the model: the F1 score gain from adding to the original dataset the answerable, unanswerable, and combined question-answers were 1.3%, 5.0%, and 6.7%, respectively. [Link to the Github repository: https://github.com/lnikolenko/EQA]
Airbnb Price Prediction Using Machine Learning and Sentiment Analysis
Jul 29, 2019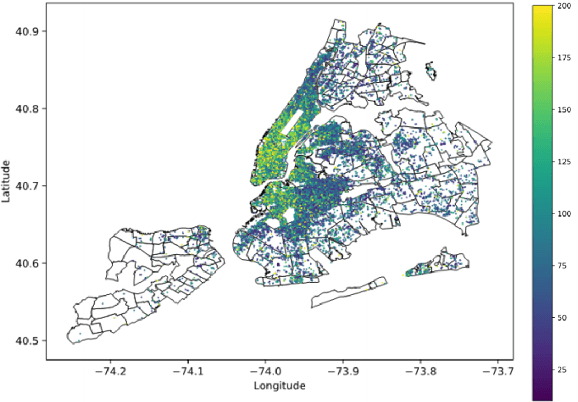
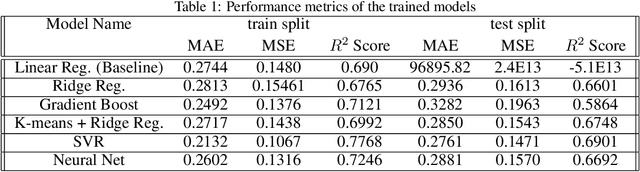
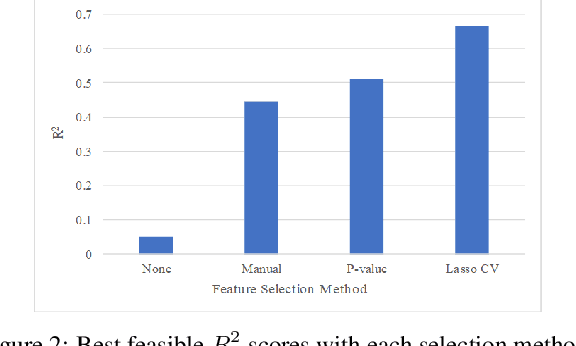
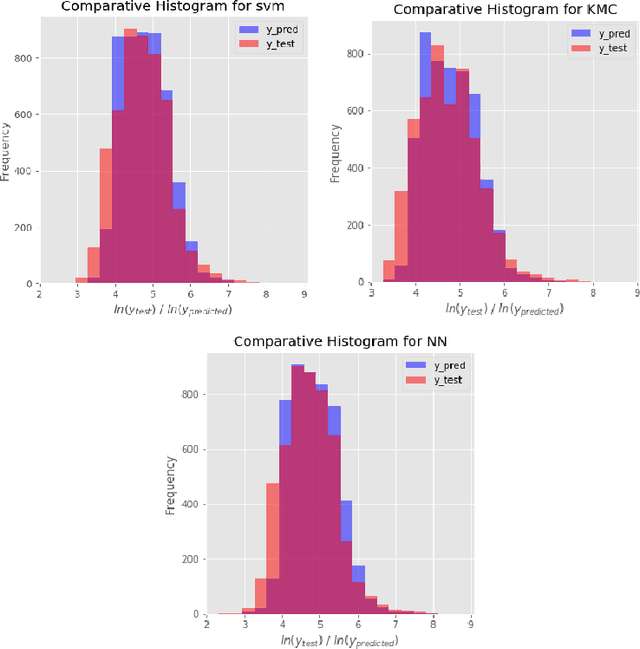
Pricing a rental property on Airbnb is a challenging task for the owner as it determines the number of customers for the place. On the other hand, customers have to evaluate an offered price with minimal knowledge of an optimal value for the property. This paper aims to develop a reliable price prediction model using machine learning, deep learning, and natural language processing techniques to aid both the property owners and the customers with price evaluation given minimal available information about the property. Features of the rentals, owner characteristics, and the customer reviews will comprise the predictors, and a range of methods from linear regression to tree-based models, support-vector regression (SVR), K-means Clustering (KMC), and neural networks (NNs) will be used for creating the prediction model.