 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen in Doubt, Ask: Generating Answerable and Unanswerable Questions, Unsupervised
Paper and Code

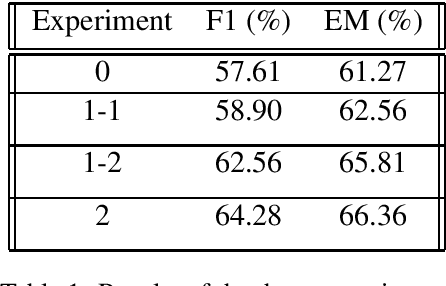


Question Answering (QA) is key for making possible a robust communication between human and machine. Modern language models used for QA have surpassed the human-performance in several essential tasks; however, these models require large amounts of human-generated training data which are costly and time-consuming to create. This paper studies augmenting human-made datasets with synthetic data as a way of surmounting this problem. A state-of-the-art model based on deep transformers is used to inspect the impact of using synthetic answerable and unanswerable questions to complement a well-known human-made dataset. The results indicate a tangible improvement in the performance of the language model (measured in terms of F1 and EM scores) trained on the mixed dataset. Specifically, unanswerable question-answers prove more effective in boosting the model: the F1 score gain from adding to the original dataset the answerable, unanswerable, and combined question-answers were 1.3%, 5.0%, and 6.7%, respectively. [Link to the Github repository: https://github.com/lnikolenko/EQA]