 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Alignment with Mixture Experts Neural Network for Intral-City Retail Recommendation
Sep 17, 2020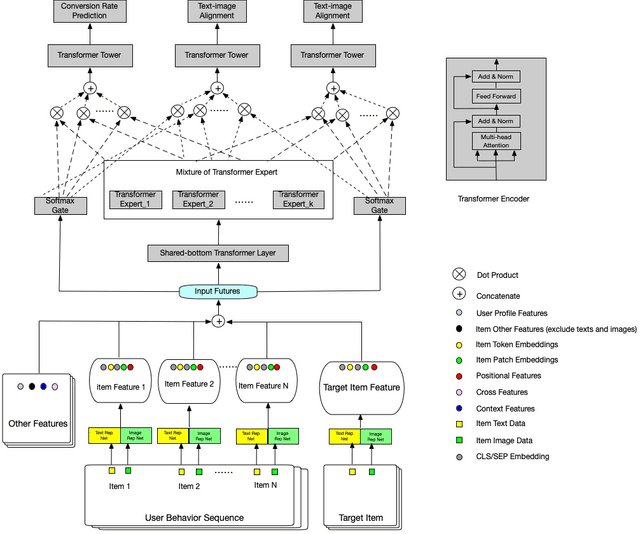

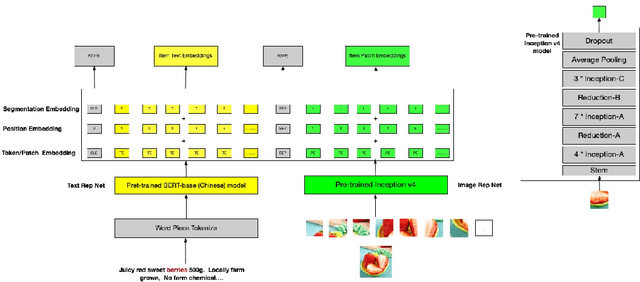

In this paper, we introduce Cross-modal Alignment with mixture experts Neural Network (CameNN) recommendation model for intral-city retail industry, which aims to provide fresh foods and groceries retailing within 5 hours delivery service arising for the outbreak of Coronavirus disease (COVID-19) pandemic around the world. We propose CameNN, which is a multi-task model with three tasks including Image to Text Alignment (ITA) task, Text to Image Alignment (TIA) task and CVR prediction task. We use pre-trained BERT to generate the text embedding and pre-trained InceptionV4 to generate image patch embedding (each image is split into small patches with the same pixels and treat each patch as an image token). Softmax gating networks follow to learn the weight of each transformer expert output and choose only a subset of experts conditioned on the input. Then transformer encoder is applied as the share-bottom layer to learn all input features' shared interaction. Next, mixture of transformer experts (MoE) layer is implemented to model different aspects of tasks. At top of the MoE layer, we deploy a transformer layer for each task as task tower to learn task-specific information. On the real word intra-city dataset, experiments demonstrate CameNN outperform baselines and achieve significant improvements on the image and text representation. In practice, we applied CameNN on CVR prediction in our intra-city recommender system which is one of the leading intra-city platforms operated in China.