 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Cooperative Multi-Agent Reinforcement Learning with Directed Coordination Graph
Jan 10, 2022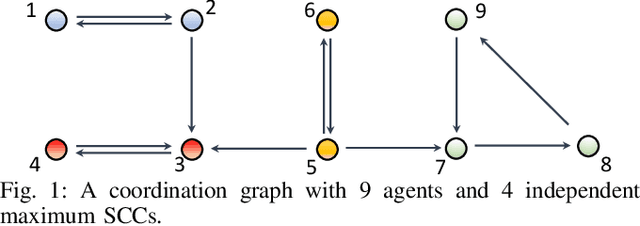
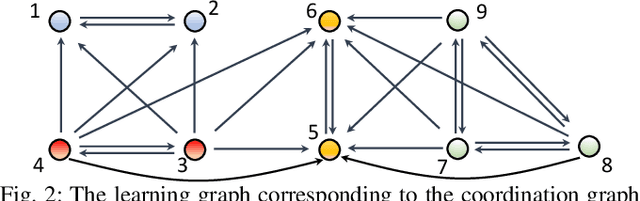
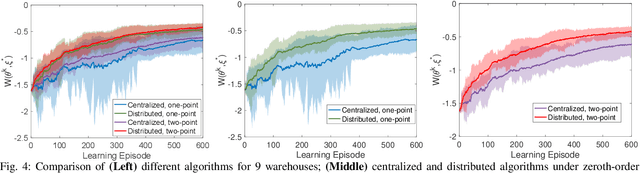
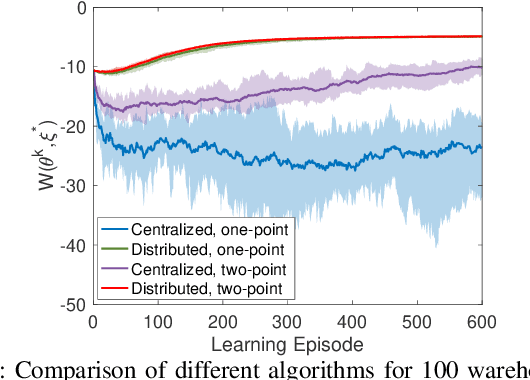
Existing distributed cooperative multi-agent reinforcement learning (MARL) frameworks usually assume undirected coordination graphs and communication graphs while estimating a global reward via consensus algorithms for policy evaluation. Such a framework may induce expensive communication costs and exhibit poor scalability due to requirement of global consensus. In this work, we study MARLs with directed coordination graphs, and propose a distributed RL algorithm where the local policy evaluations are based on local value functions. The local value function of each agent is obtained by local communication with its neighbors through a directed learning-induced communication graph, without using any consensus algorithm. A zeroth-order optimization (ZOO) approach based on parameter perturbation is employed to achieve gradient estimation. By comparing with existing ZOO-based RL algorithms, we show that our proposed distributed RL algorithm guarantees high scalability. A distributed resource allocation example is shown to illustrate the effectiveness of our algorithm.