 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Guarantees for Multi-View Representation Learning and Application to Regularization via Gaussian Product Mixture Prior
Apr 25, 2025We study the problem of distributed multi-view representation learning. In this problem, $K$ agents observe each one distinct, possibly statistically correlated, view and independently extracts from it a suitable representation in a manner that a decoder that gets all $K$ representations estimates correctly the hidden label. In the absence of any explicit coordination between the agents, a central question is: what should each agent extract from its view that is necessary and sufficient for a correct estimation at the decoder? In this paper, we investigate this question from a generalization error perspective. First, we establish several generalization bounds in terms of the relative entropy between the distribution of the representations extracted from training and "test" datasets and a data-dependent symmetric prior, i.e., the Minimum Description Length (MDL) of the latent variables for all views and training and test datasets. Then, we use the obtained bounds to devise a regularizer; and investigate in depth the question of the selection of a suitable prior. In particular, we show and conduct experiments that illustrate that our data-dependent Gaussian mixture priors with judiciously chosen weights lead to good performance. For single-view settings (i.e., $K=1$), our experimental results are shown to outperform existing prior art Variational Information Bottleneck (VIB) and Category-Dependent VIB (CDVIB) approaches. Interestingly, we show that a weighted attention mechanism emerges naturally in this setting. Finally, for the multi-view setting, we show that the selection of the joint prior as a Gaussians product mixture induces a Gaussian mixture marginal prior for each marginal view and implicitly encourages the agents to extract and output redundant features, a finding which is somewhat counter-intuitive.
Generalization Guarantees for Representation Learning via Data-Dependent Gaussian Mixture Priors
Feb 21, 2025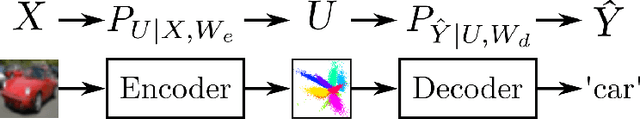
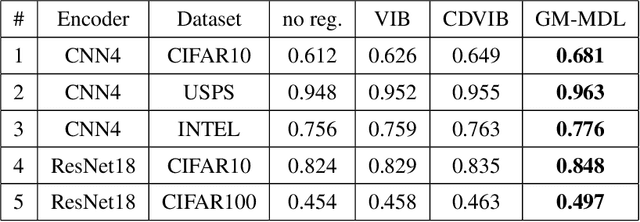
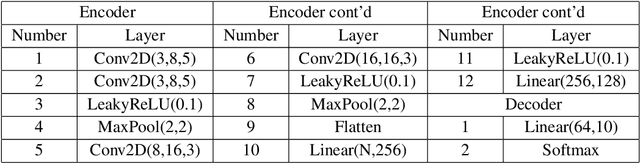
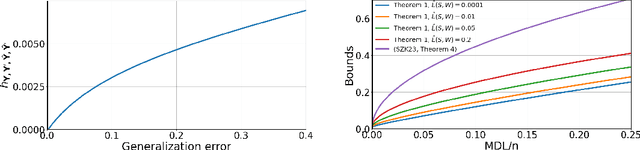
We establish in-expectation and tail bounds on the generalization error of representation learning type algorithms. The bounds are in terms of the relative entropy between the distribution of the representations extracted from the training and "test'' datasets and a data-dependent symmetric prior, i.e., the Minimum Description Length (MDL) of the latent variables for the training and test datasets. Our bounds are shown to reflect the "structure" and "simplicity'' of the encoder and significantly improve upon the few existing ones for the studied model. We then use our in-expectation bound to devise a suitable data-dependent regularizer; and we investigate thoroughly the important question of the selection of the prior. We propose a systematic approach to simultaneously learning a data-dependent Gaussian mixture prior and using it as a regularizer. Interestingly, we show that a weighted attention mechanism emerges naturally in this procedure. Our experiments show that our approach outperforms the now popular Variational Information Bottleneck (VIB) method as well as the recent Category-Dependent VIB (CDVIB).
Minimal Communication-Cost Statistical Learning
Jun 12, 2024
A client device which has access to $n$ training data samples needs to obtain a statistical hypothesis or model $W$ and then to send it to a remote server. The client and the server devices share some common randomness sequence as well as a prior on the hypothesis space. In this problem a suitable hypothesis or model $W$ should meet two distinct design criteria simultaneously: (i) small (population) risk during the inference phase and (ii) small 'complexity' for it to be conveyed to the server with minimum communication cost. In this paper, we propose a joint training and source coding scheme with provable in-expectation guarantees, where the expectation is over the encoder's output message. Specifically, we show that by imposing a constraint on a suitable Kullback-Leibler divergence between the conditional distribution induced by a compressed learning model $\widehat{W}$ given $W$ and the prior, one guarantees simultaneously small average empirical risk (aka training loss), small average generalization error and small average communication cost. We also consider a one-shot scenario in which the guarantees on the empirical risk and generalization error are obtained for every encoder's output message.
Minimum Description Length and Generalization Guarantees for Representation Learning
Feb 05, 2024



A major challenge in designing efficient statistical supervised learning algorithms is finding representations that perform well not only on available training samples but also on unseen data. While the study of representation learning has spurred much interest, most existing such approaches are heuristic; and very little is known about theoretical generalization guarantees. In this paper, we establish a compressibility framework that allows us to derive upper bounds on the generalization error of a representation learning algorithm in terms of the "Minimum Description Length" (MDL) of the labels or the latent variables (representations). Rather than the mutual information between the encoder's input and the representation, which is often believed to reflect the algorithm's generalization capability in the related literature but in fact, falls short of doing so, our new bounds involve the "multi-letter" relative entropy between the distribution of the representations (or labels) of the training and test sets and a fixed prior. In particular, these new bounds reflect the structure of the encoder and are not vacuous for deterministic algorithms. Our compressibility approach, which is information-theoretic in nature, builds upon that of Blum-Langford for PAC-MDL bounds and introduces two essential ingredients: block-coding and lossy-compression. The latter allows our approach to subsume the so-called geometrical compressibility as a special case. To the best knowledge of the authors, the established generalization bounds are the first of their kind for Information Bottleneck (IB) type encoders and representation learning. Finally, we partly exploit the theoretical results by introducing a new data-dependent prior. Numerical simulations illustrate the advantages of well-chosen such priors over classical priors used in IB.
Exchanging Keys with Authentication and Identity Protection for Secure Voice Communication without Side-channel
Nov 14, 2022


Motivated by an increasing need for privacy-preserving voice communications, we investigate here the original idea of sending encrypted data and speech in the form of pseudo-speech signals in the audio domain. Being less constrained than military ``Crypto Phones'' and allowing genuine public evaluation, this approach is quite promising for public unsecured voice communication infrastructures, such as 3G cellular network and VoIP.A cornerstone of secure voice communications is the authenticated exchange of cryptographic keys with sole resource the voice channel, and neither Public Key Infrastructure (PKI) nor Certificate Authority (CA). In this paper, we detail our new robust double authentication mechanism based on signatures and Short Authentication Strings (SAS) ensuring strong authentication between the users while mitigating errors caused by unreliable voice channels and also identity protection against passive eavesdroppers. As symbolic model, our protocol has been formally proof-checked for security and fully validated by Tamarin Prover.