 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models
Apr 20, 2022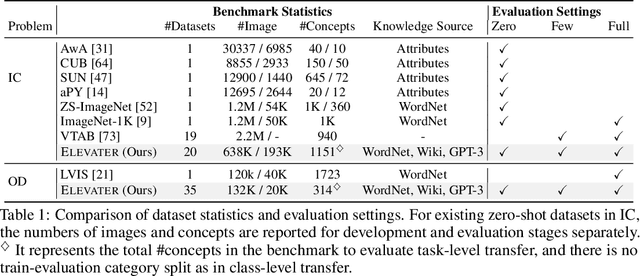

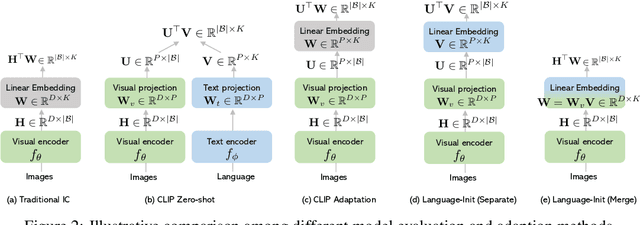
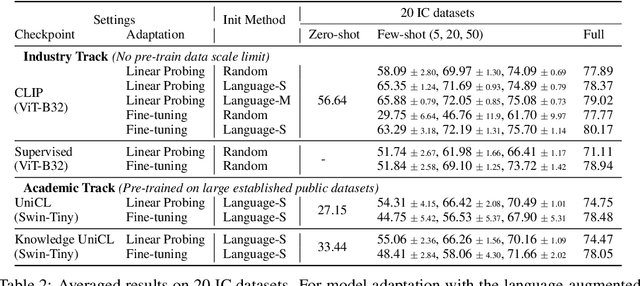
Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains a challenge to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will release our toolkit and evaluation platforms for the research community.