 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOSENet: A Joint Stream Embedding Network for Violence Detection in Surveillance Videos
May 05, 2024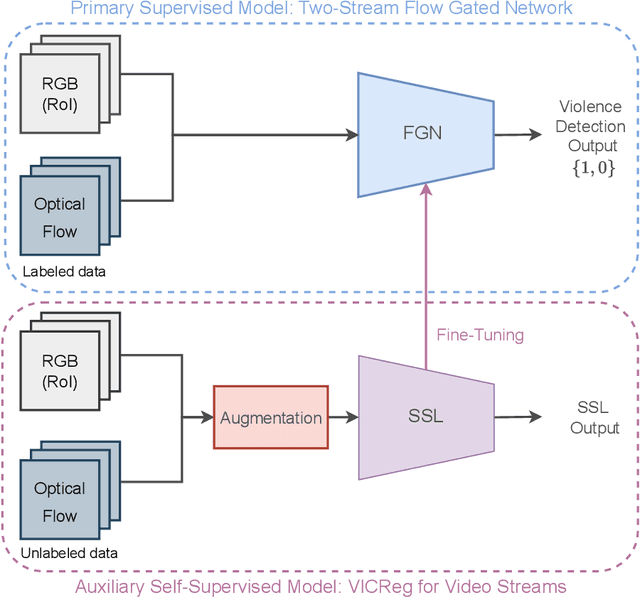
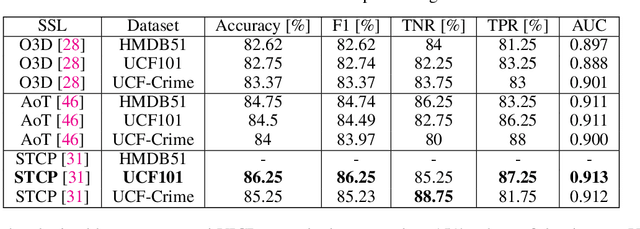
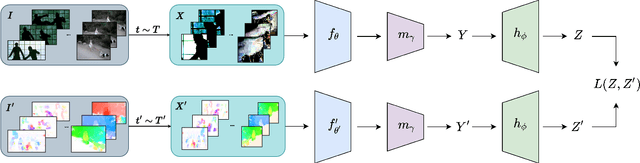
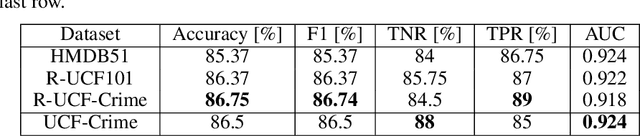
Due to the ever-increasing availability of video surveillance cameras and the growing need for crime prevention, the violence detection task is attracting greater attention from the research community. With respect to other action recognition tasks, violence detection in surveillance videos shows additional issues, such as the presence of a significant variety of real fight scenes. Unfortunately, available datasets seem to be very small compared with other action recognition datasets. Moreover, in surveillance applications, people in the scenes always differ for each video and the background of the footage differs for each camera. Also, violent actions in real-life surveillance videos must be detected quickly to prevent unwanted consequences, thus models would definitely benefit from a reduction in memory usage and computational costs. Such problems make classical action recognition methods difficult to be adopted. To tackle all these issues, we introduce JOSENet, a novel self-supervised framework that provides outstanding performance for violence detection in surveillance videos. The proposed model receives two spatiotemporal video streams, i.e., RGB frames and optical flows, and involves a new regularized self-supervised learning approach for videos. JOSENet provides improved performance compared to self-supervised state-of-the-art methods, while requiring one-fourth of the number of frames per video segment and a reduced frame rate. The source code and the instructions to reproduce our experiments are available at https://github.com/ispamm/JOSENet.
Generative-based Airway and Vessel Morphology Quantification on Chest CT Images
Mar 13, 2020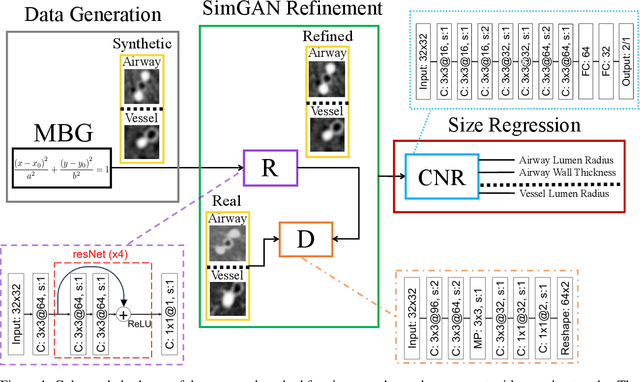

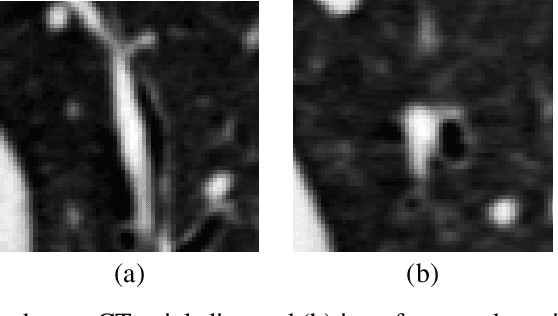
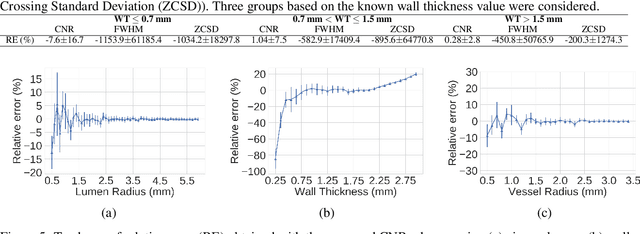
Accurately and precisely characterizing the morphology of small pulmonary structures from Computed Tomography (CT) images, such as airways and vessels, is becoming of great importance for diagnosis of pulmonary diseases. The smaller conducting airways are the major site of increased airflow resistance in chronic obstructive pulmonary disease (COPD), while accurately sizing vessels can help identify arterial and venous changes in lung regions that may determine future disorders. However, traditional methods are often limited due to image resolution and artifacts. We propose a Convolutional Neural Regressor (CNR) that provides cross-sectional measurement of airway lumen, airway wall thickness, and vessel radius. CNR is trained with data created by a generative model of synthetic structures which is used in combination with Simulated and Unsupervised Generative Adversarial Network (SimGAN) to create simulated and refined airways and vessels with known ground-truth. For validation, we first use synthetically generated airways and vessels produced by the proposed generative model to compute the relative error and directly evaluate the accuracy of CNR in comparison with traditional methods. Then, in-vivo validation is performed by analyzing the association between the percentage of the predicted forced expiratory volume in one second (FEV1\%) and the value of the Pi10 parameter, two well-known measures of lung function and airway disease, for airways. For vessels, we assess the correlation between our estimate of the small-vessel blood volume and the lungs' diffusing capacity for carbon monoxide (DLCO). The results demonstrate that Convolutional Neural Networks (CNNs) provide a promising direction for accurately measuring vessels and airways on chest CT images with physiological correlates.