 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOSENet: A Joint Stream Embedding Network for Violence Detection in Surveillance Videos
Paper and Code
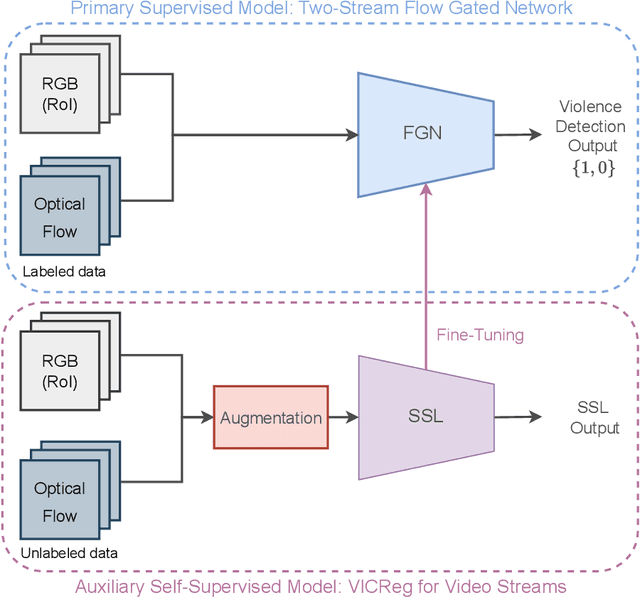
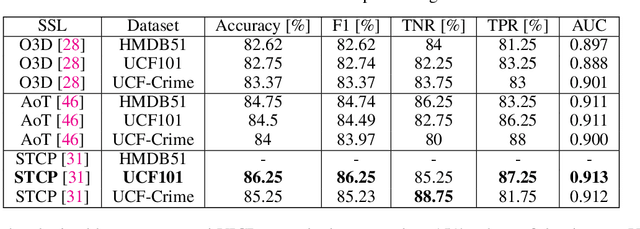
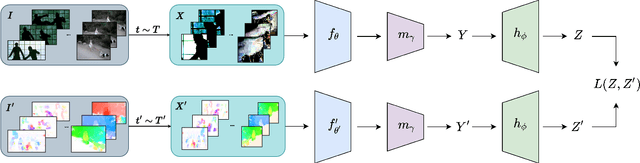
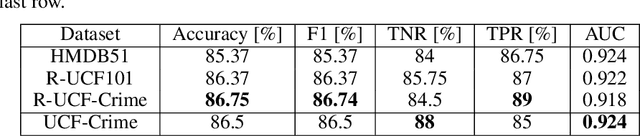
Due to the ever-increasing availability of video surveillance cameras and the growing need for crime prevention, the violence detection task is attracting greater attention from the research community. With respect to other action recognition tasks, violence detection in surveillance videos shows additional issues, such as the presence of a significant variety of real fight scenes. Unfortunately, available datasets seem to be very small compared with other action recognition datasets. Moreover, in surveillance applications, people in the scenes always differ for each video and the background of the footage differs for each camera. Also, violent actions in real-life surveillance videos must be detected quickly to prevent unwanted consequences, thus models would definitely benefit from a reduction in memory usage and computational costs. Such problems make classical action recognition methods difficult to be adopted. To tackle all these issues, we introduce JOSENet, a novel self-supervised framework that provides outstanding performance for violence detection in surveillance videos. The proposed model receives two spatiotemporal video streams, i.e., RGB frames and optical flows, and involves a new regularized self-supervised learning approach for videos. JOSENet provides improved performance compared to self-supervised state-of-the-art methods, while requiring one-fourth of the number of frames per video segment and a reduced frame rate. The source code and the instructions to reproduce our experiments are available at https://github.com/ispamm/JOSENet.