 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit 3D Representations of Dressed Humans from Sparse Views
Apr 16, 2021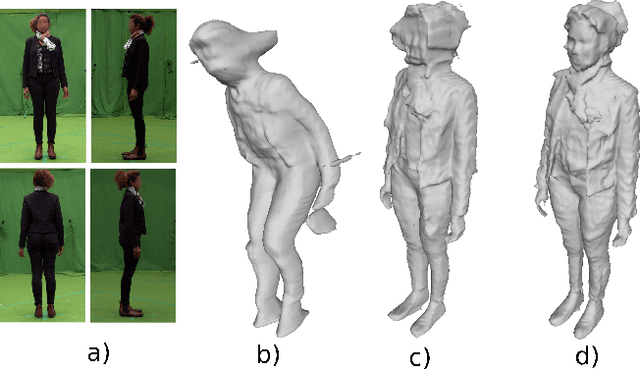
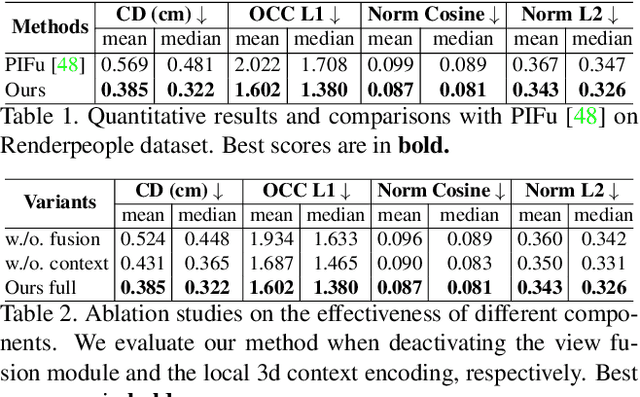
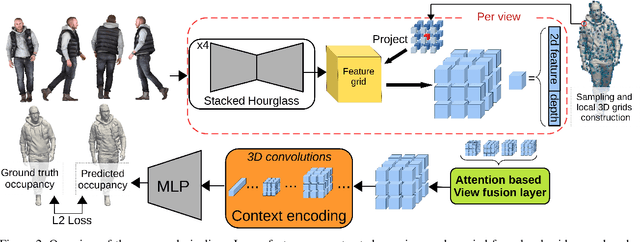
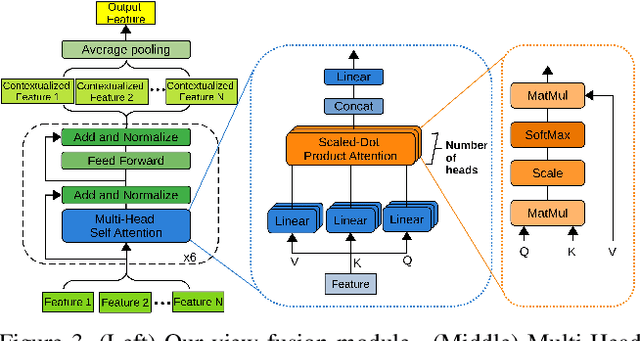
Recently, data-driven single-view reconstruction methods have shown great progress in modeling 3D dressed humans. However, such methods suffer heavily from depth ambiguities and occlusions inherent to single view inputs. In this paper, we address such issues by lifting the single-view input with additional views and investigate the best strategy to suitably exploit information from multiple views. We propose an end-to-end approach that learns an implicit 3D representation of dressed humans from sparse camera views. Specifically, we introduce two key components: first an attention-based fusion layer that learns to aggregate visual information from several viewpoints; second a mechanism that encodes local 3D patterns under the multi-view context. In the experiments, we show the proposed approach outperforms the state of the art on standard data both quantitatively and qualitatively. Additionally, we apply our method on real data acquired with a multi-camera platform and demonstrate our approach can obtain results comparable to multi-view stereo with dramatically less views.