 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin UNETR segmentation with automated geometry filtering for biomechanical modeling of knee joint cartilage
Jul 08, 2024
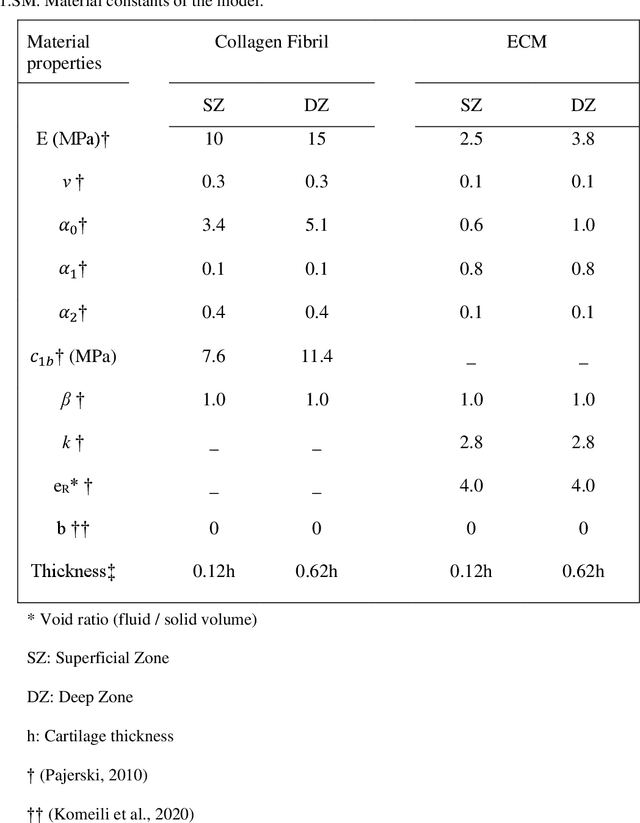
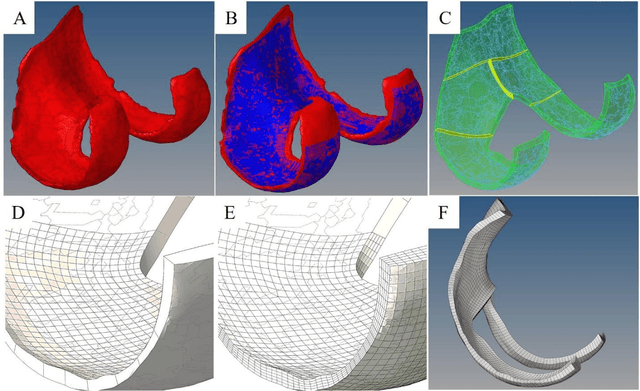
Simulation studies, such as finite element (FE) modeling, offer insights into knee joint biomechanics, which may not be achieved through experimental methods without direct involvement of patients. While generic FE models have been used to predict tissue biomechanics, they overlook variations in population-specific geometry, loading, and material properties. In contrast, subject-specific models account for these factors, delivering enhanced predictive precision but requiring significant effort and time for development. This study aimed to facilitate subject-specific knee joint FE modeling by integrating an automated cartilage segmentation algorithm using a 3D Swin UNETR. This algorithm provided initial segmentation of knee cartilage, followed by automated geometry filtering to refine surface roughness and continuity. In addition to the standard metrics of image segmentation performance, such as Dice similarity coefficient (DSC) and Hausdorff distance, the method's effectiveness was also assessed in FE simulation. Nine pairs of knee cartilage FE models, using manual and automated segmentation methods, were developed to compare the predicted stress and strain responses during gait. The automated segmentation achieved high Dice similarity coefficients of 89.4% for femoral and 85.1% for tibial cartilage, with a Hausdorff distance of 2.3 mm between the automated and manual segmentation. Mechanical results including maximum principal stress and strain, fluid pressure, fibril strain, and contact area showed no significant differences between the manual and automated FE models. These findings demonstrate the effectiveness of the proposed automated segmentation method in creating accurate knee joint FE models.
Automatic Classification of Symmetry of Hemithoraces in Canine and Feline Radiographs
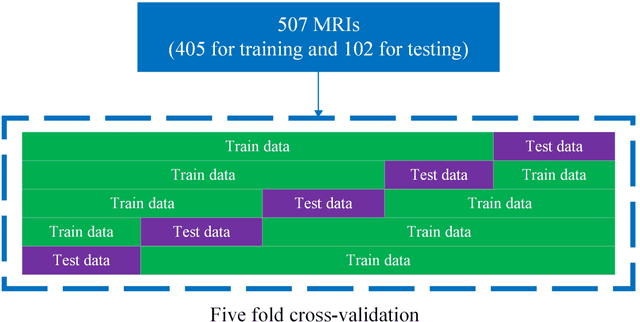
Feb 24, 2023Purpose: Thoracic radiographs are commonly used to evaluate patients with confirmed or suspected thoracic pathology. Proper patient positioning is more challenging in canine and feline radiography than in humans due to less patient cooperation and body shape variation. Improper patient positioning during radiograph acquisition has the potential to lead to a misdiagnosis. Asymmetrical hemithoraces are one of the indications of obliquity for which we propose an automatic classification method. Approach: We propose a hemithoraces segmentation method based on Convolutional Neural Networks (CNNs) and active contours. We utilized the U-Net model to segment the ribs and spine and then utilized active contours to find left and right hemithoraces. We then extracted features from the left and right hemithoraces to train an ensemble classifier which includes Support Vector Machine, Gradient Boosting and Multi-Layer Perceptron. Five-fold cross-validation was used, thorax segmentation was evaluated by Intersection over Union (IoU), and symmetry classification was evaluated using Precision, Recall, Area under Curve and F1 score. Results: Classification of symmetry for 900 radiographs reported an F1 score of 82.8% . To test the robustness of the proposed thorax segmentation method to underexposure and overexposure, we synthetically corrupted properly exposed radiographs and evaluated results using IoU. The results showed that the models IoU for underexposure and overexposure dropped by 2.1% and 1.2%, respectively. Conclusions: Our results indicate that the proposed thorax segmentation method is robust to poor exposure radiographs. The proposed thorax segmentation method can be applied to human radiography with minimal changes.
Analysis of Macula on Color Fundus Images Using Heightmap Reconstruction Through Deep Learning
Dec 28, 2020


For medical diagnosis based on retinal images, a clear understanding of 3D structure is often required but due to the 2D nature of images captured, we cannot infer that information. However, by utilizing 3D reconstruction methods, we can recover the height information of the macula area on a fundus image which can be helpful for diagnosis and screening of macular disorders. Recent approaches have used shading information for heightmap prediction but their output was not accurate since they ignored the dependency between nearby pixels and only utilized shading information. Additionally, other methods were dependent on the availability of more than one image of the retina which is not available in practice. In this paper, motivated by the success of Conditional Generative Adversarial Networks(cGANs) and deeply supervised networks, we propose a novel architecture for the generator which enhances the details and the quality of output by progressive refinement and the use of deep supervision to reconstruct the height information of macula on a color fundus image. Comparisons on our own dataset illustrate that the proposed method outperforms all of the state-of-the-art methods in image translation and medical image translation on this particular task. Additionally, perceptual studies also indicate that the proposed method can provide additional information for ophthalmologists for diagnosis.
Deformable Convolutional LSTM for Human Body Emotion Recognition
Oct 27, 2020



People represent their emotions in a myriad of ways. Among the most important ones is whole body expressions which have many applications in different fields such as human-computer interaction (HCI). One of the most important challenges in human emotion recognition is that people express the same feeling in various ways using their face and their body. Recently many methods have tried to overcome these challenges using Deep Neural Networks (DNNs). However, most of these methods were based on images or on facial expressions only and did not consider deformation that may happen in the images such as scaling and rotation which can adversely affect the recognition accuracy. In this work, motivated by recent researches on deformable convolutions, we incorporate the deformable behavior into the core of convolutional long short-term memory (ConvLSTM) to improve robustness to these deformations in the image and, consequently, improve its accuracy on the emotion recognition task from videos of arbitrary length. We did experiments on the GEMEP dataset and achieved state-of-the-art accuracy of 98.8% on the task of whole human body emotion recognition on the validation set.
Heightmap Reconstruction of Macula on Color Fundus Images Using Conditional Generative Adversarial Networks
Sep 05, 2020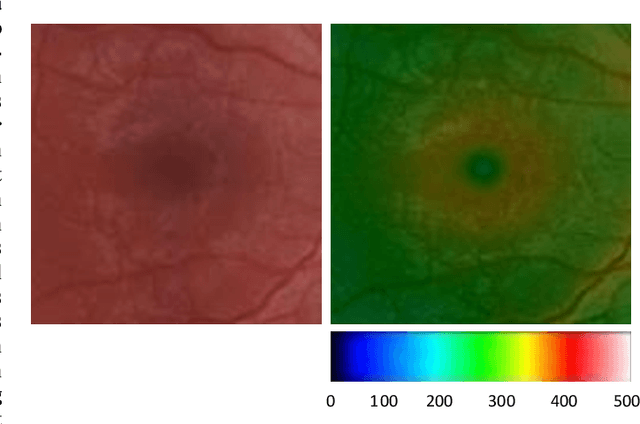
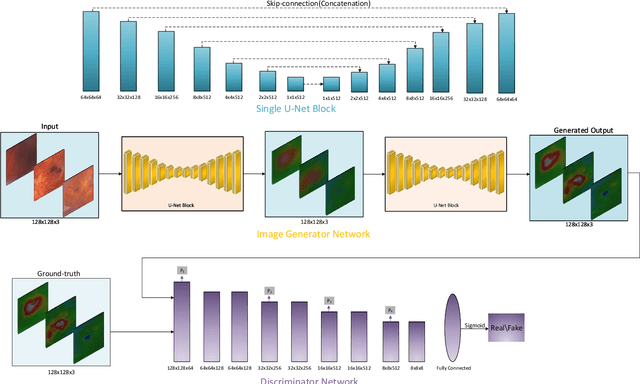


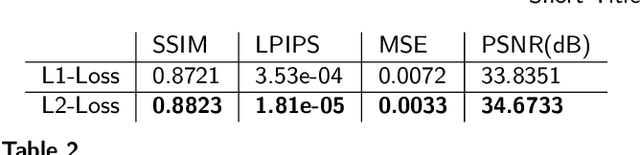
For medical diagnosis based on retinal images, a clear understanding of 3D structure is often required but due to the 2D nature of images captured, we cannot infer that information. However, by utilizing 3D reconstruction methods, we can construct the 3D structure of the macula area on fundus images which can be helpful for diagnosis and screening of macular disorders. Recent approaches have used shading information for 3D reconstruction or heightmap prediction but their output was not accurate since they ignored the dependency between nearby pixels. Additionally, other methods were dependent on the availability of more than one image of the eye which is not available in practice. In this paper, we use conditional generative adversarial networks (cGANs) to generate images that contain height information of the macula area on a fundus image. Results using our dataset show a 0.6077 improvement in Structural Similarity Index (SSIM) and 0.071 improvements in Mean Squared Error (MSE) metric over Shape from Shading (SFS) method. Additionally, Qualitative studies also indicate that our method outperforms recent approaches.