 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory and Information Processing in Recurrent Neural Networks
Apr 23, 2016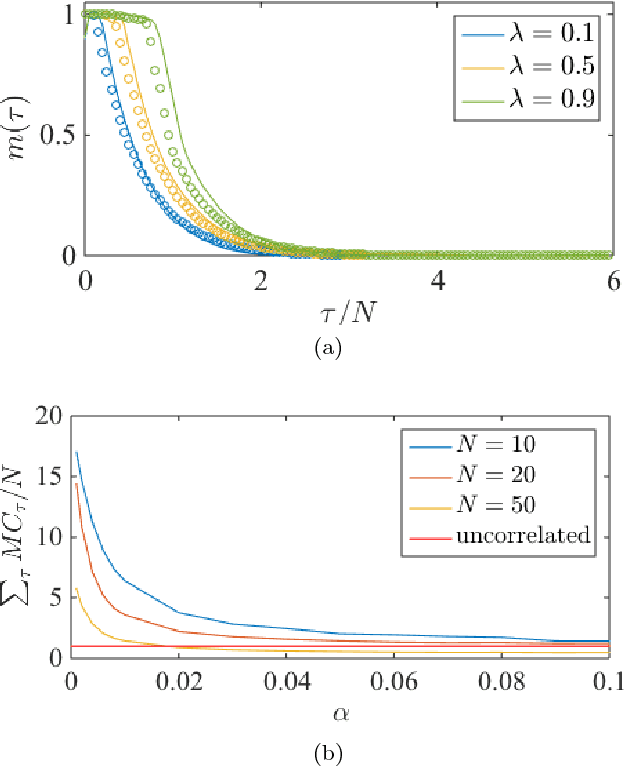
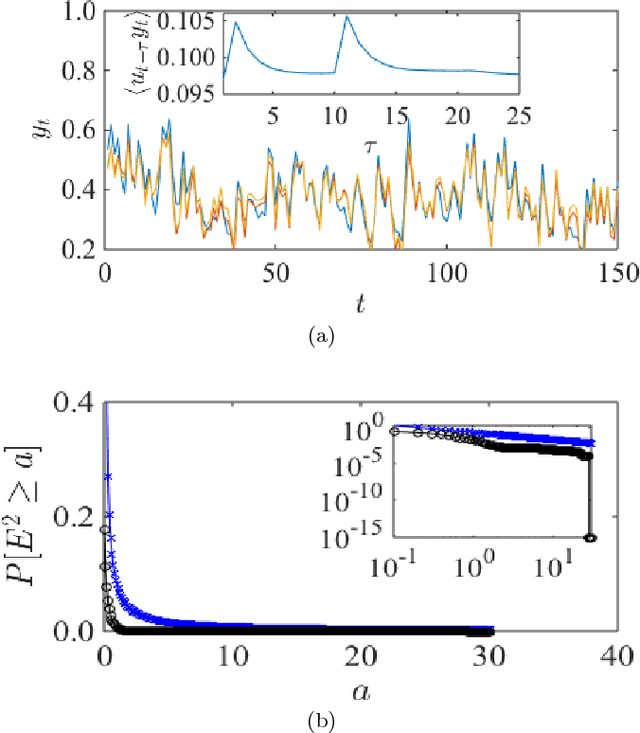
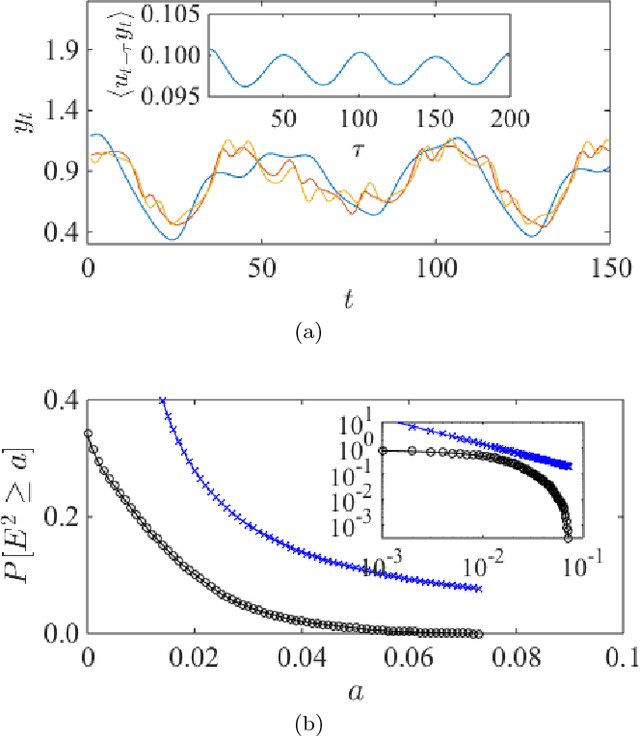
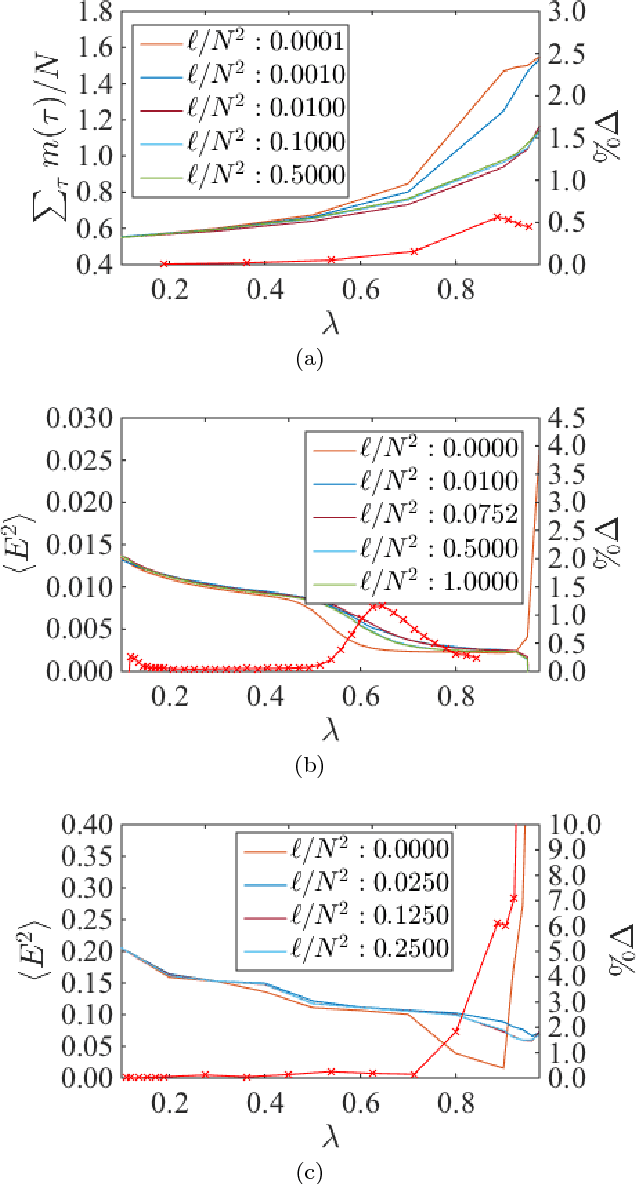
Recurrent neural networks (RNN) are simple dynamical systems whose computational power has been attributed to their short-term memory. Short-term memory of RNNs has been previously studied analytically only for the case of orthogonal networks, and only under annealed approximation, and uncorrelated input. Here for the first time, we present an exact solution to the memory capacity and the task-solving performance as a function of the structure of a given network instance, enabling direct determination of the function--structure relation in RNNs. We calculate the memory capacity for arbitrary networks with exponentially correlated input and further related it to the performance of the system on signal processing tasks in a supervised learning setup. We compute the expected error and the worst-case error bound as a function of the spectra of the network and the correlation structure of its inputs and outputs. Our results give an explanation for learning and generalization of task solving using short-term memory, which is crucial for building alternative computer architectures using physical phenomena based on the short-term memory principle.
Learning Two-input Linear and Nonlinear Analog Functions with a Simple Chemical System
Jul 13, 2014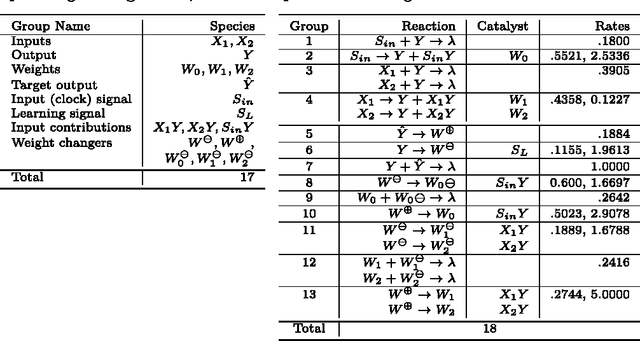
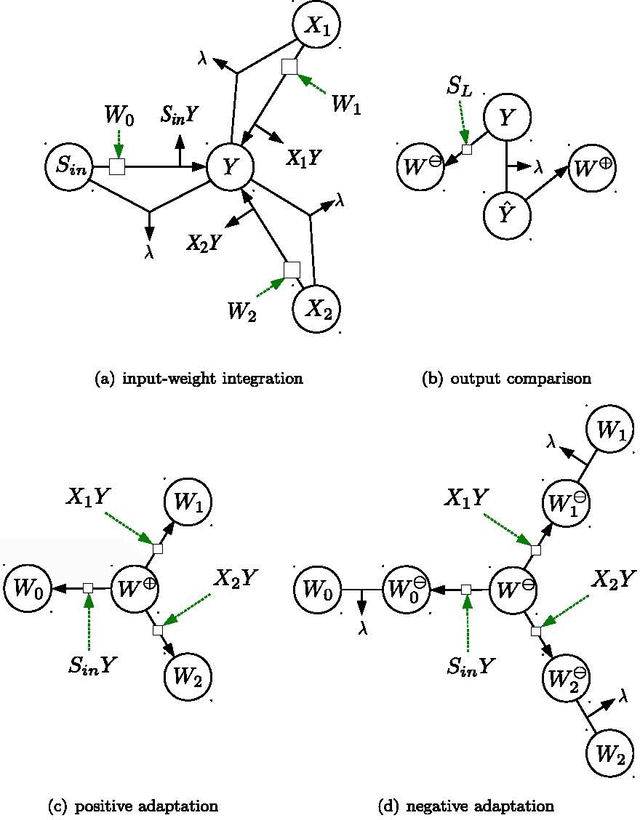
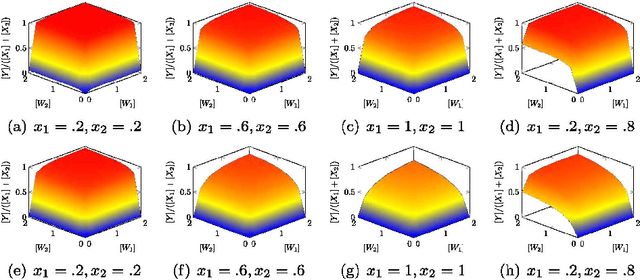
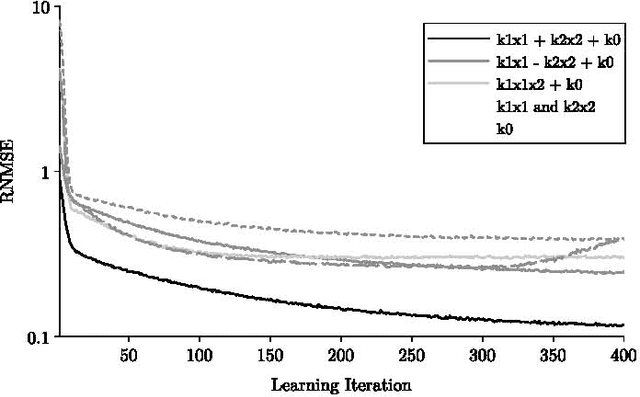
The current biochemical information processing systems behave in a predetermined manner because all features are defined during the design phase. To make such unconventional computing systems reusable and programmable for biomedical applications, adaptation, learning, and self-modification based on external stimuli would be highly desirable. However, so far, it has been too challenging to implement these in wet chemistries. In this paper we extend the chemical perceptron, a model previously proposed by the authors, to function as an analog instead of a binary system. The new analog asymmetric signal perceptron learns through feedback and supports Michaelis-Menten kinetics. The results show that our perceptron is able to learn linear and nonlinear (quadratic) functions of two inputs. To the best of our knowledge, it is the first simulated chemical system capable of doing so. The small number of species and reactions and their simplicity allows for a mapping to an actual wet implementation using DNA-strand displacement or deoxyribozymes. Our results are an important step toward actual biochemical systems that can learn and adapt.
* 13 pages, 4 figures, 2 tables
A Comparative Study of Reservoir Computing for Temporal Signal Processing
Jan 10, 2014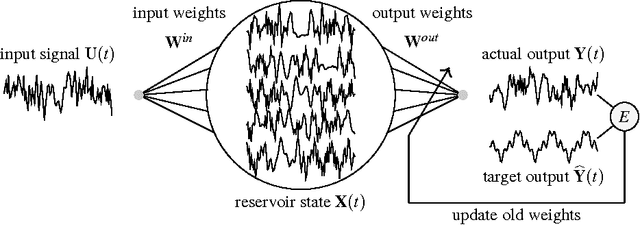
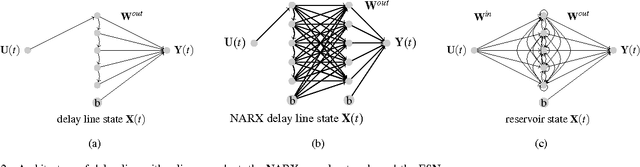
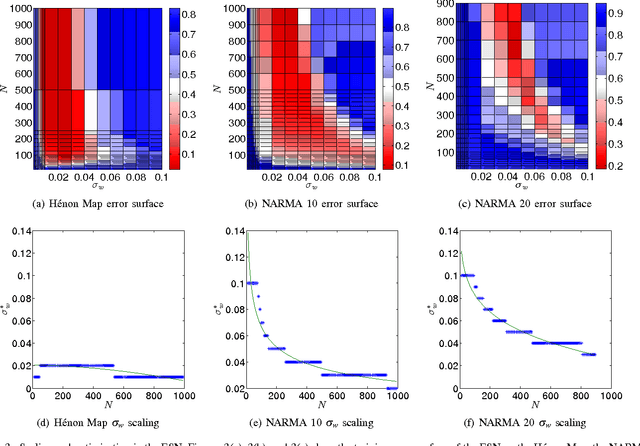
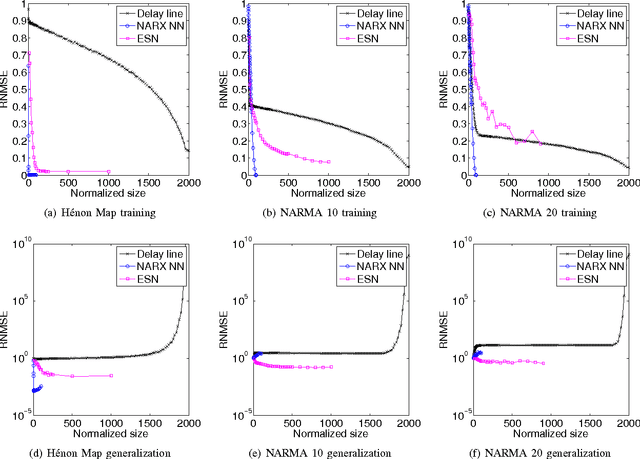
Reservoir computing (RC) is a novel approach to time series prediction using recurrent neural networks. In RC, an input signal perturbs the intrinsic dynamics of a medium called a reservoir. A readout layer is then trained to reconstruct a target output from the reservoir's state. The multitude of RC architectures and evaluation metrics poses a challenge to both practitioners and theorists who study the task-solving performance and computational power of RC. In addition, in contrast to traditional computation models, the reservoir is a dynamical system in which computation and memory are inseparable, and therefore hard to analyze. Here, we compare echo state networks (ESN), a popular RC architecture, with tapped-delay lines (DL) and nonlinear autoregressive exogenous (NARX) networks, which we use to model systems with limited computation and limited memory respectively. We compare the performance of the three systems while computing three common benchmark time series: H{\'e}non Map, NARMA10, and NARMA20. We find that the role of the reservoir in the reservoir computing paradigm goes beyond providing a memory of the past inputs. The DL and the NARX network have higher memorization capability, but fall short of the generalization power of the ESN.