 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNN2CAM: Automated Neural Network Mapping for Multi-Precision Edge Processing on FPGA-Based Cameras
Jun 24, 2021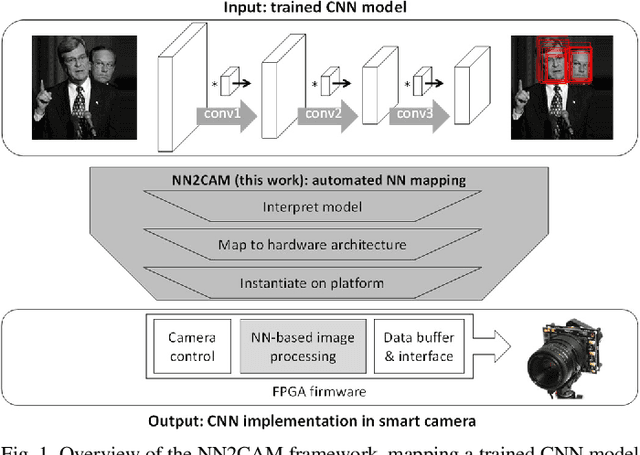
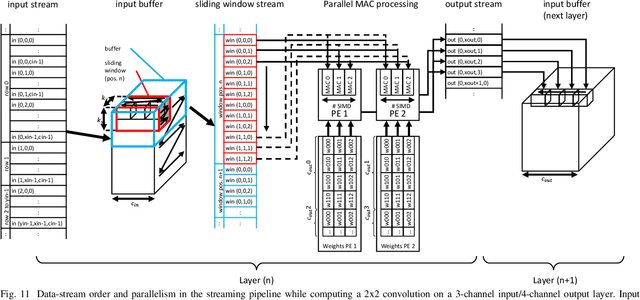

The record-breaking achievements of deep neural networks (DNNs) in image classification and detection tasks resulted in a surge of new computer vision applications during the past years. However, their computational complexity is restricting their deployment to powerful stationary or complex dedicated processing hardware, limiting their use in smart edge processing applications. We propose an automated deployment framework for DNN acceleration at the edge on field-programmable gate array (FPGA)-based cameras. The framework automatically converts an arbitrary-sized and quantized trained network into an efficient streaming-processing IP block that is instantiated within a generic adapter block in the FPGA. In contrast to prior work, the accelerator is purely logic and thus supports end-to-end processing on FPGAs without on-chip microprocessors. Our mapping tool features automatic translation from a trained Caffe network, arbitrary layer-wise fixed-point precision for both weights and activations, an efficient XNOR implementation for fully binary layers as well as a balancing mechanism for effective allocation of computational resources in the streaming dataflow. To present the performance of the system we employ this tool to implement two CNN edge processing networks on an FPGA-based high-speed camera with various precision settings showing computational throughputs of up to 337GOPS in low-latency streaming mode (no batching), running entirely on the camera.
A Construction Kit for Efficient Low Power Neural Network Accelerator Designs
Jun 24, 2021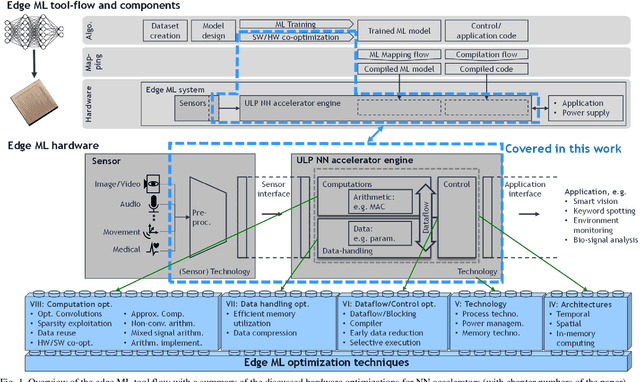
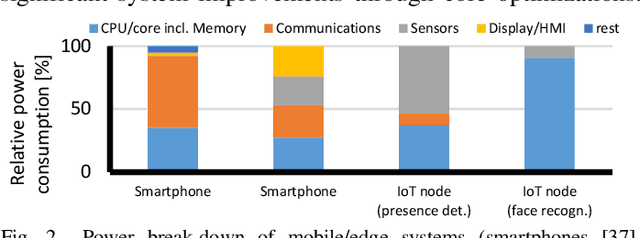
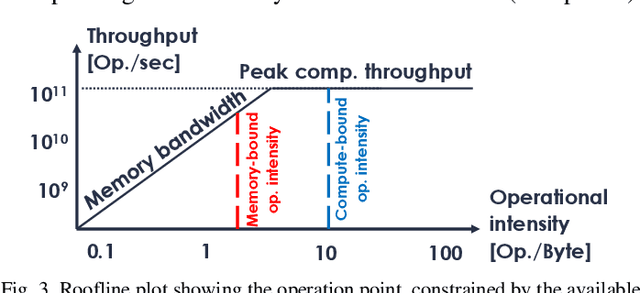
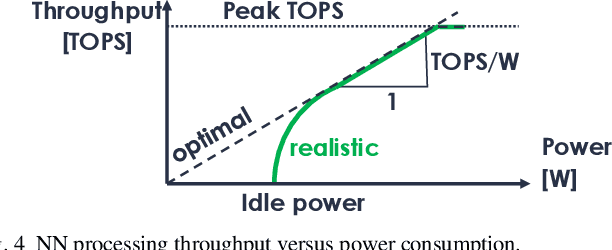
Implementing embedded neural network processing at the edge requires efficient hardware acceleration that couples high computational performance with low power consumption. Driven by the rapid evolution of network architectures and their algorithmic features, accelerator designs are constantly updated and improved. To evaluate and compare hardware design choices, designers can refer to a myriad of accelerator implementations in the literature. Surveys provide an overview of these works but are often limited to system-level and benchmark-specific performance metrics, making it difficult to quantitatively compare the individual effect of each utilized optimization technique. This complicates the evaluation of optimizations for new accelerator designs, slowing-down the research progress. This work provides a survey of neural network accelerator optimization approaches that have been used in recent works and reports their individual effects on edge processing performance. It presents the list of optimizations and their quantitative effects as a construction kit, allowing to assess the design choices for each building block separately. Reported optimizations range from up to 10'000x memory savings to 33x energy reductions, providing chip designers an overview of design choices for implementing efficient low power neural network accelerators.
Improving Memory Utilization in Convolutional Neural Network Accelerators
Jul 20, 2020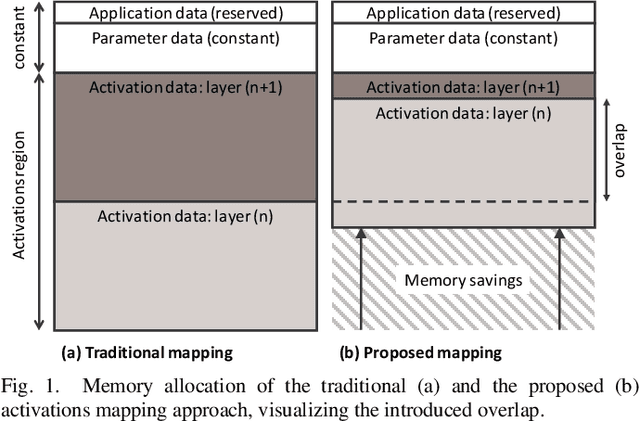
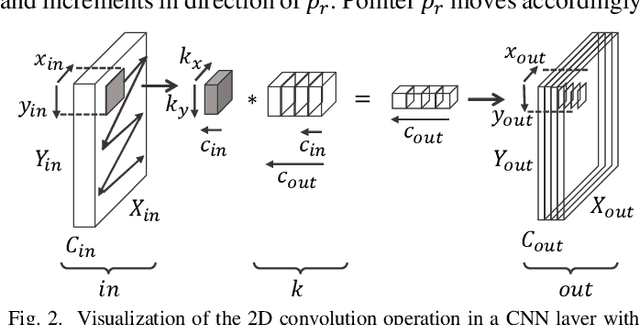
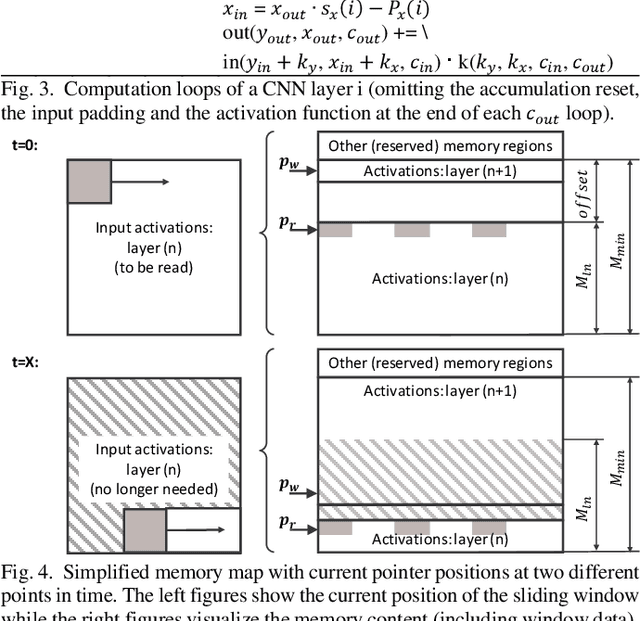
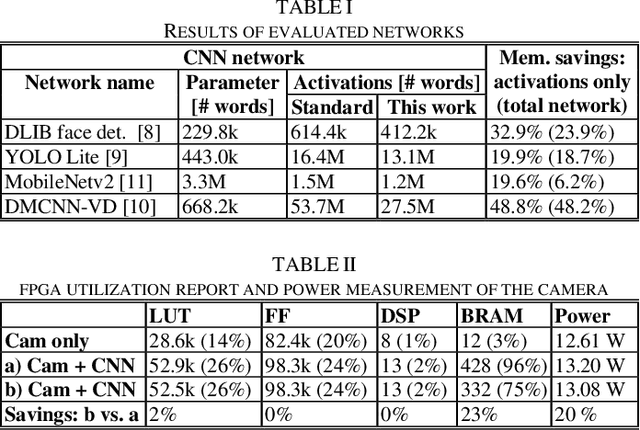
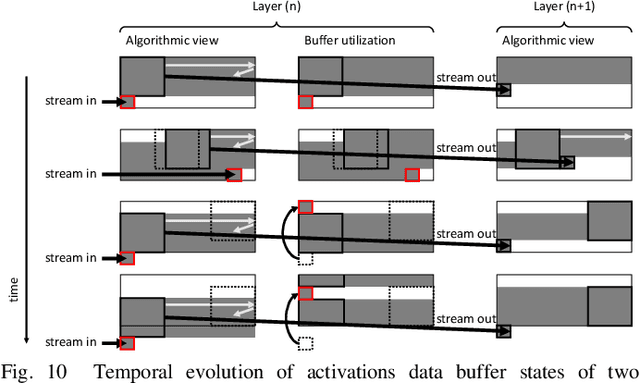
While the accuracy of convolutional neural networks has achieved vast improvements by introducing larger and deeper network architectures, also the memory footprint for storing their parameters and activations has increased. This trend especially challenges power- and resource-limited accelerator designs, which are often restricted to store all network data in on-chip memory to avoid interfacing energy-hungry external memories. Maximizing the network size that fits on a given accelerator thus requires to maximize its memory utilization. While the traditionally used ping-pong buffering technique is mapping subsequent activation layers to disjunctive memory regions, we propose a mapping method that allows these regions to overlap and thus utilize the memory more efficiently. This work presents the mathematical model to compute the maximum activations memory overlap and thus the lower bound of on-chip memory needed to perform layer-by-layer processing of convolutional neural networks on memory-limited accelerators. Our experiments with various real-world object detector networks show that the proposed mapping technique can decrease the activations memory by up to 32.9%, reducing the overall memory for the entire network by up to 23.9% compared to traditional ping-pong buffering. For higher resolution de-noising networks, we achieve activation memory savings of 48.8%. Additionally, we implement a face detector network on an FPGA-based camera to validate these memory savings on a complete end-to-end system.