 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNN2CAM: Automated Neural Network Mapping for Multi-Precision Edge Processing on FPGA-Based Cameras
Paper and Code
Jun 24, 2021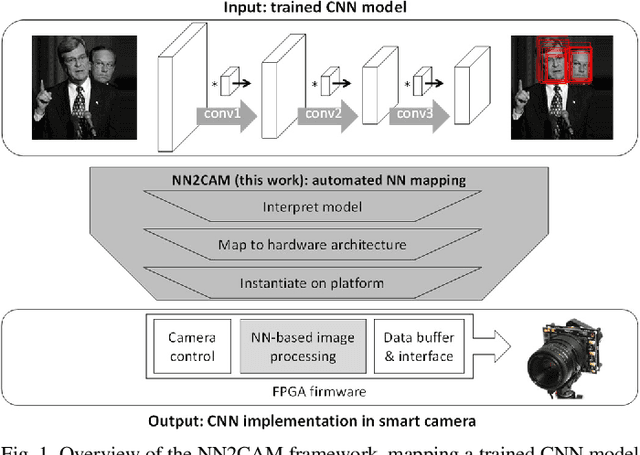
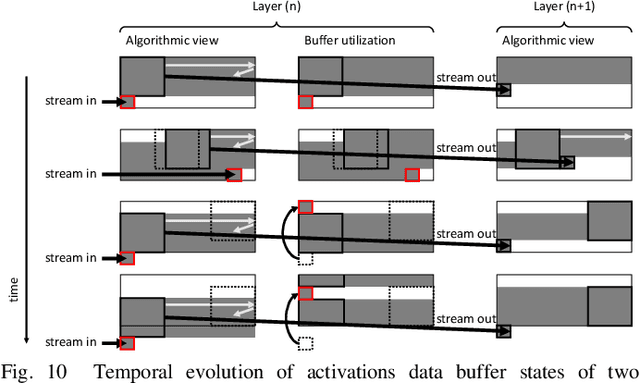
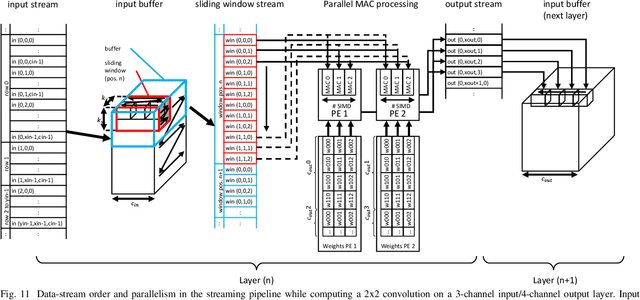

The record-breaking achievements of deep neural networks (DNNs) in image classification and detection tasks resulted in a surge of new computer vision applications during the past years. However, their computational complexity is restricting their deployment to powerful stationary or complex dedicated processing hardware, limiting their use in smart edge processing applications. We propose an automated deployment framework for DNN acceleration at the edge on field-programmable gate array (FPGA)-based cameras. The framework automatically converts an arbitrary-sized and quantized trained network into an efficient streaming-processing IP block that is instantiated within a generic adapter block in the FPGA. In contrast to prior work, the accelerator is purely logic and thus supports end-to-end processing on FPGAs without on-chip microprocessors. Our mapping tool features automatic translation from a trained Caffe network, arbitrary layer-wise fixed-point precision for both weights and activations, an efficient XNOR implementation for fully binary layers as well as a balancing mechanism for effective allocation of computational resources in the streaming dataflow. To present the performance of the system we employ this tool to implement two CNN edge processing networks on an FPGA-based high-speed camera with various precision settings showing computational throughputs of up to 337GOPS in low-latency streaming mode (no batching), running entirely on the camera.