 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning and Learning a Perceptual Metric for Self-Training of Reflective Objects in Bin-Picking with a Low-cost Camera
Mar 26, 2025Bin-picking of metal objects using low-cost RGB-D cameras often suffers from sparse depth information and reflective surface textures, leading to errors and the need for manual labeling. To reduce human intervention, we propose a two-stage framework consisting of a metric learning stage and a self-training stage. Specifically, to automatically process data captured by a low-cost camera (LC), we introduce a Multi-object Pose Reasoning (MoPR) algorithm that optimizes pose hypotheses under depth, collision, and boundary constraints. To further refine pose candidates, we adopt a Symmetry-aware Lie-group based Bayesian Gaussian Mixture Model (SaL-BGMM), integrated with the Expectation-Maximization (EM) algorithm, for symmetry-aware filtering. Additionally, we propose a Weighted Ranking Information Noise Contrastive Estimation (WR-InfoNCE) loss to enable the LC to learn a perceptual metric from reconstructed data, supporting self-training on untrained or even unseen objects. Experimental results show that our approach outperforms several state-of-the-art methods on both the ROBI dataset and our newly introduced Self-ROBI dataset.
PointNet++ Grasping: Learning An End-to-end Spatial Grasp Generation Algorithm from Sparse Point Clouds
Mar 21, 2020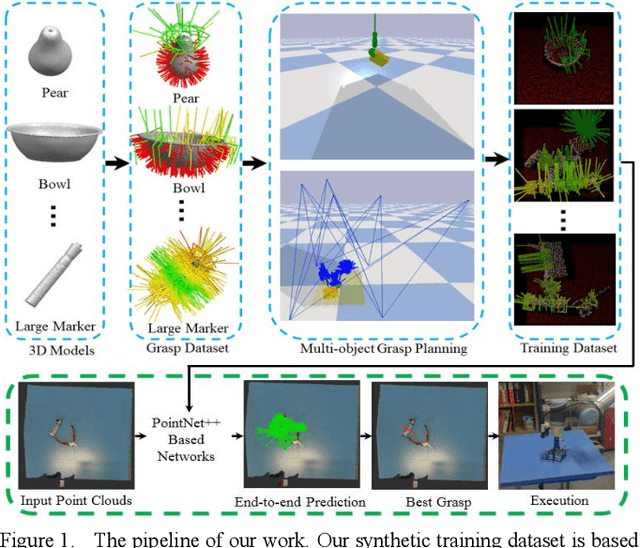
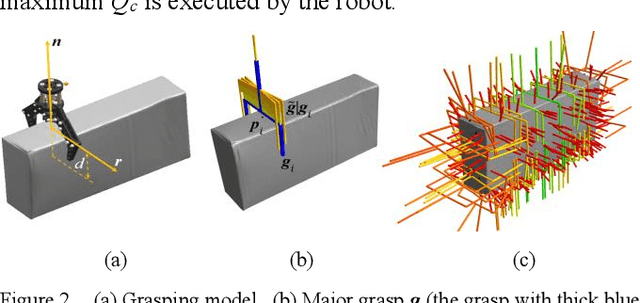
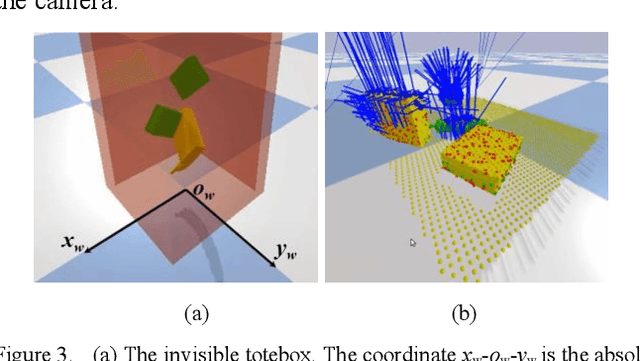
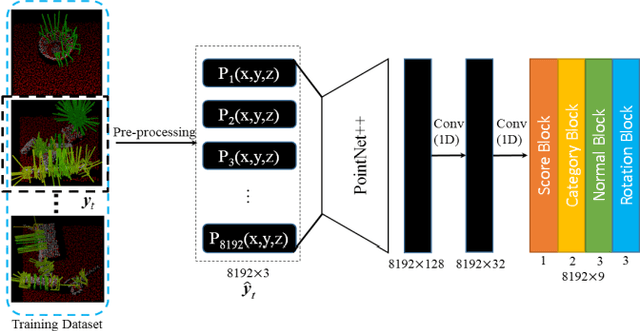
Grasping for novel objects is important for robot manipulation in unstructured environments. Most of current works require a grasp sampling process to obtain grasp candidates, combined with local feature extractor using deep learning. This pipeline is time-costly, expecially when grasp points are sparse such as at the edge of a bowl. In this paper, we propose an end-to-end approach to directly predict the poses, categories and scores (qualities) of all the grasps. It takes the whole sparse point clouds as the input and requires no sampling or search process. Moreover, to generate training data of multi-object scene, we propose a fast multi-object grasp detection algorithm based on Ferrari Canny metrics. A single-object dataset (79 objects from YCB object set, 23.7k grasps) and a multi-object dataset (20k point clouds with annotations and masks) are generated. A PointNet++ based network combined with multi-mask loss is introduced to deal with different training points. The whole weight size of our network is only about 11.6M, which takes about 102ms for a whole prediction process using a GeForce 840M GPU. Our experiment shows our work get 71.43% success rate and 91.60% completion rate, which performs better than current state-of-art works.