 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat does a network layer hear? Analyzing hidden representations of end-to-end ASR through speech synthesis
Nov 04, 2019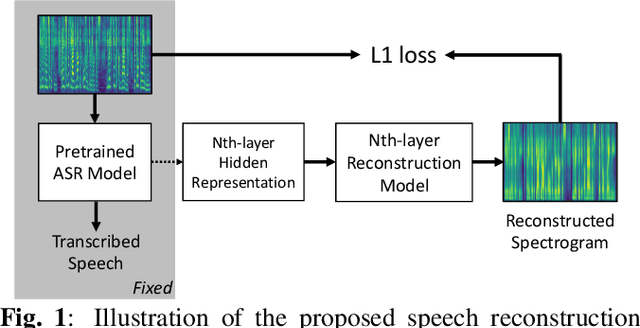
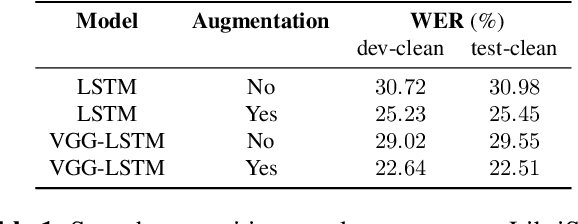
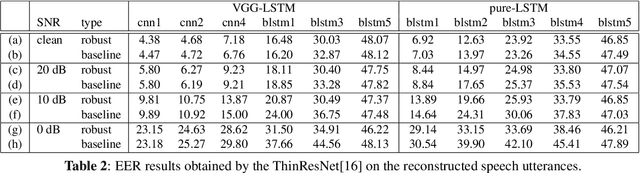
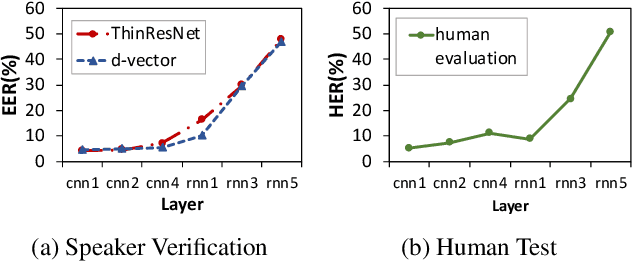
End-to-end speech recognition systems have achieved competitive results compared to traditional systems. However, the complex transformations involved between layers given highly variable acoustic signals are hard to analyze. In this paper, we present our ASR probing model, which synthesizes speech from hidden representations of end-to-end ASR to examine the information maintain after each layer calculation. Listening to the synthesized speech, we observe gradual removal of speaker variability and noise as the layer goes deeper, which aligns with the previous studies on how deep network functions in speech recognition. This paper is the first study analyzing the end-to-end speech recognition model by demonstrating what each layer hears. Speaker verification and speech enhancement measurements on synthesized speech are also conducted to confirm our observation further.
Dynamically Context-Sensitive Time-Decay Attention for Dialogue Modeling
Nov 01, 2018
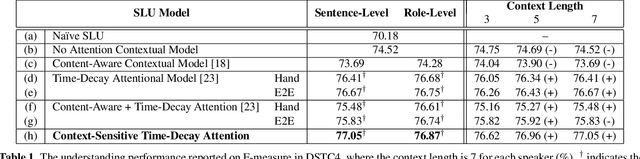
Spoken language understanding (SLU) is an essential component in conversational systems. Considering that contexts provide informative cues for better understanding, history can be leveraged for contextual SLU. However, most prior work only paid attention to the related content in history utterances and ignored the temporal information. In dialogues, it is intuitive that the most recent utterances are more important than the least recent ones, and time-aware attention should be in a decaying manner. Therefore, this paper allows the model to automatically learn a time-decay attention function where the attentional weights can be dynamically decided based on the content of each role's contexts, which effectively integrates both content-aware and time-aware perspectives and demonstrates remarkable flexibility to complex dialogue contexts. The experiments on the benchmark Dialogue State Tracking Challenge (DSTC4) dataset show that the proposed dynamically context-sensitive time-decay attention mechanisms significantly improve the state-of-the-art model for contextual understanding performance.