 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional relevance based on the continuous Shapley value
Nov 27, 2024



The presence of Artificial Intelligence (AI) in our society is increasing, which brings with it the need to understand the behaviour of AI mechanisms, including machine learning predictive algorithms fed with tabular data, text, or images, among other types of data. This work focuses on interpretability of predictive models based on functional data. Designing interpretability methods for functional data models implies working with a set of features whose size is infinite. In the context of scalar on function regression, we propose an interpretability method based on the Shapley value for continuous games, a mathematical formulation that allows to fairly distribute a global payoff among a continuous set players. The method is illustrated through a set of experiments with simulated and real data sets. The open source Python package ShapleyFDA is also presented.
SurvLIMEpy: A Python package implementing SurvLIME
Feb 21, 2023In this paper we present SurvLIMEpy, an open-source Python package that implements the SurvLIME algorithm. This method allows to compute local feature importance for machine learning algorithms designed for modelling Survival Analysis data. Our implementation takes advantage of the parallelisation paradigm as all computations are performed in a matrix-wise fashion which speeds up execution time. Additionally, SurvLIMEpy assists the user with visualization tools to better understand the result of the algorithm. The package supports a wide variety of survival models, from the Cox Proportional Hazards Model to deep learning models such as DeepHit or DeepSurv. Two types of experiments are presented in this paper. First, by means of simulated data, we study the ability of the algorithm to capture the importance of the features. Second, we use three open source survival datasets together with a set of survival algorithms in order to demonstrate how SurvLIMEpy behaves when applied to different models.
Understanding complex predictive models with Ghost Variables
Dec 13, 2019
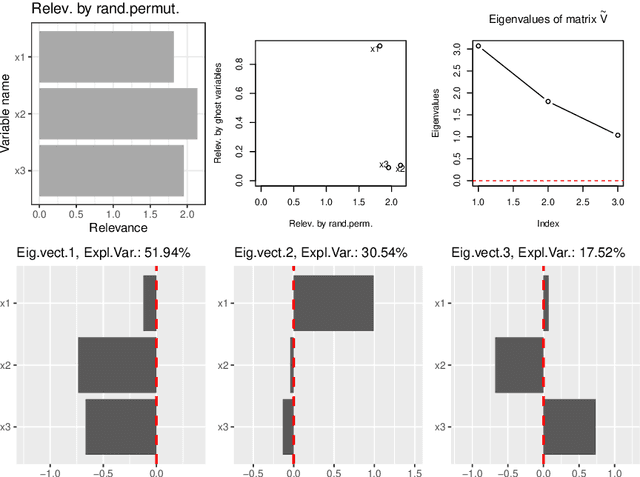


We propose a procedure for assigning a relevance measure to each explanatory variable in a complex predictive model. We assume that we have a training set to fit the model and a test set to check the out of sample performance. First, the individual relevance of each variable is computed by comparing the predictions in the test set, given by the model that includes all the variables with those of another model in which the variable of interest is substituted by its ghost variable, defined as the prediction of this variable by using the rest of explanatory variables. Second, we check the joint effects among the variables by using the eigenvalues of a relevance matrix that is the covariance matrix of the vectors of individual effects. It is shown that in simple models, as linear or additive models, the proposed measures are related to standard measures of significance of the variables and in neural networks models (and in other algorithmic prediction models) the procedure provides information about the joint and individual effects of the variables that is not usually available by other methods. The procedure is illustrated with simulated examples and the analysis of a large real data set.