 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Key Challenges of Hardness-Based Resampling
Apr 09, 2025Performance gap across classes remains a persistent challenge in machine learning, often attributed to variations in class hardness. One way to quantify class hardness is through sample complexity - the minimum number of samples required to effectively learn a given class. Sample complexity theory suggests that class hardness is driven by differences in the amount of data required for generalization. That is, harder classes need substantially more samples to achieve generalization. Therefore, hardness-based resampling is a promising approach to mitigate these performance disparities. While resampling has been studied extensively in data-imbalanced settings, its impact on balanced datasets remains unexplored. This raises the fundamental question whether resampling is effective because it addresses data imbalance or hardness imbalance. We begin addressing this question by introducing class imbalance into balanced datasets and evaluate its effect on performance disparities. We oversample hard classes and undersample easy classes to bring hard classes closer to their sample complexity requirements while maintaining a constant dataset size for fairness. We estimate class-level hardness using the Area Under the Margin (AUM) hardness estimator and leverage it to compute resampling ratios. Using these ratios, we perform hardness-based resampling on the well-known CIFAR-10 and CIFAR-100 datasets. Contrary to theoretical expectations, our results show that hardness-based resampling does not meaningfully affect class-wise performance disparities. To explain this discrepancy, we conduct detailed analyses to identify key challenges unique to hardness-based imbalance, distinguishing it from traditional data-based imbalance. Our insights help explain why theoretical sample complexity expectations fail to translate into practical performance gains and we provide guidelines for future research.
Investigating the Impact of Hard Samples on Accuracy Reveals In-class Data Imbalance
Sep 22, 2024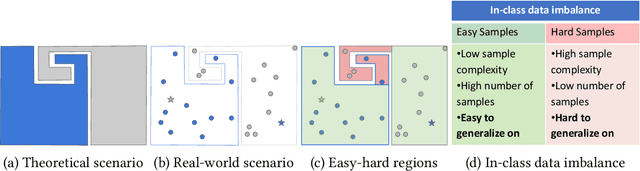
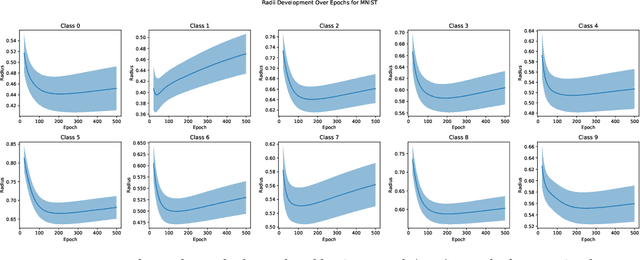
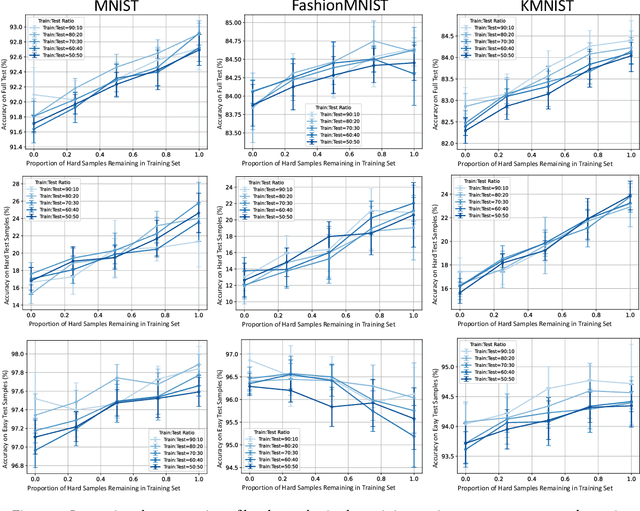
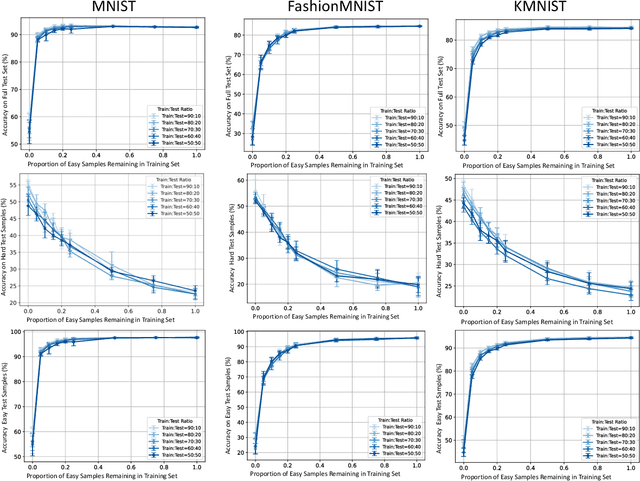
In the AutoML domain, test accuracy is heralded as the quintessential metric for evaluating model efficacy, underpinning a wide array of applications from neural architecture search to hyperparameter optimization. However, the reliability of test accuracy as the primary performance metric has been called into question, notably through research highlighting how label noise can obscure the true ranking of state-of-the-art models. We venture beyond, along another perspective where the existence of hard samples within datasets casts further doubt on the generalization capabilities inferred from test accuracy alone. Our investigation reveals that the distribution of hard samples between training and test sets affects the difficulty levels of those sets, thereby influencing the perceived generalization capability of models. We unveil two distinct generalization pathways-toward easy and hard samples-highlighting the complexity of achieving balanced model evaluation. Finally, we propose a benchmarking procedure for comparing hard sample identification methods, facilitating the advancement of more nuanced approaches in this area. Our primary goal is not to propose a definitive solution but to highlight the limitations of relying primarily on test accuracy as an evaluation metric, even when working with balanced datasets, by introducing the in-class data imbalance problem. By doing so, we aim to stimulate a critical discussion within the research community and open new avenues for research that consider a broader spectrum of model evaluation criteria. The anonymous code is available at https://github.com/PawPuk/CurvBIM blueunder the GPL-3.0 license.
SkelEx and BoundEx: Natural Visualization of ReLU Neural Networks
May 09, 2023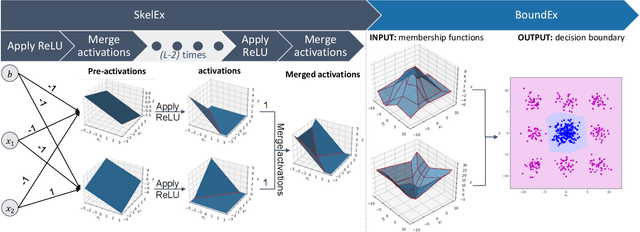
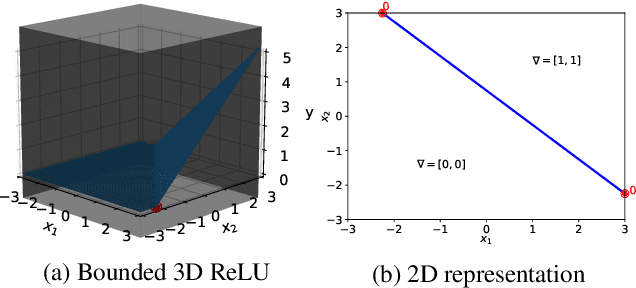
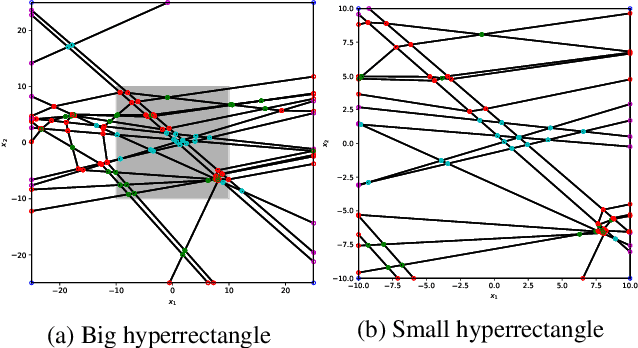
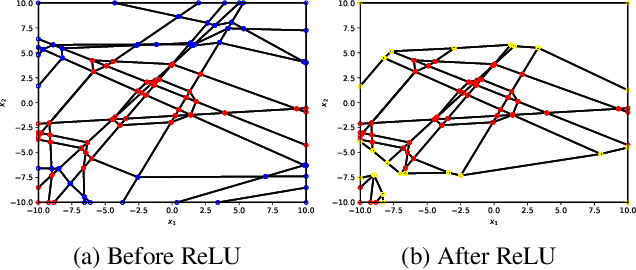
Despite their limited interpretability, weights and biases are still the most popular encoding of the functions learned by ReLU Neural Networks (ReLU NNs). That is why we introduce SkelEx, an algorithm to extract a skeleton of the membership functions learned by ReLU NNs, making those functions easier to interpret and analyze. To the best of our knowledge, this is the first work that considers linear regions from the perspective of critical points. As a natural follow-up, we also introduce BoundEx, which is the first analytical method known to us to extract the decision boundary from the realization of a ReLU NN. Both of those methods introduce very natural visualization tool for ReLU NNs trained on low-dimensional data.