 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Impact of Hard Samples on Accuracy Reveals In-class Data Imbalance
Paper and Code
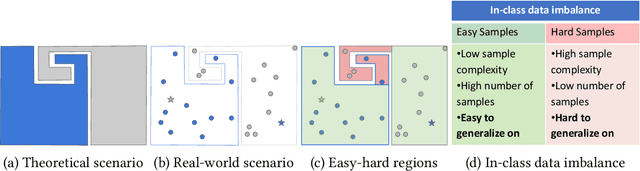
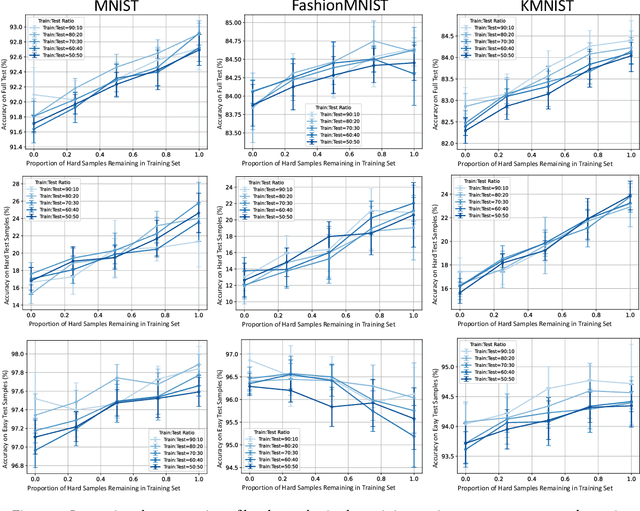
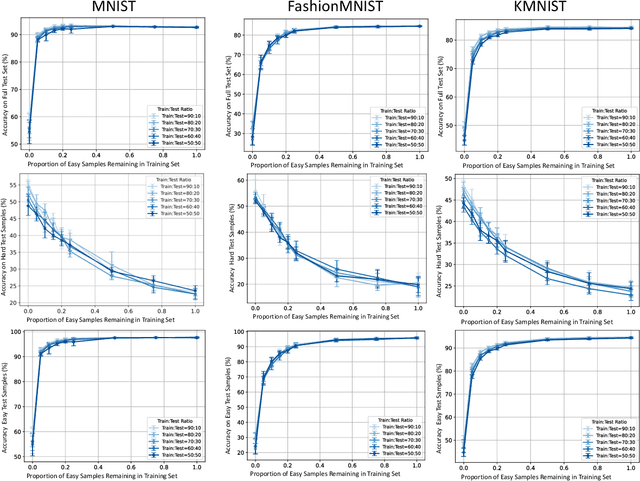
In the AutoML domain, test accuracy is heralded as the quintessential metric for evaluating model efficacy, underpinning a wide array of applications from neural architecture search to hyperparameter optimization. However, the reliability of test accuracy as the primary performance metric has been called into question, notably through research highlighting how label noise can obscure the true ranking of state-of-the-art models. We venture beyond, along another perspective where the existence of hard samples within datasets casts further doubt on the generalization capabilities inferred from test accuracy alone. Our investigation reveals that the distribution of hard samples between training and test sets affects the difficulty levels of those sets, thereby influencing the perceived generalization capability of models. We unveil two distinct generalization pathways-toward easy and hard samples-highlighting the complexity of achieving balanced model evaluation. Finally, we propose a benchmarking procedure for comparing hard sample identification methods, facilitating the advancement of more nuanced approaches in this area. Our primary goal is not to propose a definitive solution but to highlight the limitations of relying primarily on test accuracy as an evaluation metric, even when working with balanced datasets, by introducing the in-class data imbalance problem. By doing so, we aim to stimulate a critical discussion within the research community and open new avenues for research that consider a broader spectrum of model evaluation criteria. The anonymous code is available at https://github.com/PawPuk/CurvBIM blueunder the GPL-3.0 license.