 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Segmentation from Unconstrained Handwritten Bangla Document Images using Distance Transform
Sep 17, 2020Segmentation of handwritten document images into text lines and words is one of the most significant and challenging tasks in the development of a complete Optical Character Recognition (OCR) system. This paper addresses the automatic segmentation of text words directly from unconstrained Bangla handwritten document images. The popular Distance transform (DT) algorithm is applied for locating the outer boundary of the word images. This technique is free from generating the over-segmented words. A simple post-processing procedure is applied to isolate the under-segmented word images, if any. The proposed technique is tested on 50 random images taken from CMATERdb1.1.1 database. Satisfactory result is achieved with a segmentation accuracy of 91.88% which confirms the robustness of the proposed methodology.
* 12 pages, 5 figures, conference
A New Approach for Texture based Script Identification At Block Level using Quad Tree Decomposition
Sep 16, 2020A considerable amount of success has been achieved in developing monolingual OCR systems for Indic scripts. But in a country like India, where multi-script scenario is prevalent, identifying scripts beforehand becomes obligatory. In this paper, we present the significance of Gabor wavelets filters in extracting directional energy and entropy distributions for 11 official handwritten scripts namely, Bangla, Devanagari, Gujarati, Gurumukhi, Kannada, Malayalam, Oriya, Tamil, Telugu, Urdu and Roman. The experimentation is conducted at block level based on a quad-tree decomposition approach and evaluated using six different well-known classifiers. Finally, the best identification accuracy of 96.86% has been achieved by Multi Layer Perceptron (MLP) classifier for 3-fold cross validation at level-2 decomposition. The results serve to establish the efficacy of the present approach to the classification of handwritten Indic scripts
* 13 pages, 5 figures, conference
Handwritten Script Identification from Text Lines
Sep 16, 2020In a multilingual country like India where 12 different official scripts are in use, automatic identification of handwritten script facilitates many important applications such as automatic transcription of multilingual documents, searching for documents on the web/digital archives containing a particular script and for the selection of script specific Optical Character Recognition (OCR) system in a multilingual environment. In this paper, we propose a robust method towards identifying scripts from the handwritten documents at text line-level. The recognition is based upon features extracted using Chain Code Histogram (CCH) and Discrete Fourier Transform (DFT). The proposed method is experimented on 800 handwritten text lines written in seven Indic scripts namely, Gujarati, Kannada, Malayalam, Oriya, Tamil, Telugu, Urdu along with Roman script and yielded an average identification rate of 95.14% using Support Vector Machine (SVM) classifier.
* 12 pages, 4 figures, conference
A Hybrid Swarm and Gravitation based feature selection algorithm for Handwritten Indic Script Classification problem
May 10, 2020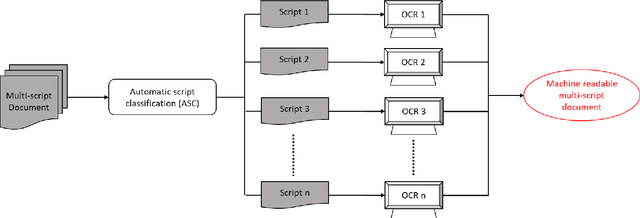
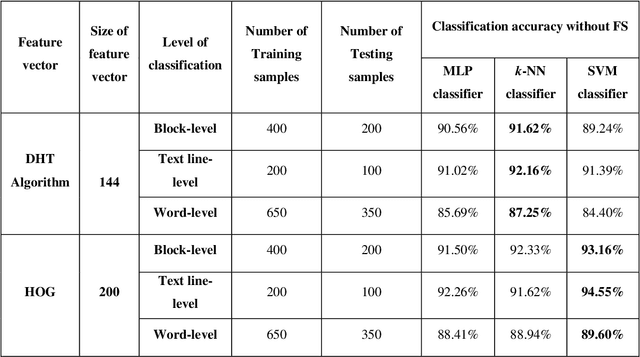
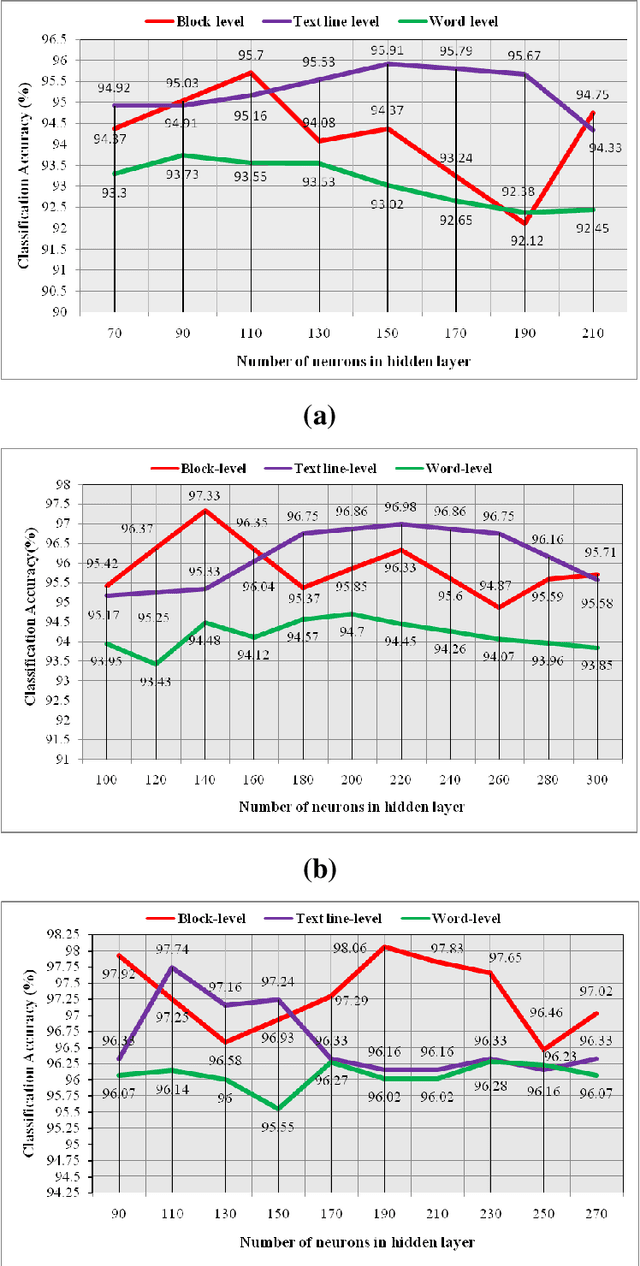

In any multi-script environment, handwritten script classification is of paramount importance before the document images are fed to their respective Optical Character Recognition (OCR) engines. Over the years, this complex pattern classification problem has been solved by researchers proposing various feature vectors mostly having large dimension, thereby increasing the computation complexity of the whole classification model. Feature Selection (FS) can serve as an intermediate step to reduce the size of the feature vectors by restricting them only to the essential and relevant features. In our paper, we have addressed this issue by introducing a new FS algorithm, called Hybrid Swarm and Gravitation based FS (HSGFS). This algorithm is made to run on 3 feature vectors introduced in the literature recently - Distance-Hough Transform (DHT), Histogram of Oriented Gradients (HOG) and Modified log-Gabor (MLG) filter Transform. Three state-of-the-art classifiers namely, Multi-Layer Perceptron (MLP), K-Nearest Neighbour (KNN) and Support Vector Machine (SVM) are used for the handwritten script classification. Handwritten datasets, prepared at block, text-line and word level, consisting of officially recognized 12 Indic scripts are used for the evaluation of our method. An average improvement in the range of 2-5 % is achieved in the classification accuracies by utilizing only about 75-80 % of the original feature vectors on all three datasets. The proposed methodology also shows better performance when compared to some popularly used FS models.
Fashion Retail: Forecasting Demand for New Items
Jun 27, 2019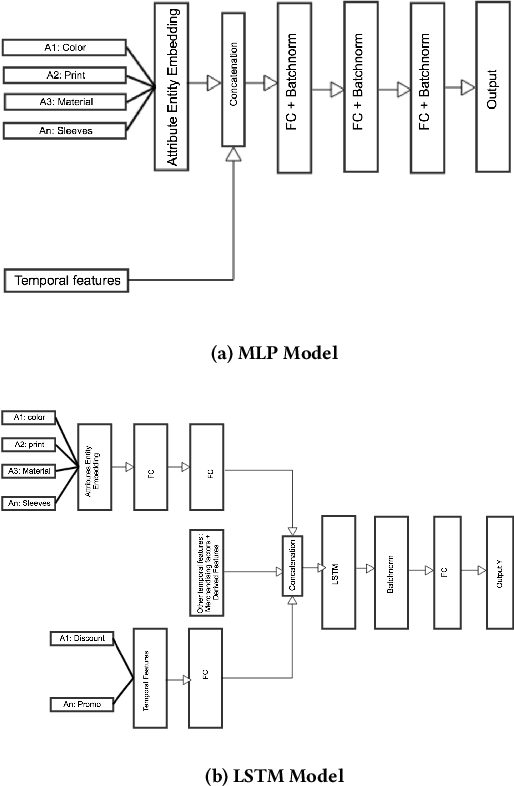
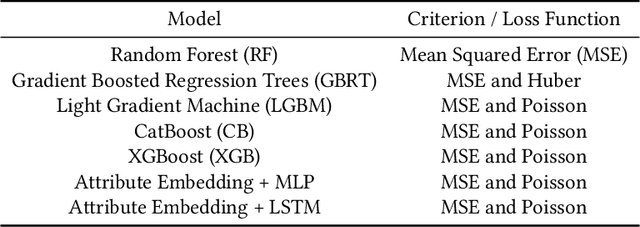
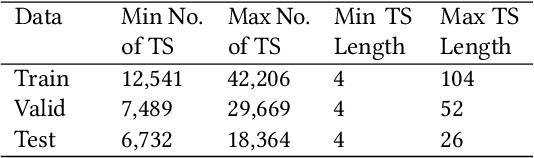
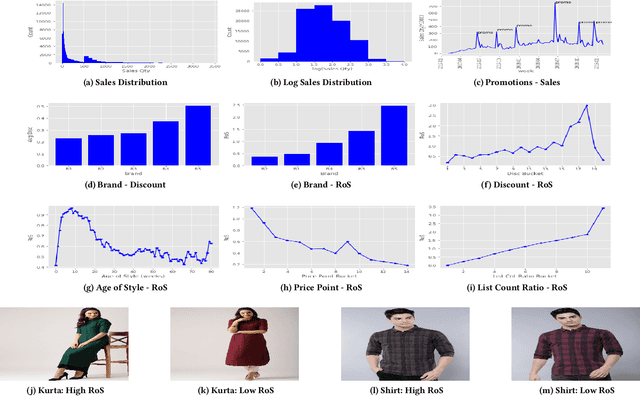
Fashion merchandising is one of the most complicated problems in forecasting, given the transient nature of trends in colours, prints, cuts, patterns, and materials in fashion, the economies of scale achievable only in bulk production, as well as geographical variations in consumption. Retailers that serve a large customer base spend a lot of money and resources to stay prepared for meeting changing fashion demands, and incur huge losses in unsold inventory and liquidation costs [2]. This problem has been addressed by analysts and statisticians as well as ML researchers in a conventional fashion - of building models that forecast for future demand given a particular item of fashion with historical data on its sales. To our knowledge, none of these models have generalized well to predict future demand at an abstracted level for a new design/style of fashion article. To address this problem, we present a study of large scale fashion sales data and directly infer which clothing/footwear attributes and merchandising factors drove demand for those items. We then build generalised models to forecast demand given new item attributes, and demonstrate robust performance by experimenting with different neural architectures, ML methods, and loss functions.
Recognition of Offline Handwritten Devanagari Numerals using Regional Weighted Run Length Features
Jun 29, 2018
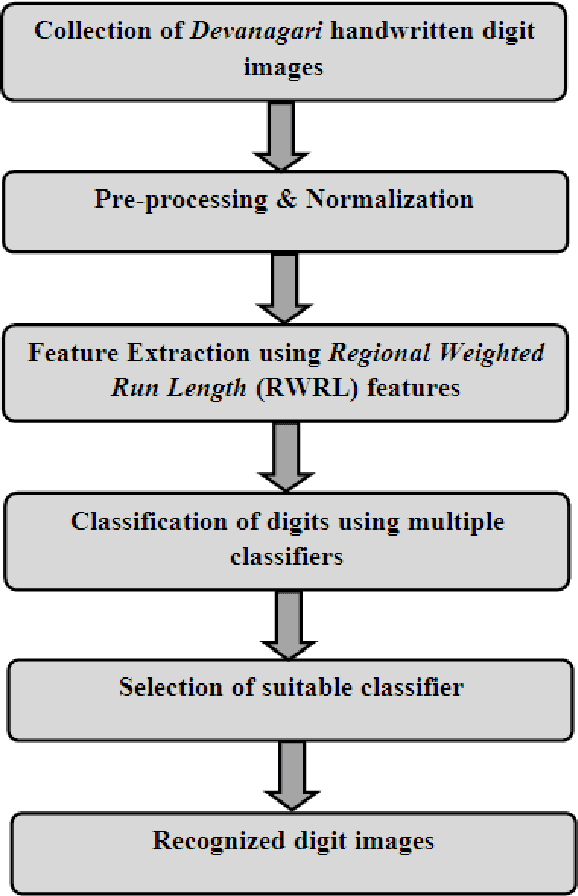
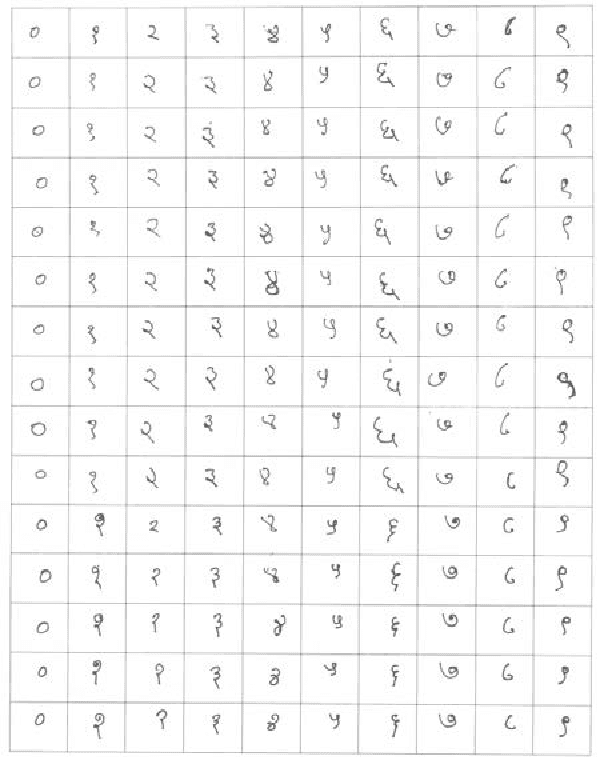

Recognition of handwritten Roman characters and numerals has been extensively studied in the last few decades and its accuracy reached to a satisfactory state. But the same cannot be said while talking about the Devanagari script which is one of most popular script in India. This paper proposes an efficient digit recognition system for handwritten Devanagari script. The system uses a novel 196-element Mask Oriented Directional (MOD) features for the recognition purpose. The methodology is tested using five conventional classifiers on 6000 handwritten digit samples. On applying 3-fold cross-validation scheme, the proposed system yields the highest recognition accuracy of 95.02% using Support Vector Machine (SVM) classifier.
* 6 pages
Understanding Fashionability: What drives sales of a style?
Jun 28, 2018
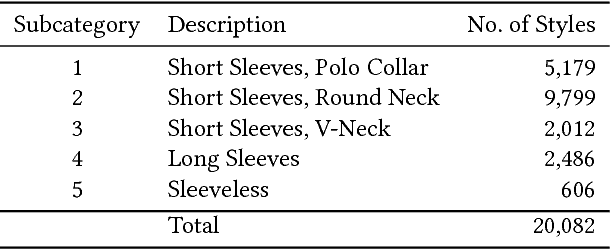
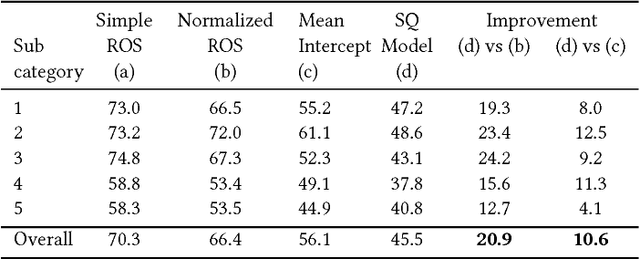
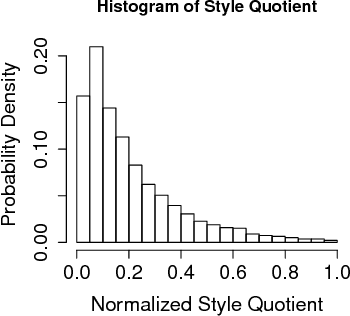
We use customer demand data for fashion articles on Myntra, and derive a fashionability or style quotient, which represents customer demand for the stylistic content of a fashion article, decoupled with its commercials (price, offers, etc.). We demonstrate learning for assortment planning in fashion that would aim to keep a healthy mix of breadth and depth across various styles, and we show the relationship between a customer's perception of a style vs a merchandiser's catalogue of styles. We also backtest our method to calculate prediction errors in our style quotient and customer demand, and discuss various implications and findings.
A Harmony Search Based Wrapper Feature Selection Method for Holistic Bangla word Recognition
Jul 26, 2017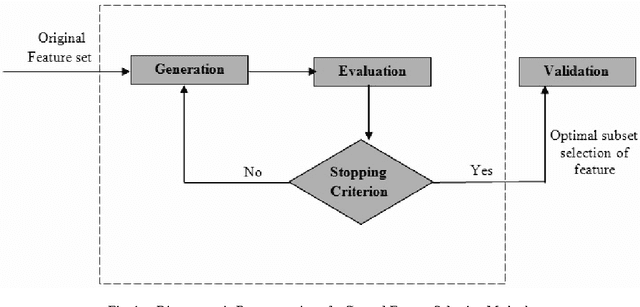
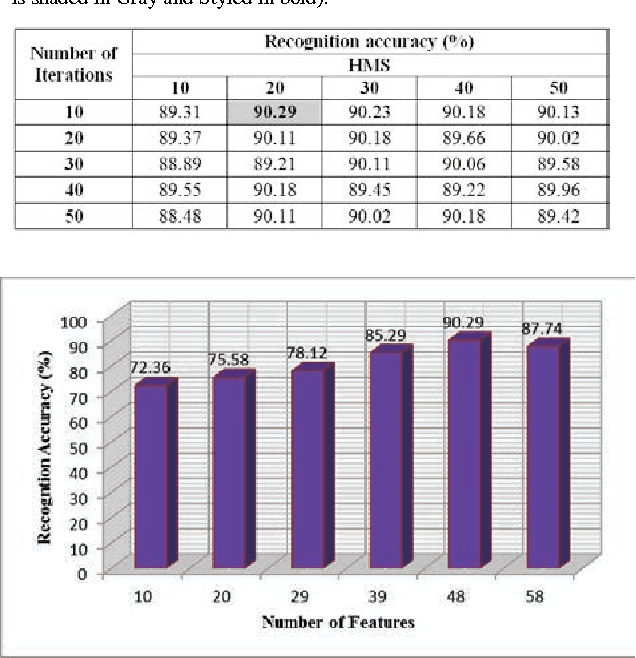
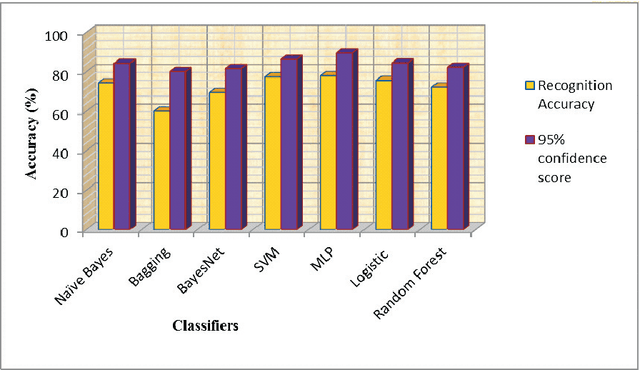

A lot of search approaches have been explored for the selection of features in pattern classification domain in order to discover significant subset of the features which produces better accuracy. In this paper, we introduced a Harmony Search (HS) algorithm based feature selection method for feature dimensionality reduction in handwritten Bangla word recognition problem. This algorithm has been implemented to reduce the feature dimensionality of a technique described in one of our previous papers by S. Bhowmik et al.[1]. In the said paper, a set of 65 elliptical features were computed for handwritten Bangla word recognition purpose and a recognition accuracy of 81.37% was achieved using Multi Layer Perceptron (MLP) classifier. In the present work, a subset containing 48 features (approximately 75% of said feature vector) has been selected by HS based wrapper feature selection method which produces an accuracy rate of 90.29%. Reasonable outcomes also validates that the introduced algorithm utilizes optimal number of features while showing higher classification accuracies when compared to two standard evolutionary algorithms like Genetic Algorithm (GA), Particle Swarm Optimization (PSO) and statistical feature dimensionality reduction technique like Principal Component Analysis (PCA). This confirms the suitability of HS algorithm to the holistic handwritten word recognition problem.