 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Skill Element in Online Fantasy Cricket
Dec 24, 2025Online fantasy cricket has emerged as large-scale competitive systems in which participants construct virtual teams and compete based on real-world player performances. This massive growth has been accompanied by important questions about whether outcomes are primarily driven by skill or chance. We develop a statistical framework to assess the role of skill in determining success on these platforms. We construct and analyze a range of deterministic and stochastic team selection strategies, based on recent form, historical statistics, statistical optimization, and multi-criteria decision making. Strategy performance is evaluated based on points, ranks, and payoff under two contest structures Mega and 4x or Nothing. An extensive comparison between different strategies is made to find an optimal set of strategies. To capture adaptive behavior, we further introduce a dynamic tournament model in which agent populations evolve through a softmax reweighting mechanism proportional to positive payoff realizations. We demonstrate our work by running extensive numerical experiments on the IPL 2024 dataset. The results provide quantitative evidence in favor of the skill element present in online fantasy cricket platforms.
Privacy-preserving federated prediction of pain intensity change based on multi-center survey data
Sep 12, 2024Background: Patient-reported survey data are used to train prognostic models aimed at improving healthcare. However, such data are typically available multi-centric and, for privacy reasons, cannot easily be centralized in one data repository. Models trained locally are less accurate, robust, and generalizable. We present and apply privacy-preserving federated machine learning techniques for prognostic model building, where local survey data never leaves the legally safe harbors of the medical centers. Methods: We used centralized, local, and federated learning techniques on two healthcare datasets (GLA:D data from the five health regions of Denmark and international SHARE data of 27 countries) to predict two different health outcomes. We compared linear regression, random forest regression, and random forest classification models trained on local data with those trained on the entire data in a centralized and in a federated fashion. Results: In GLA:D data, federated linear regression (R2 0.34, RMSE 18.2) and federated random forest regression (R2 0.34, RMSE 18.3) models outperform their local counterparts (i.e., R2 0.32, RMSE 18.6, R2 0.30, RMSE 18.8) with statistical significance. We also found that centralized models (R2 0.34, RMSE 18.2, R2 0.32, RMSE 18.5, respectively) did not perform significantly better than the federated models. In SHARE, the federated model (AC 0.78, AUROC: 0.71) and centralized model (AC 0.84, AUROC: 0.66) perform significantly better than the local models (AC: 0.74, AUROC: 0.69). Conclusion: Federated learning enables the training of prognostic models from multi-center surveys without compromising privacy and with only minimal or no compromise regarding model performance.
A New Approach for Texture based Script Identification At Block Level using Quad Tree Decomposition
Sep 16, 2020A considerable amount of success has been achieved in developing monolingual OCR systems for Indic scripts. But in a country like India, where multi-script scenario is prevalent, identifying scripts beforehand becomes obligatory. In this paper, we present the significance of Gabor wavelets filters in extracting directional energy and entropy distributions for 11 official handwritten scripts namely, Bangla, Devanagari, Gujarati, Gurumukhi, Kannada, Malayalam, Oriya, Tamil, Telugu, Urdu and Roman. The experimentation is conducted at block level based on a quad-tree decomposition approach and evaluated using six different well-known classifiers. Finally, the best identification accuracy of 96.86% has been achieved by Multi Layer Perceptron (MLP) classifier for 3-fold cross validation at level-2 decomposition. The results serve to establish the efficacy of the present approach to the classification of handwritten Indic scripts
* 13 pages, 5 figures, conference
Recognition of Offline Handwritten Devanagari Numerals using Regional Weighted Run Length Features
Jun 29, 2018
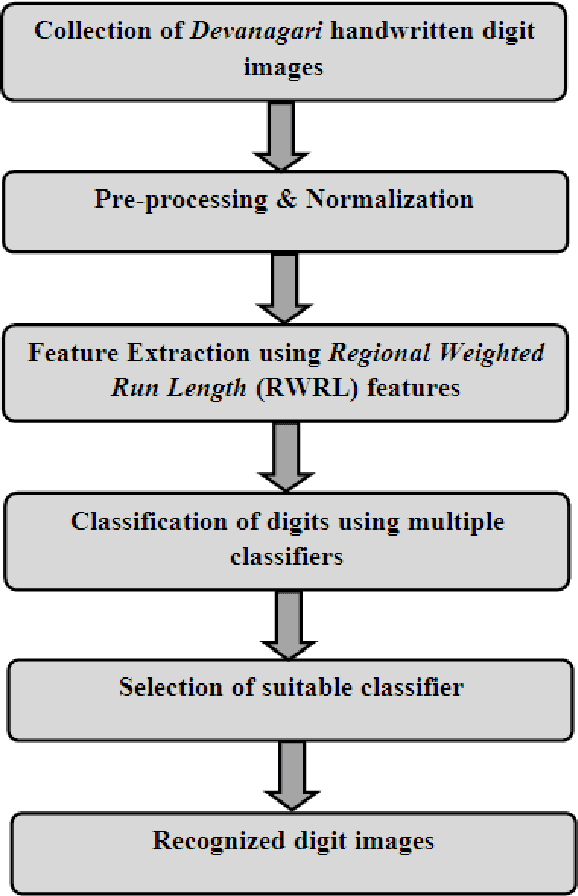
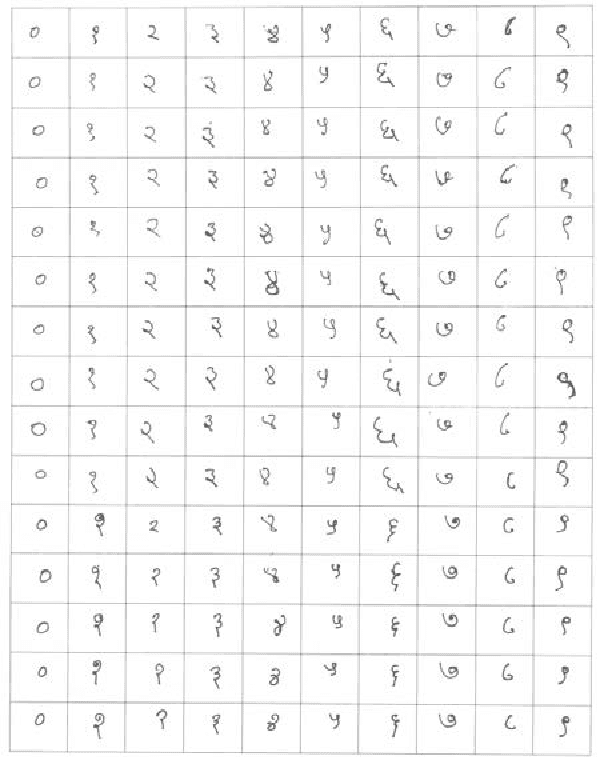

Recognition of handwritten Roman characters and numerals has been extensively studied in the last few decades and its accuracy reached to a satisfactory state. But the same cannot be said while talking about the Devanagari script which is one of most popular script in India. This paper proposes an efficient digit recognition system for handwritten Devanagari script. The system uses a novel 196-element Mask Oriented Directional (MOD) features for the recognition purpose. The methodology is tested using five conventional classifiers on 6000 handwritten digit samples. On applying 3-fold cross-validation scheme, the proposed system yields the highest recognition accuracy of 95.02% using Support Vector Machine (SVM) classifier.
* 6 pages
A Harmony Search Based Wrapper Feature Selection Method for Holistic Bangla word Recognition
Jul 26, 2017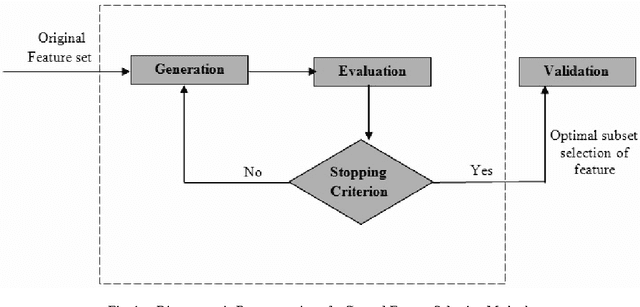
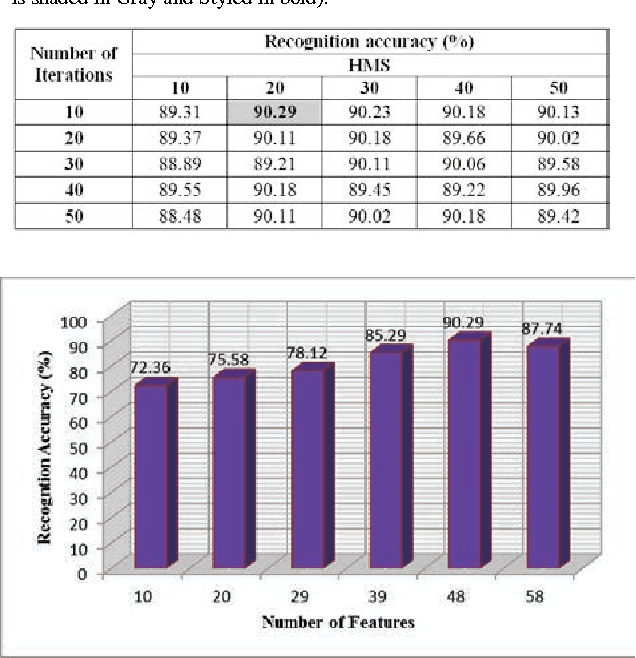
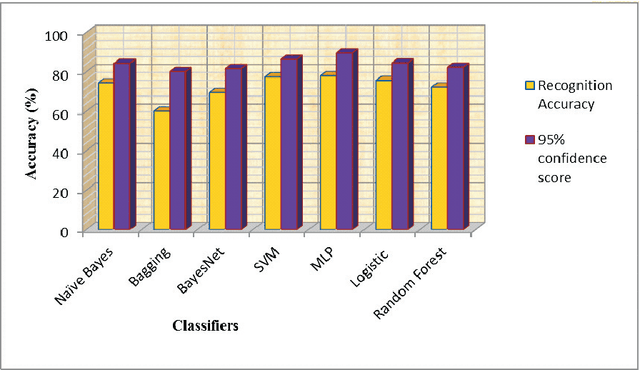

A lot of search approaches have been explored for the selection of features in pattern classification domain in order to discover significant subset of the features which produces better accuracy. In this paper, we introduced a Harmony Search (HS) algorithm based feature selection method for feature dimensionality reduction in handwritten Bangla word recognition problem. This algorithm has been implemented to reduce the feature dimensionality of a technique described in one of our previous papers by S. Bhowmik et al.[1]. In the said paper, a set of 65 elliptical features were computed for handwritten Bangla word recognition purpose and a recognition accuracy of 81.37% was achieved using Multi Layer Perceptron (MLP) classifier. In the present work, a subset containing 48 features (approximately 75% of said feature vector) has been selected by HS based wrapper feature selection method which produces an accuracy rate of 90.29%. Reasonable outcomes also validates that the introduced algorithm utilizes optimal number of features while showing higher classification accuracies when compared to two standard evolutionary algorithms like Genetic Algorithm (GA), Particle Swarm Optimization (PSO) and statistical feature dimensionality reduction technique like Principal Component Analysis (PCA). This confirms the suitability of HS algorithm to the holistic handwritten word recognition problem.