 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Laboratory Model: prognosis of abnormal clinical outcomes based on routine tests
Jun 18, 2025



Clinical laboratory results are ubiquitous in any diagnosis making. Predicting abnormal values of not prescribed tests based on the results of performed tests looks intriguing, as it would be possible to make early diagnosis available to everyone. The special place is taken by the Common Blood Count (CBC) test, as it is the most widely used clinical procedure. Combining routine biochemical panels with CBC presents a set of test-value pairs that varies from patient to patient, or, in common settings, a table with missing values. Here we formulate a tabular modeling problem as a set translation problem where the source set comprises pairs of GPT-like label column embedding and its corresponding value while the target set consists of the same type embeddings only. The proposed approach can effectively deal with missing values without implicitly estimating them and bridges the world of LLM with the tabular domain. Applying this method to clinical laboratory data, we achieve an improvement up to 8% AUC for joint predictions of high uric acid, glucose, cholesterol, and low ferritin levels.
Augmented Transformer Achieves 97% and 85% for Top5 Prediction of Direct and Classical Retro-Synthesis
Mar 05, 2020
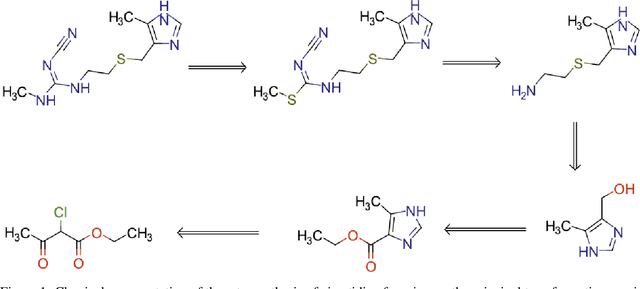

We investigated the effect of different augmentation scenarios on predicting (retro)synthesis of chemical compounds using SMILES representation. We showed that augmentation of not only input sequences but also, importantly, of the target data eliminated the effect of data memorization by neural networks and improved their generalization performance for prediction of new sequences. The Top-5 accuracy was 85.4% for the prediction of the largest fragment (thus identifying principal transformation for classical retro-synthesis) for USPTO-50k test dataset and was achieved by a combination of SMILES augmentation and beam search. The same approach also outperformed best published results for prediction of direct reactions from the USPTO-MIT test set. Our model achieved 90.4% Top-1 and 96.5% Top-5 accuracy for its most challenging mixed set and 97% Top-5 accuracy for the USPTO-MIT separated set. The appearance frequency of the most abundantly generated SMILES was well correlated with the prediction outcome and can be used as a measure of the quality of reaction prediction.
Transformer-CNN: Fast and Reliable tool for QSAR
Oct 21, 2019
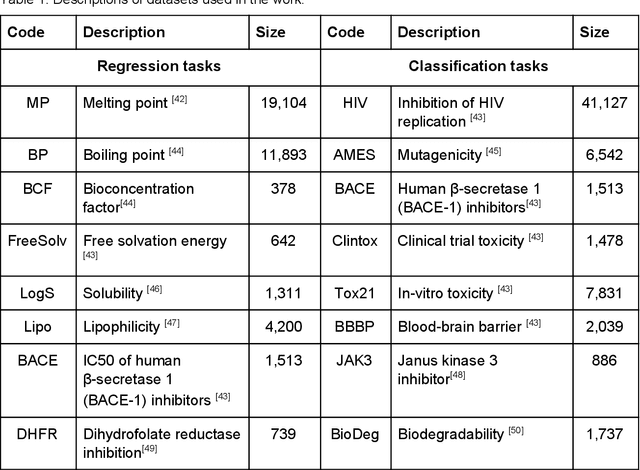
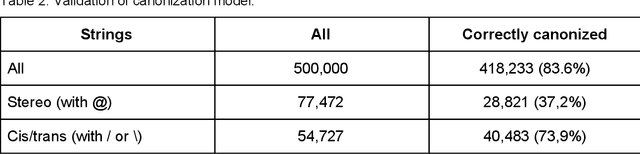

We present SMILES-embeddings derived from internal encoder state of a Transformer[1] model trained to canonize SMILES as a Seq2Seq problem. Using CharNN[2] architecture upon the embeddings results in a higher quality QSAR/QSPR models on diverse benchmark datasets including regression and classification tasks. The proposed Transformer-CNN method uses SMILES augmentation for training and inference, and thus the prognosis grounds on an internal consensus. Both the augmentation and transfer learning based on embedding allows the method to provide good results for small datasets. We discuss the reasons for such effectiveness and draft future directions for the development of the method. The source code and the embeddings are available on https://github.com/bigchem/transformer-cnn, whereas the OCHEM[3] environment (https://ochem.eu) hosts its on-line implementation.