 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Deep Subspace Alignment for Unsupervised Domain Adaptation
Jan 05, 2022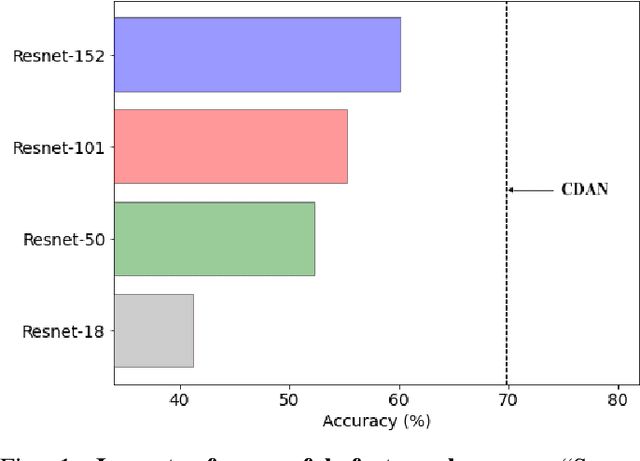
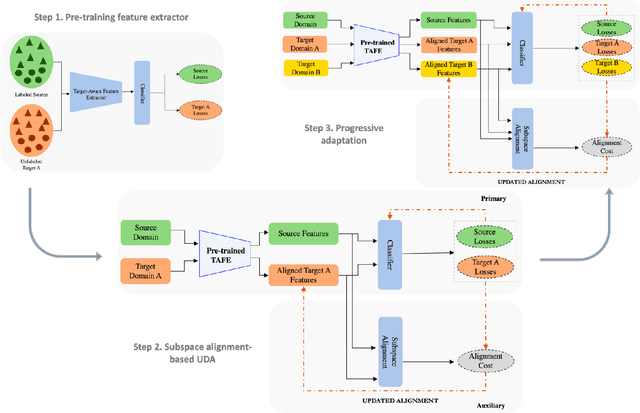
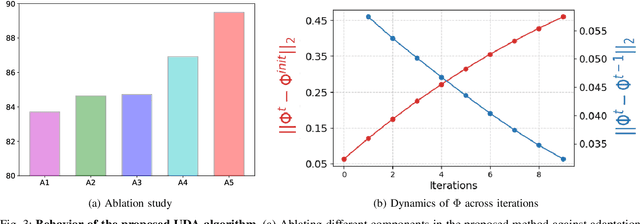
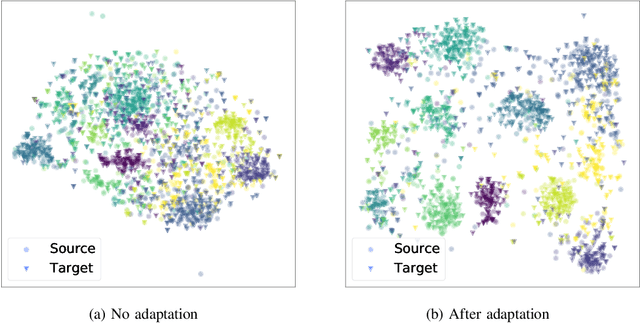
Unsupervised domain adaptation (UDA) aims to transfer and adapt knowledge from a labeled source domain to an unlabeled target domain. Traditionally, subspace-based methods form an important class of solutions to this problem. Despite their mathematical elegance and tractability, these methods are often found to be ineffective at producing domain-invariant features with complex, real-world datasets. Motivated by the recent advances in representation learning with deep networks, this paper revisits the use of subspace alignment for UDA and proposes a novel adaptation algorithm that consistently leads to improved generalization. In contrast to existing adversarial training-based DA methods, our approach isolates feature learning and distribution alignment steps, and utilizes a primary-auxiliary optimization strategy to effectively balance the objectives of domain invariance and model fidelity. While providing a significant reduction in target data and computational requirements, our subspace-based DA performs competitively and sometimes even outperforms state-of-the-art approaches on several standard UDA benchmarks. Furthermore, subspace alignment leads to intrinsically well-regularized models that demonstrate strong generalization even in the challenging partial DA setting. Finally, the design of our UDA framework inherently supports progressive adaptation to new target domains at test-time, without requiring retraining of the model from scratch. In summary, powered by powerful feature learners and an effective optimization strategy, we establish subspace-based DA as a highly effective approach for visual recognition.
Compressive Acquisition of Dynamic Scenes
Jun 26, 2013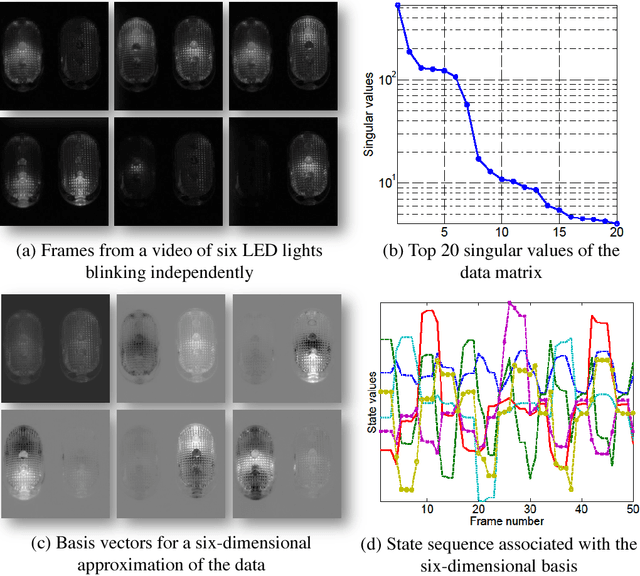

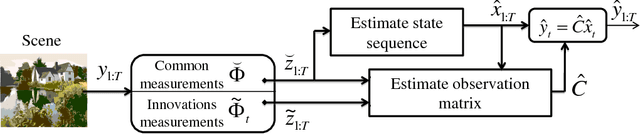
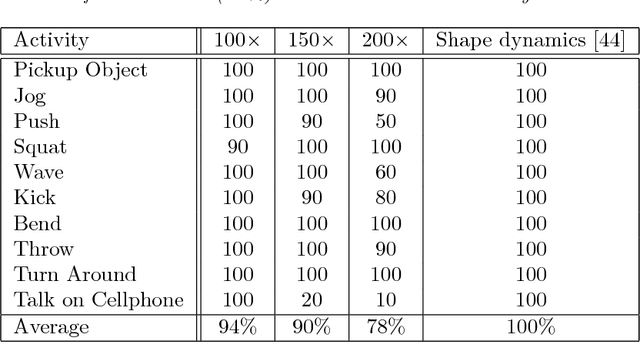
Compressive sensing (CS) is a new approach for the acquisition and recovery of sparse signals and images that enables sampling rates significantly below the classical Nyquist rate. Despite significant progress in the theory and methods of CS, little headway has been made in compressive video acquisition and recovery. Video CS is complicated by the ephemeral nature of dynamic events, which makes direct extensions of standard CS imaging architectures and signal models difficult. In this paper, we develop a new framework for video CS for dynamic textured scenes that models the evolution of the scene as a linear dynamical system (LDS). This reduces the video recovery problem to first estimating the model parameters of the LDS from compressive measurements, and then reconstructing the image frames. We exploit the low-dimensional dynamic parameters (the state sequence) and high-dimensional static parameters (the observation matrix) of the LDS to devise a novel compressive measurement strategy that measures only the dynamic part of the scene at each instant and accumulates measurements over time to estimate the static parameters. This enables us to lower the compressive measurement rate considerably. We validate our approach with a range of experiments involving both video recovery, sensing hyper-spectral data, and classification of dynamic scenes from compressive data. Together, these applications demonstrate the effectiveness of the approach.