 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic LLM-Based Framework for Population-Scale Mental Health Screening
May 13, 2026Mental health disorders affect millions worldwide, and healthcare systems are increasingly overwhelmed by the volume of clinical data generated from electronic records, telemedicine platforms, and population-level screening programs. At the same time, the emergence of novel AI-based approaches in healthcare calls for intelligent frameworks capable of processing domain-specific unstructured clinical information while adapting to patient-specific needs. This paper proposes an agentic framework for building robust LLM-based pipelines, where each stage is encapsulated as a LangChain agent governed by explicit policies and proxy-guided evaluation. Stages are incrementally locked once validated, ensuring that later adaptations cannot overwrite configurations without demonstrated improvement. The proposed framework evolves from feature-level exploration, through proxy-based tuning and freeze/rollback mechanisms, to full orchestration by an Orchestrator Agent that coordinates preprocessing, retrieval, selection, diversity, threshold optimization, and decoding. A proof-of-concept in transcript-based depression detection demonstrates that the framework converges to stable configurations, such as cosine similarity, dynamic Top-k, and threshold 0.75, while controlling evaluation costs and avoiding regressions. These results highlight the potential of agentic AI to enable population-level mental health screening over large clinical datasets, addressing critical challenges in trustworthiness, reproducibility, and adaptability required in healthcare environments.
GPT-4 on Clinic Depression Assessment: An LLM-Based Pilot Study
Dec 31, 2024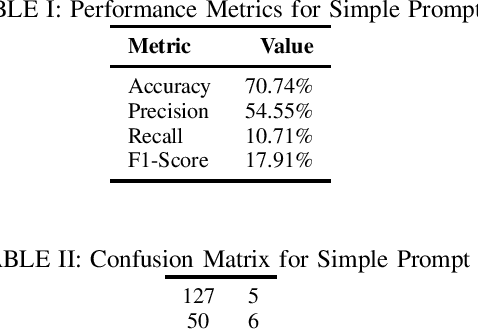
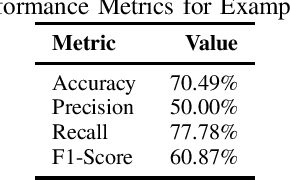
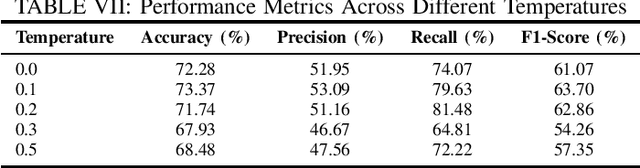
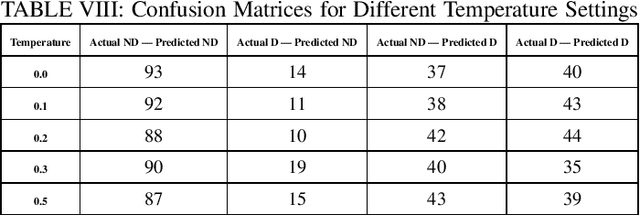
Depression has impacted millions of people worldwide and has become one of the most prevalent mental disorders. Early mental disorder detection can lead to cost savings for public health agencies and avoid the onset of other major comorbidities. Additionally, the shortage of specialized personnel is a critical issue because clinical depression diagnosis is highly dependent on expert professionals and is time consuming. In this study, we explore the use of GPT-4 for clinical depression assessment based on transcript analysis. We examine the model's ability to classify patient interviews into binary categories: depressed and not depressed. A comparative analysis is conducted considering prompt complexity (e.g., using both simple and complex prompts) as well as varied temperature settings to assess the impact of prompt complexity and randomness on the model's performance. Results indicate that GPT-4 exhibits considerable variability in accuracy and F1-Score across configurations, with optimal performance observed at lower temperature values (0.0-0.2) for complex prompts. However, beyond a certain threshold (temperature >= 0.3), the relationship between randomness and performance becomes unpredictable, diminishing the gains from prompt complexity. These findings suggest that, while GPT-4 shows promise for clinical assessment, the configuration of the prompts and model parameters requires careful calibration to ensure consistent results. This preliminary study contributes to understanding the dynamics between prompt engineering and large language models, offering insights for future development of AI-powered tools in clinical settings.
Exploring Variability in Fine-Tuned Models for Text Classification with DistilBERT
Dec 31, 2024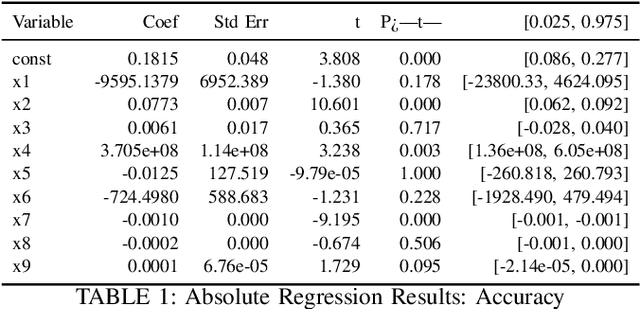
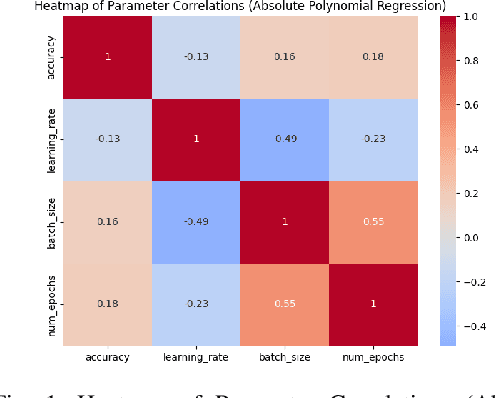
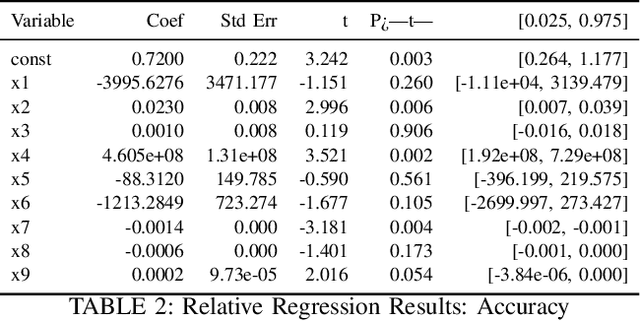
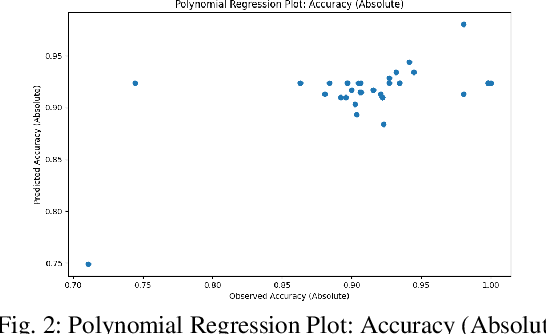
This study evaluates fine-tuning strategies for text classification using the DistilBERT model, specifically the distilbert-base-uncased-finetuned-sst-2-english variant. Through structured experiments, we examine the influence of hyperparameters such as learning rate, batch size, and epochs on accuracy, F1-score, and loss. Polynomial regression analyses capture foundational and incremental impacts of these hyperparameters, focusing on fine-tuning adjustments relative to a baseline model. Results reveal variability in metrics due to hyperparameter configurations, showing trade-offs among performance metrics. For example, a higher learning rate reduces loss in relative analysis (p=0.027) but challenges accuracy improvements. Meanwhile, batch size significantly impacts accuracy and F1-score in absolute regression (p=0.028 and p=0.005) but has limited influence on loss optimization (p=0.170). The interaction between epochs and batch size maximizes F1-score (p=0.001), underscoring the importance of hyperparameter interplay. These findings highlight the need for fine-tuning strategies addressing non-linear hyperparameter interactions to balance performance across metrics. Such variability and metric trade-offs are relevant for tasks beyond text classification, including NLP and computer vision. This analysis informs fine-tuning strategies for large language models and promotes adaptive designs for broader model applicability.
Assessing ML Classification Algorithms and NLP Techniques for Depression Detection: An Experimental Case Study
Apr 03, 2024Depression has affected millions of people worldwide and has become one of the most common mental disorders. Early mental disorder detection can reduce costs for public health agencies and prevent other major comorbidities. Additionally, the shortage of specialized personnel is very concerning since Depression diagnosis is highly dependent on expert professionals and is time-consuming. Recent research has evidenced that machine learning (ML) and Natural Language Processing (NLP) tools and techniques have significantly bene ted the diagnosis of depression. However, there are still several challenges in the assessment of depression detection approaches in which other conditions such as post-traumatic stress disorder (PTSD) are present. These challenges include assessing alternatives in terms of data cleaning and pre-processing techniques, feature selection, and appropriate ML classification algorithms. This paper tackels such an assessment based on a case study that compares different ML classifiers, specifically in terms of data cleaning and pre-processing, feature selection, parameter setting, and model choices. The case study is based on the Distress Analysis Interview Corpus - Wizard-of-Oz (DAIC-WOZ) dataset, which is designed to support the diagnosis of mental disorders such as depression, anxiety, and PTSD. Besides the assessment of alternative techniques, we were able to build models with accuracy levels around 84% with Random Forest and XGBoost models, which is significantly higher than the results from the comparable literature which presented the level of accuracy of 72% from the SVM model.
Comparing Generative Chatbots Based on Process Requirements
Nov 28, 2023


Business processes are commonly represented by modelling languages, such as Event-driven Process Chain (EPC), Yet Another Workflow Language (YAWL), and the most popular standard notation for modelling business processes, the Business Process Model and Notation (BPMN). Most recently, chatbots, programs that allow users to interact with a machine using natural language, have been increasingly used for business process execution support. A recent category of chatbots worth mentioning is generative-based chatbots, powered by Large Language Models (LLMs) such as OpenAI's Generative Pre-Trained Transformer (GPT) model and Google's Pathways Language Model (PaLM), which are trained on billions of parameters and support conversational intelligence. However, it is not clear whether generative-based chatbots are able to understand and meet the requirements of constructs such as those provided by BPMN for process execution support. This paper presents a case study to compare the performance of prominent generative models, GPT and PaLM, in the context of process execution support. The research sheds light into the challenging problem of using conversational approaches supported by generative chatbots as a means to understand process-aware modelling notations and support users to execute their tasks.
Extending Variability-Aware Model Selection with Bias Detection in Machine Learning Projects
Nov 23, 2023Data science projects often involve various machine learning (ML) methods that depend on data, code, and models. One of the key activities in these projects is the selection of a model or algorithm that is appropriate for the data analysis at hand. ML model selection depends on several factors, which include data-related attributes such as sample size, functional requirements such as the prediction algorithm type, and non-functional requirements such as performance and bias. However, the factors that influence such selection are often not well understood and explicitly represented. This paper describes ongoing work on extending an adaptive variability-aware model selection method with bias detection in ML projects. The method involves: (i) modeling the variability of the factors that affect model selection using feature models based on heuristics proposed in the literature; (ii) instantiating our variability model with added features related to bias (e.g., bias-related metrics); and (iii) conducting experiments that illustrate the method in a specific case study to illustrate our approach based on a heart failure prediction project. The proposed approach aims to advance the state of the art by making explicit factors that influence model selection, particularly those related to bias, as well as their interactions. The provided representations can transform model selection in ML projects into a non ad hoc, adaptive, and explainable process.
GPT in Data Science: A Practical Exploration of Model Selection
Nov 20, 2023There is an increasing interest in leveraging Large Language Models (LLMs) for managing structured data and enhancing data science processes. Despite the potential benefits, this integration poses significant questions regarding their reliability and decision-making methodologies. It highlights the importance of various factors in the model selection process, including the nature of the data, problem type, performance metrics, computational resources, interpretability vs accuracy, assumptions about data, and ethical considerations. Our objective is to elucidate and express the factors and assumptions guiding GPT-4's model selection recommendations. We employ a variability model to depict these factors and use toy datasets to evaluate both the model and the implementation of the identified heuristics. By contrasting these outcomes with heuristics from other platforms, our aim is to determine the effectiveness and distinctiveness of GPT-4's methodology. This research is committed to advancing our comprehension of AI decision-making processes, especially in the realm of model selection within data science. Our efforts are directed towards creating AI systems that are more transparent and comprehensible, contributing to a more responsible and efficient practice in data science.
GPT-in-the-Loop: Adaptive Decision-Making for Multiagent Systems
Aug 21, 2023This paper introduces the "GPT-in-the-loop" approach, a novel method combining the advanced reasoning capabilities of Large Language Models (LLMs) like Generative Pre-trained Transformers (GPT) with multiagent (MAS) systems. Venturing beyond traditional adaptive approaches that generally require long training processes, our framework employs GPT-4 for enhanced problem-solving and explanation skills. Our experimental backdrop is the smart streetlight Internet of Things (IoT) application. Here, agents use sensors, actuators, and neural networks to create an energy-efficient lighting system. By integrating GPT-4, these agents achieve superior decision-making and adaptability without the need for extensive training. We compare this approach with both traditional neuroevolutionary methods and solutions provided by software engineers, underlining the potential of GPT-driven multiagent systems in IoT. Structurally, the paper outlines the incorporation of GPT into the agent-driven Framework for the Internet of Things (FIoT), introduces our proposed GPT-in-the-loop approach, presents comparative results in the IoT context, and concludes with insights and future directions.
Self-Adaptive Large Language Model (LLM)-Based Multiagent Systems
Jul 12, 2023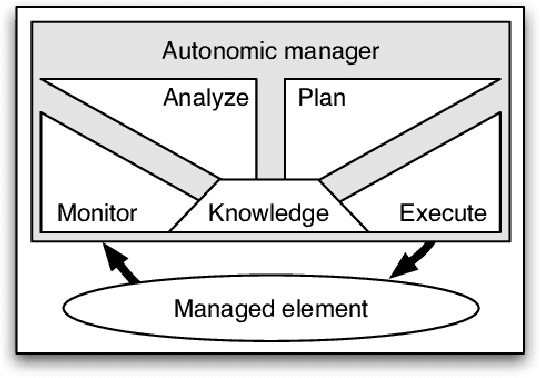
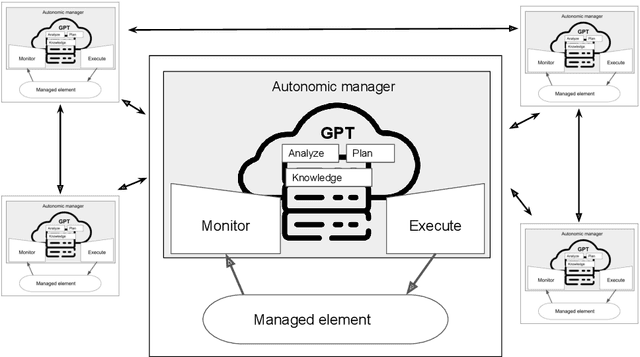
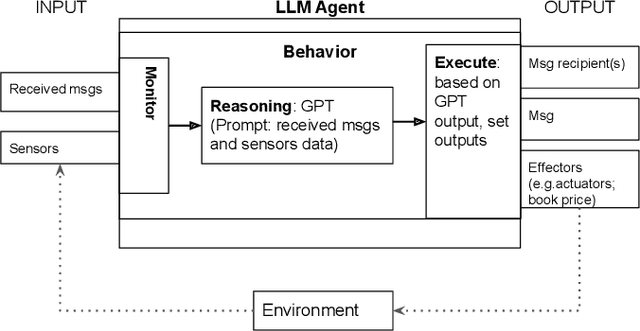
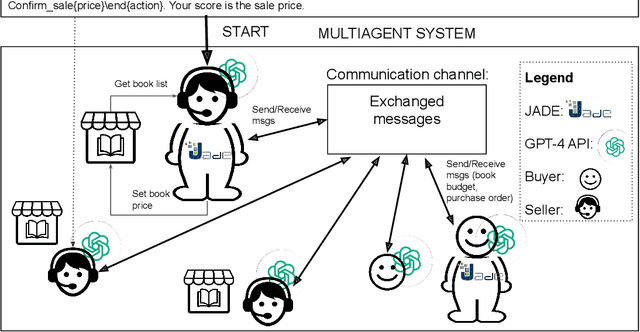
In autonomic computing, self-adaptation has been proposed as a fundamental paradigm to manage the complexity of multiagent systems (MASs). This achieved by extending a system with support to monitor and adapt itself to achieve specific concerns of interest. Communication in these systems is key given that in scenarios involving agent interaction, it enhances cooperation and reduces coordination challenges by enabling direct, clear information exchange. However, improving the expressiveness of the interaction communication with MASs is not without challenges. In this sense, the interplay between self-adaptive systems and effective communication is crucial for future MAS advancements. In this paper, we propose the integration of large language models (LLMs) such as GPT-based technologies into multiagent systems. We anchor our methodology on the MAPE-K model, which is renowned for its robust support in monitoring, analyzing, planning, and executing system adaptations in response to dynamic environments. We also present a practical illustration of the proposed approach, in which we implement and assess a basic MAS-based application. The approach significantly advances the state-of-the-art of self-adaptive systems by proposing a new paradigm for MAS self-adaptation of autonomous systems based on LLM capabilities.
Comparing Software Developers with ChatGPT: An Empirical Investigation
May 25, 2023



The advent of automation in particular Software Engineering (SE) tasks has transitioned from theory to reality. Numerous scholarly articles have documented the successful application of Artificial Intelligence to address issues in areas such as project management, modeling, testing, and development. A recent innovation is the introduction of ChatGPT, an ML-infused chatbot, touted as a resource proficient in generating programming codes and formulating software testing strategies for developers and testers respectively. Although there is speculation that AI-based computation can increase productivity and even substitute software engineers in software development, there is currently a lack of empirical evidence to verify this. Moreover, despite the primary focus on enhancing the accuracy of AI systems, non-functional requirements including energy efficiency, vulnerability, fairness (i.e., human bias), and safety frequently receive insufficient attention. This paper posits that a comprehensive comparison of software engineers and AI-based solutions, considering various evaluation criteria, is pivotal in fostering human-machine collaboration, enhancing the reliability of AI-based methods, and understanding task suitability for humans or AI. Furthermore, it facilitates the effective implementation of cooperative work structures and human-in-the-loop processes. This paper conducts an empirical investigation, contrasting the performance of software engineers and AI systems, like ChatGPT, across different evaluation metrics. The empirical study includes a case of assessing ChatGPT-generated code versus code produced by developers and uploaded in Leetcode.