 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic LLM-Based Framework for Population-Scale Mental Health Screening
May 13, 2026Mental health disorders affect millions worldwide, and healthcare systems are increasingly overwhelmed by the volume of clinical data generated from electronic records, telemedicine platforms, and population-level screening programs. At the same time, the emergence of novel AI-based approaches in healthcare calls for intelligent frameworks capable of processing domain-specific unstructured clinical information while adapting to patient-specific needs. This paper proposes an agentic framework for building robust LLM-based pipelines, where each stage is encapsulated as a LangChain agent governed by explicit policies and proxy-guided evaluation. Stages are incrementally locked once validated, ensuring that later adaptations cannot overwrite configurations without demonstrated improvement. The proposed framework evolves from feature-level exploration, through proxy-based tuning and freeze/rollback mechanisms, to full orchestration by an Orchestrator Agent that coordinates preprocessing, retrieval, selection, diversity, threshold optimization, and decoding. A proof-of-concept in transcript-based depression detection demonstrates that the framework converges to stable configurations, such as cosine similarity, dynamic Top-k, and threshold 0.75, while controlling evaluation costs and avoiding regressions. These results highlight the potential of agentic AI to enable population-level mental health screening over large clinical datasets, addressing critical challenges in trustworthiness, reproducibility, and adaptability required in healthcare environments.
Exploring Variability in Fine-Tuned Models for Text Classification with DistilBERT
Dec 31, 2024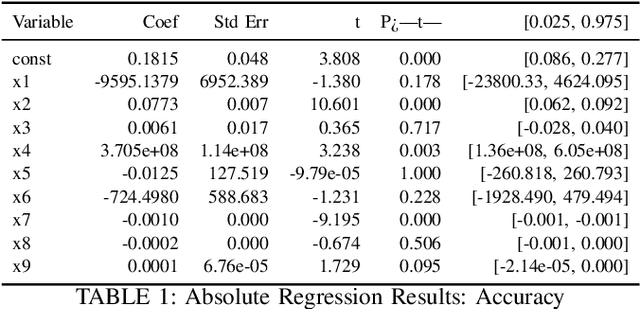
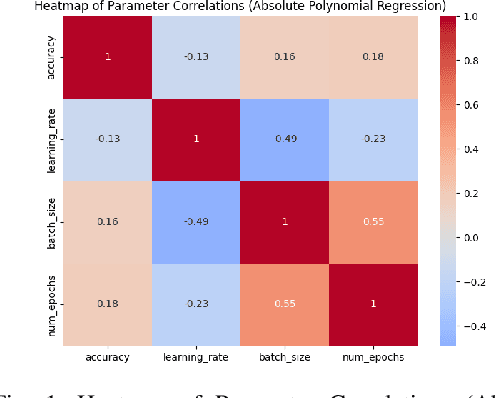
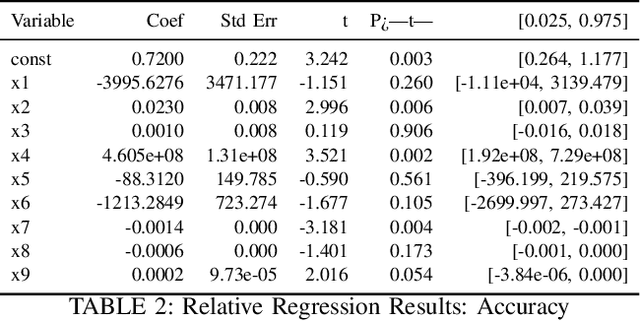
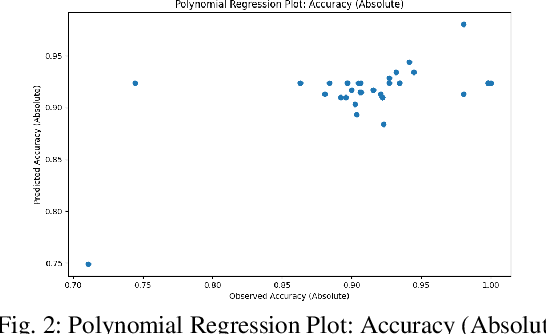
This study evaluates fine-tuning strategies for text classification using the DistilBERT model, specifically the distilbert-base-uncased-finetuned-sst-2-english variant. Through structured experiments, we examine the influence of hyperparameters such as learning rate, batch size, and epochs on accuracy, F1-score, and loss. Polynomial regression analyses capture foundational and incremental impacts of these hyperparameters, focusing on fine-tuning adjustments relative to a baseline model. Results reveal variability in metrics due to hyperparameter configurations, showing trade-offs among performance metrics. For example, a higher learning rate reduces loss in relative analysis (p=0.027) but challenges accuracy improvements. Meanwhile, batch size significantly impacts accuracy and F1-score in absolute regression (p=0.028 and p=0.005) but has limited influence on loss optimization (p=0.170). The interaction between epochs and batch size maximizes F1-score (p=0.001), underscoring the importance of hyperparameter interplay. These findings highlight the need for fine-tuning strategies addressing non-linear hyperparameter interactions to balance performance across metrics. Such variability and metric trade-offs are relevant for tasks beyond text classification, including NLP and computer vision. This analysis informs fine-tuning strategies for large language models and promotes adaptive designs for broader model applicability.
GPT-4 on Clinic Depression Assessment: An LLM-Based Pilot Study
Dec 31, 2024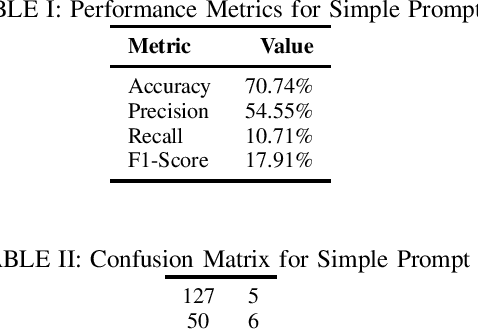
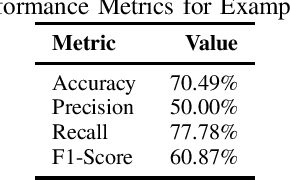
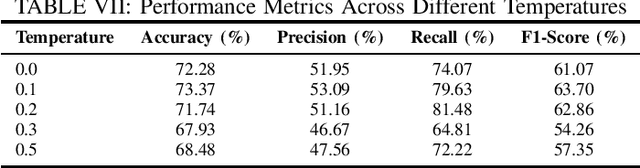
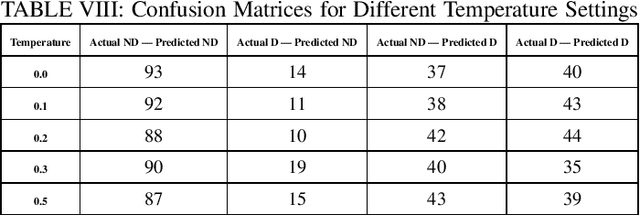
Depression has impacted millions of people worldwide and has become one of the most prevalent mental disorders. Early mental disorder detection can lead to cost savings for public health agencies and avoid the onset of other major comorbidities. Additionally, the shortage of specialized personnel is a critical issue because clinical depression diagnosis is highly dependent on expert professionals and is time consuming. In this study, we explore the use of GPT-4 for clinical depression assessment based on transcript analysis. We examine the model's ability to classify patient interviews into binary categories: depressed and not depressed. A comparative analysis is conducted considering prompt complexity (e.g., using both simple and complex prompts) as well as varied temperature settings to assess the impact of prompt complexity and randomness on the model's performance. Results indicate that GPT-4 exhibits considerable variability in accuracy and F1-Score across configurations, with optimal performance observed at lower temperature values (0.0-0.2) for complex prompts. However, beyond a certain threshold (temperature >= 0.3), the relationship between randomness and performance becomes unpredictable, diminishing the gains from prompt complexity. These findings suggest that, while GPT-4 shows promise for clinical assessment, the configuration of the prompts and model parameters requires careful calibration to ensure consistent results. This preliminary study contributes to understanding the dynamics between prompt engineering and large language models, offering insights for future development of AI-powered tools in clinical settings.
Assessing ML Classification Algorithms and NLP Techniques for Depression Detection: An Experimental Case Study
Apr 03, 2024Depression has affected millions of people worldwide and has become one of the most common mental disorders. Early mental disorder detection can reduce costs for public health agencies and prevent other major comorbidities. Additionally, the shortage of specialized personnel is very concerning since Depression diagnosis is highly dependent on expert professionals and is time-consuming. Recent research has evidenced that machine learning (ML) and Natural Language Processing (NLP) tools and techniques have significantly bene ted the diagnosis of depression. However, there are still several challenges in the assessment of depression detection approaches in which other conditions such as post-traumatic stress disorder (PTSD) are present. These challenges include assessing alternatives in terms of data cleaning and pre-processing techniques, feature selection, and appropriate ML classification algorithms. This paper tackels such an assessment based on a case study that compares different ML classifiers, specifically in terms of data cleaning and pre-processing, feature selection, parameter setting, and model choices. The case study is based on the Distress Analysis Interview Corpus - Wizard-of-Oz (DAIC-WOZ) dataset, which is designed to support the diagnosis of mental disorders such as depression, anxiety, and PTSD. Besides the assessment of alternative techniques, we were able to build models with accuracy levels around 84% with Random Forest and XGBoost models, which is significantly higher than the results from the comparable literature which presented the level of accuracy of 72% from the SVM model.
Machine Learning Model Development from a Software Engineering Perspective: A Systematic Literature Review
Feb 15, 2021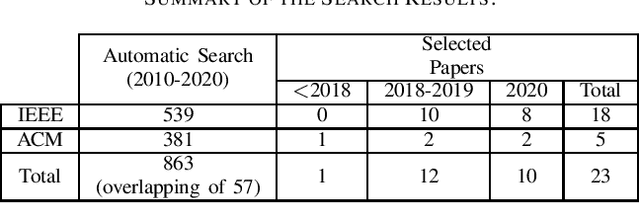

Data scientists often develop machine learning models to solve a variety of problems in the industry and academy but not without facing several challenges in terms of Model Development. The problems regarding Machine Learning Development involves the fact that such professionals do not realize that they usually perform ad-hoc practices that could be improved by the adoption of activities presented in the Software Engineering Development Lifecycle. Of course, since machine learning systems are different from traditional Software systems, some differences in their respective development processes are to be expected. In this context, this paper is an effort to investigate the challenges and practices that emerge during the development of ML models from the software engineering perspective by focusing on understanding how software developers could benefit from applying or adapting the traditional software engineering process to the Machine Learning workflow.