 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Variability in Fine-Tuned Models for Text Classification with DistilBERT
Dec 31, 2024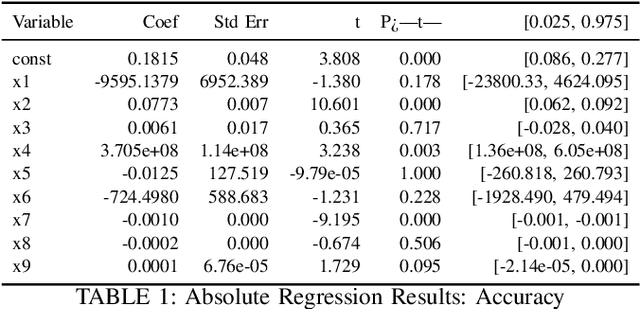
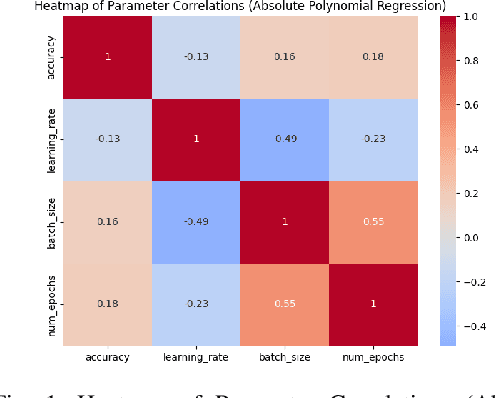
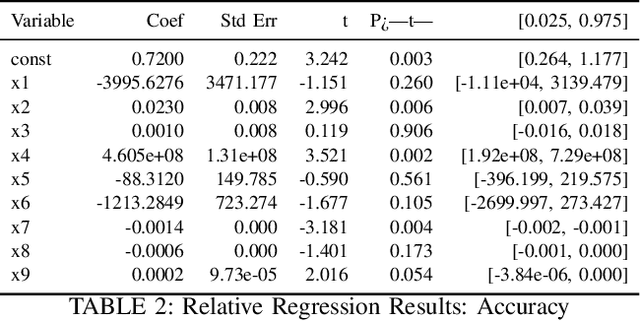
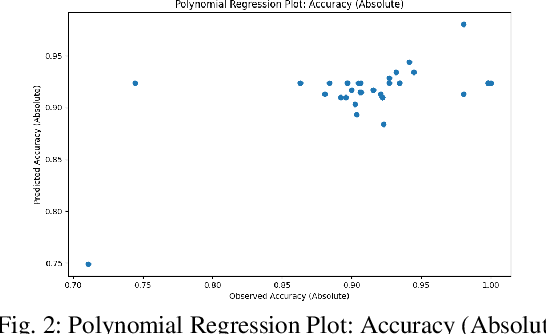
This study evaluates fine-tuning strategies for text classification using the DistilBERT model, specifically the distilbert-base-uncased-finetuned-sst-2-english variant. Through structured experiments, we examine the influence of hyperparameters such as learning rate, batch size, and epochs on accuracy, F1-score, and loss. Polynomial regression analyses capture foundational and incremental impacts of these hyperparameters, focusing on fine-tuning adjustments relative to a baseline model. Results reveal variability in metrics due to hyperparameter configurations, showing trade-offs among performance metrics. For example, a higher learning rate reduces loss in relative analysis (p=0.027) but challenges accuracy improvements. Meanwhile, batch size significantly impacts accuracy and F1-score in absolute regression (p=0.028 and p=0.005) but has limited influence on loss optimization (p=0.170). The interaction between epochs and batch size maximizes F1-score (p=0.001), underscoring the importance of hyperparameter interplay. These findings highlight the need for fine-tuning strategies addressing non-linear hyperparameter interactions to balance performance across metrics. Such variability and metric trade-offs are relevant for tasks beyond text classification, including NLP and computer vision. This analysis informs fine-tuning strategies for large language models and promotes adaptive designs for broader model applicability.
A Survey on Domain-Specific Languages for Machine Learning in Big Data
Mar 08, 2016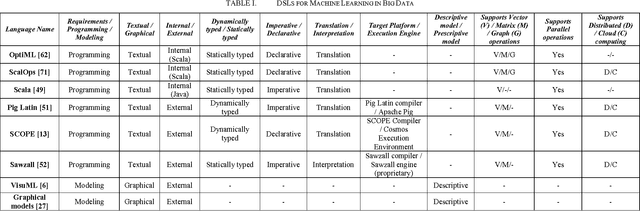

The amount of data generated in the modern society is increasing rapidly. New problems and novel approaches of data capture, storage, analysis and visualization are responsible for the emergence of the Big Data research field. Machine Learning algorithms can be used in Big Data to make better and more accurate inferences. However, because of the challenges Big Data imposes, these algorithms need to be adapted and optimized to specific applications. One important decision made by software engineers is the choice of the language that is used in the implementation of these algorithms. Therefore, this literature survey identifies and describes domain-specific languages and frameworks used for Machine Learning in Big Data. By doing this, software engineers can then make more informed choices and beginners have an overview of the main languages used in this domain.
The Use of Machine Learning Algorithms in Recommender Systems: A Systematic Review
Feb 24, 2016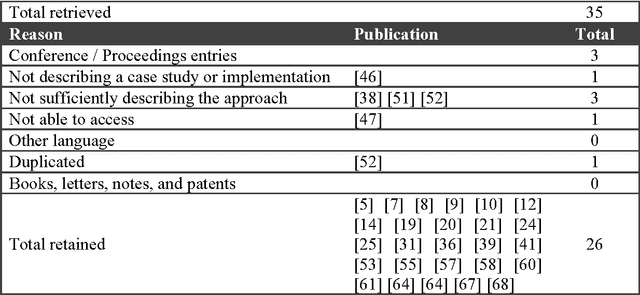
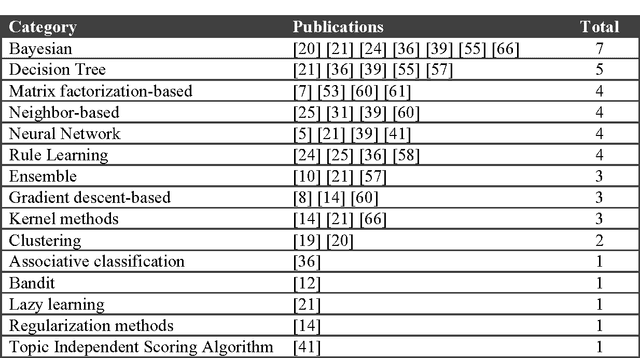

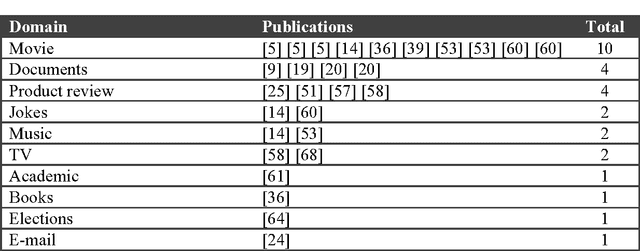
Recommender systems use algorithms to provide users with product or service recommendations. Recently, these systems have been using machine learning algorithms from the field of artificial intelligence. However, choosing a suitable machine learning algorithm for a recommender system is difficult because of the number of algorithms described in the literature. Researchers and practitioners developing recommender systems are left with little information about the current approaches in algorithm usage. Moreover, the development of a recommender system using a machine learning algorithm often has problems and open questions that must be evaluated, so software engineers know where to focus research efforts. This paper presents a systematic review of the literature that analyzes the use of machine learning algorithms in recommender systems and identifies research opportunities for software engineering research. The study concludes that Bayesian and decision tree algorithms are widely used in recommender systems because of their relative simplicity, and that requirement and design phases of recommender system development appear to offer opportunities for further research.