 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging viscous Hamilton-Jacobi PDEs for uncertainty quantification in scientific machine learning
Apr 12, 2024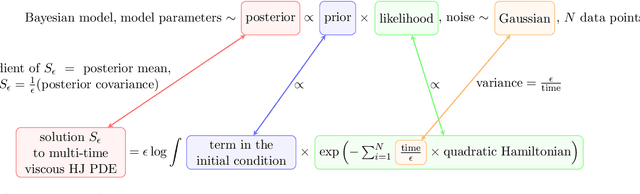

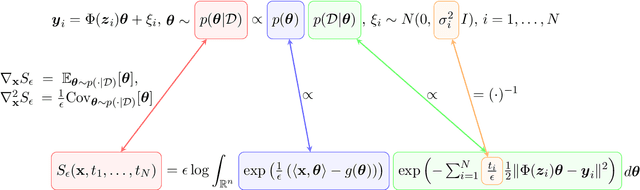

Uncertainty quantification (UQ) in scientific machine learning (SciML) combines the powerful predictive power of SciML with methods for quantifying the reliability of the learned models. However, two major challenges remain: limited interpretability and expensive training procedures. We provide a new interpretation for UQ problems by establishing a new theoretical connection between some Bayesian inference problems arising in SciML and viscous Hamilton-Jacobi partial differential equations (HJ PDEs). Namely, we show that the posterior mean and covariance can be recovered from the spatial gradient and Hessian of the solution to a viscous HJ PDE. As a first exploration of this connection, we specialize to Bayesian inference problems with linear models, Gaussian likelihoods, and Gaussian priors. In this case, the associated viscous HJ PDEs can be solved using Riccati ODEs, and we develop a new Riccati-based methodology that provides computational advantages when continuously updating the model predictions. Specifically, our Riccati-based approach can efficiently add or remove data points to the training set invariant to the order of the data and continuously tune hyperparameters. Moreover, neither update requires retraining on or access to previously incorporated data. We provide several examples from SciML involving noisy data and \textit{epistemic uncertainty} to illustrate the potential advantages of our approach. In particular, this approach's amenability to data streaming applications demonstrates its potential for real-time inferences, which, in turn, allows for applications in which the predicted uncertainty is used to dynamically alter the learning process.
Leveraging Hamilton-Jacobi PDEs with time-dependent Hamiltonians for continual scientific machine learning
Nov 13, 2023We address two major challenges in scientific machine learning (SciML): interpretability and computational efficiency. We increase the interpretability of certain learning processes by establishing a new theoretical connection between optimization problems arising from SciML and a generalized Hopf formula, which represents the viscosity solution to a Hamilton-Jacobi partial differential equation (HJ PDE) with time-dependent Hamiltonian. Namely, we show that when we solve certain regularized learning problems with integral-type losses, we actually solve an optimal control problem and its associated HJ PDE with time-dependent Hamiltonian. This connection allows us to reinterpret incremental updates to learned models as the evolution of an associated HJ PDE and optimal control problem in time, where all of the previous information is intrinsically encoded in the solution to the HJ PDE. As a result, existing HJ PDE solvers and optimal control algorithms can be reused to design new efficient training approaches for SciML that naturally coincide with the continual learning framework, while avoiding catastrophic forgetting. As a first exploration of this connection, we consider the special case of linear regression and leverage our connection to develop a new Riccati-based methodology for solving these learning problems that is amenable to continual learning applications. We also provide some corresponding numerical examples that demonstrate the potential computational and memory advantages our Riccati-based approach can provide.
Leveraging Multi-time Hamilton-Jacobi PDEs for Certain Scientific Machine Learning Problems
Mar 22, 2023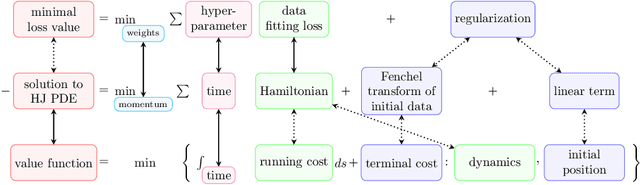

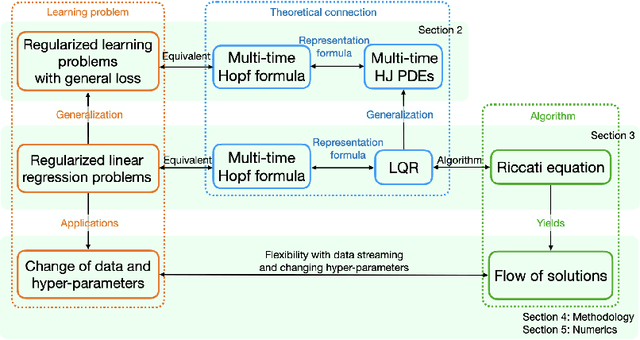

Hamilton-Jacobi partial differential equations (HJ PDEs) have deep connections with a wide range of fields, including optimal control, differential games, and imaging sciences. By considering the time variable to be a higher dimensional quantity, HJ PDEs can be extended to the multi-time case. In this paper, we establish a novel theoretical connection between specific optimization problems arising in machine learning and the multi-time Hopf formula, which corresponds to a representation of the solution to certain multi-time HJ PDEs. Through this connection, we increase the interpretability of the training process of certain machine learning applications by showing that when we solve these learning problems, we also solve a multi-time HJ PDE and, by extension, its corresponding optimal control problem. As a first exploration of this connection, we develop the relation between the regularized linear regression problem and the Linear Quadratic Regulator (LQR). We then leverage our theoretical connection to adapt standard LQR solvers (namely, those based on the Riccati ordinary differential equations) to design new training approaches for machine learning. Finally, we provide some numerical examples that demonstrate the versatility and possible computational advantages of our Riccati-based approach in the context of continual learning, post-training calibration, transfer learning, and sparse dynamics identification.