 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Constrained Codes That Enable Page Separation in Modern Flash Memories
Feb 03, 2023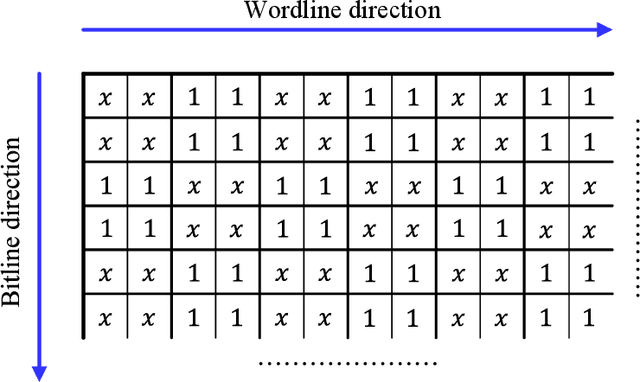
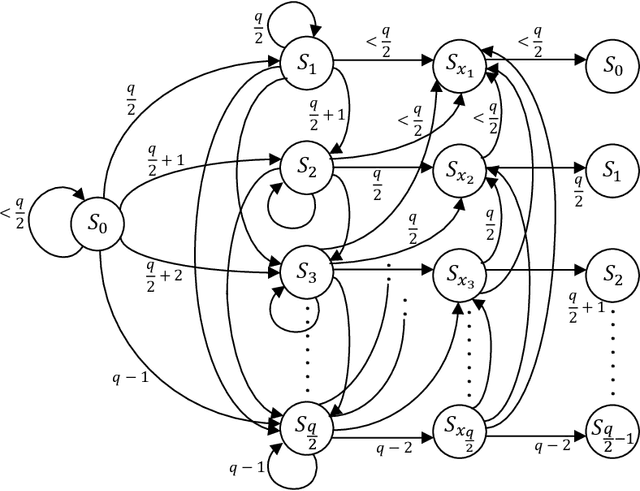
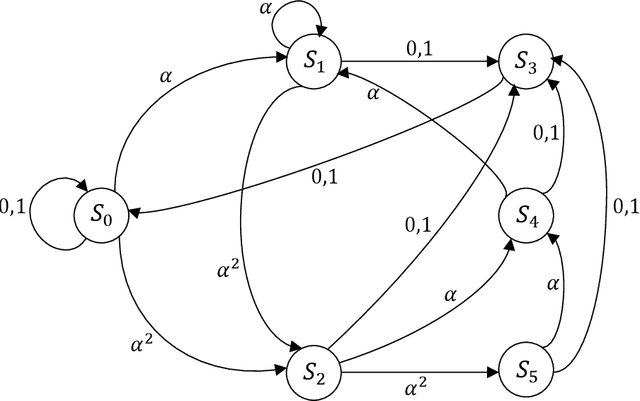
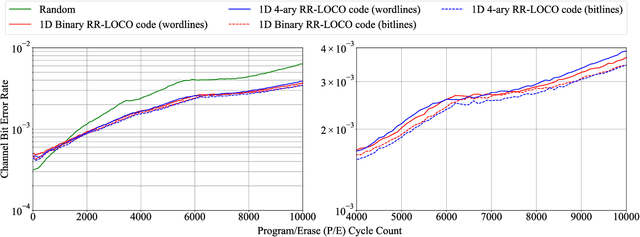
The pivotal storage density win achieved by solid-state devices over magnetic devices recently is a result of multiple innovations in physics, architecture, and signal processing. Constrained coding is used in Flash devices to increase reliability via mitigating inter-cell interference. Recently, capacity-achieving constrained codes were introduced to serve that purpose. While these codes result in minimal redundancy, they result in non-negligible complexity increase and access speed limitation since pages cannot be read separately. In this paper, we suggest new constrained coding schemes that have low-complexity and preserve the desirable high access speed in modern Flash devices. The idea is to eliminate error-prone patterns by coding data either only on the left-most page (binary coding) or only on the two left-most pages ($4$-ary coding) while leaving data on all the remaining pages uncoded. Our coding schemes are systematic and capacity-approaching. We refer to the proposed schemes as read-and-run (RR) constrained coding schemes. The $4$-ary RR coding scheme is introduced to limit the rate loss. We analyze the new RR coding schemes and discuss their impact on the probability of occurrence of different charge levels. We also demonstrate the performance improvement achieved via RR coding on a practical triple-level cell Flash device.
Read-and-Run Constrained Coding for Modern Flash Devices
Nov 14, 2021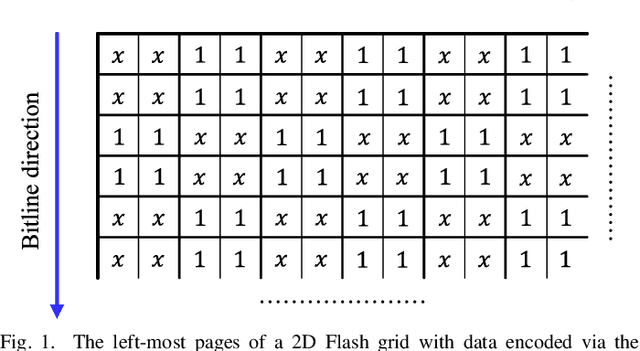
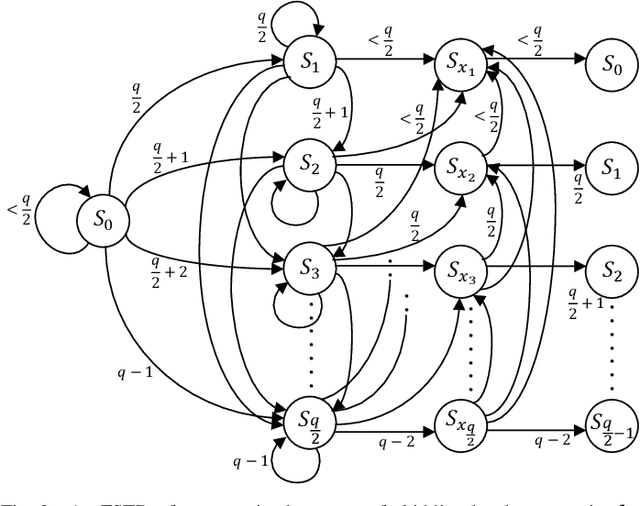
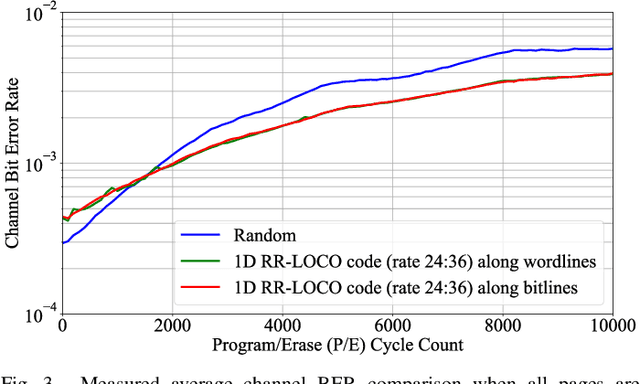
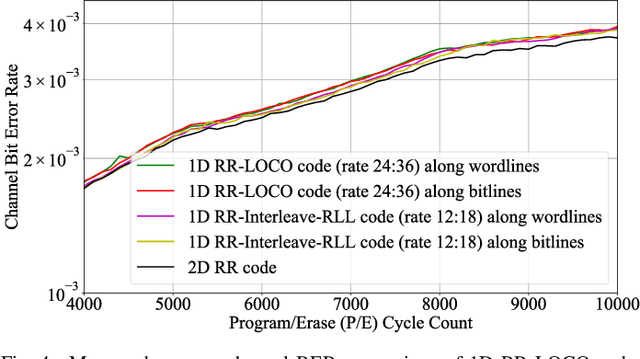
The pivotal storage density win achieved by solid-state devices over magnetic devices in 2015 is a result of multiple innovations in physics, architecture, and signal processing. One of the most important innovations in that regard is enabling the storage of more than one bit per cell in the Flash device, i.e., having more than two charge levels per cell. Constrained coding is used in Flash devices to increase reliability via mitigating inter-cell interference that stems from charge propagation among cells. Recently, capacity-achieving constrained codes were introduced to serve that purpose in modern Flash devices, which have more than two levels per cell. While these codes result in minimal redundancy via exploiting the underlying physics, they result in non-negligible complexity increase and access speed limitation since pages cannot be read separately. In this paper, we suggest new constrained coding schemes that have low-complexity and preserve the desirable high access speed in modern Flash devices. The idea is to eliminate error-prone patterns by coding data only on the left-most page while leaving data on all the remaining pages uncoded. Our coding schemes work for any number of levels per cell, offer systematic encoding and decoding, and are capacity-approaching. Since the proposed schemes enable the separation of pages, we refer to them as read-and-run (RR) constrained coding schemes as opposed to schemes adopting read-and-wait for other pages. We analyze the new RR coding schemes and discuss their impact on the probability of occurrence of different charge levels. We also demonstrate the performance improvement achieved via RR coding on a practical triple-level cell Flash device.
Functional Error Correction for Robust Neural Networks
Jan 12, 2020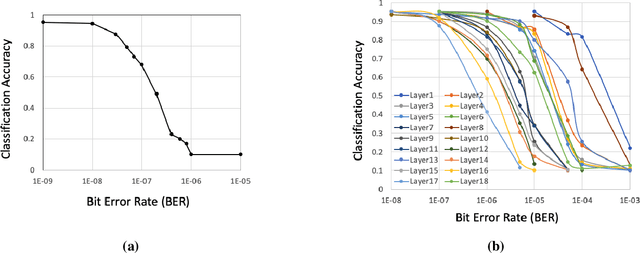
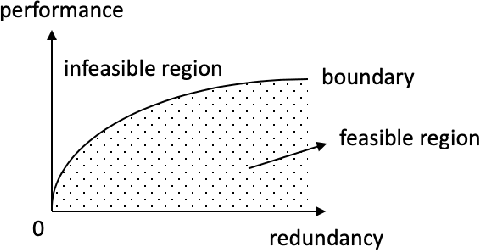
When neural networks (NeuralNets) are implemented in hardware, their weights need to be stored in memory devices. As noise accumulates in the stored weights, the NeuralNet's performance will degrade. This paper studies how to use error correcting codes (ECCs) to protect the weights. Different from classic error correction in data storage, the optimization objective is to optimize the NeuralNet's performance after error correction, instead of minimizing the Uncorrectable Bit Error Rate in the protected bits. That is, by seeing the NeuralNet as a function of its input, the error correction scheme is function-oriented. A main challenge is that a deep NeuralNet often has millions to hundreds of millions of weights, causing a large redundancy overhead for ECCs, and the relationship between the weights and its NeuralNet's performance can be highly complex. To address the challenge, we propose a Selective Protection (SP) scheme, which chooses only a subset of important bits for ECC protection. To find such bits and achieve an optimized tradeoff between ECC's redundancy and NeuralNet's performance, we present an algorithm based on deep reinforcement learning. Experimental results verify that compared to the natural baseline scheme, the proposed algorithm achieves substantially better performance for the functional error correction task.