 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrence without Recurrence: Stable Video Landmark Detection with Deep Equilibrium Models
Apr 02, 2023Cascaded computation, whereby predictions are recurrently refined over several stages, has been a persistent theme throughout the development of landmark detection models. In this work, we show that the recently proposed Deep Equilibrium Model (DEQ) can be naturally adapted to this form of computation. Our Landmark DEQ (LDEQ) achieves state-of-the-art performance on the challenging WFLW facial landmark dataset, reaching $3.92$ NME with fewer parameters and a training memory cost of $\mathcal{O}(1)$ in the number of recurrent modules. Furthermore, we show that DEQs are particularly suited for landmark detection in videos. In this setting, it is typical to train on still images due to the lack of labelled videos. This can lead to a ``flickering'' effect at inference time on video, whereby a model can rapidly oscillate between different plausible solutions across consecutive frames. By rephrasing DEQs as a constrained optimization, we emulate recurrence at inference time, despite not having access to temporal data at training time. This Recurrence without Recurrence (RwR) paradigm helps in reducing landmark flicker, which we demonstrate by introducing a new metric, normalized mean flicker (NMF), and contributing a new facial landmark video dataset (WFLW-V) targeting landmark uncertainty. On the WFLW-V hard subset made up of $500$ videos, our LDEQ with RwR improves the NME and NMF by $10$ and $13\%$ respectively, compared to the strongest previously published model using a hand-tuned conventional filter.
Non-greedy Gradient-based Hyperparameter Optimization Over Long Horizons
Jul 15, 2020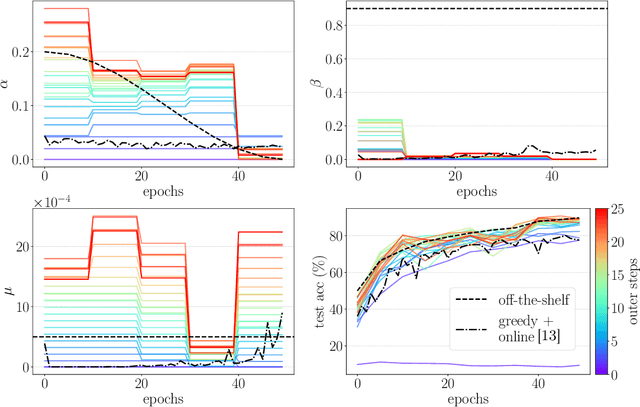
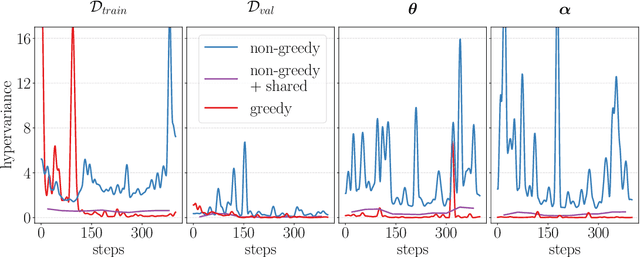
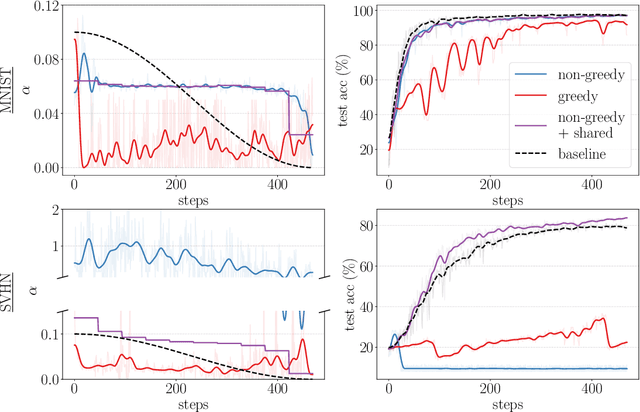
Gradient-based hyperparameter optimization is an attractive way to perform meta-learning across a distribution of tasks, or improve the performance of an optimizer on a single task. However, this approach has been unpopular for tasks requiring long horizons (many gradient steps), due to memory scaling and gradient degradation issues. A common workaround is to learn hyperparameters online or split the horizon into smaller chunks. However, this introduces greediness which comes with a large performance drop, since the best local hyperparameters can make for poor global solutions. In this work, we enable non-greediness over long horizons with a two-fold solution. First, we share hyperparameters that are contiguous in time, and show that this drastically mitigates gradient degradation issues. Then, we derive a forward-mode differentiation algorithm for the popular momentum-based SGD optimizer, which allows for a memory cost that is constant with horizon size. When put together, these solutions allow us to learn hyperparameters without any prior knowledge. Compared to the baseline of hand-tuned off-the-shelf hyperparameters, our method compares favorably on simple datasets like SVHN. On CIFAR-10 we match the baseline performance, and demonstrate for the first time that learning rate, momentum and weight decay schedules can be learned with gradients on a dataset of this size. Code is available at https://github.com/polo5/NonGreedyGradientHPO
Meta-Learning in Neural Networks: A Survey
Apr 11, 2020
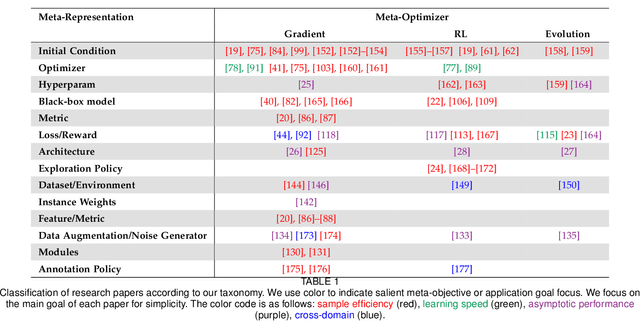
The field of meta-learning, or learning-to-learn, has seen a dramatic rise in interest in recent years. Contrary to conventional approaches to AI where a given task is solved from scratch using a fixed learning algorithm, meta-learning aims to improve the learning algorithm itself, given the experience of multiple learning episodes. This paradigm provides an opportunity to tackle many of the conventional challenges of deep learning, including data and computation bottlenecks, as well as the fundamental issue of generalization. In this survey we describe the contemporary meta-learning landscape. We first discuss definitions of meta-learning and position it with respect to related fields, such as transfer learning, multi-task learning, and hyperparameter optimization. We then propose a new taxonomy that provides a more comprehensive breakdown of the space of meta-learning methods today. We survey promising applications and successes of meta-learning including few-shot learning, reinforcement learning and architecture search. Finally, we discuss outstanding challenges and promising areas for future research.
Zero-shot Knowledge Transfer via Adversarial Belief Matching
May 24, 2019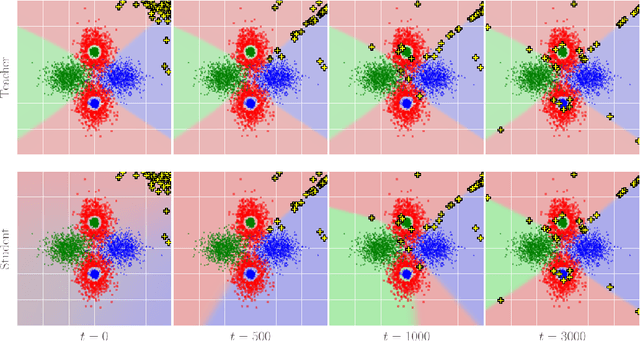

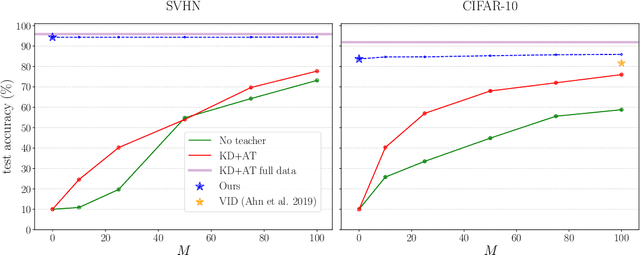

Performing knowledge transfer from a large teacher network to a smaller student is a popular task in modern deep learning applications. However, due to growing dataset sizes and stricter privacy regulations, it is increasingly common not to have access to the data that was used to train the teacher. We propose a novel method which trains a student to match the predictions of its teacher without using any data or metadata. We achieve this by training an adversarial generator to search for images on which the student poorly matches the teacher, and then using them to train the student. Our resulting student closely approximates its teacher for simple datasets like SVHN, and on CIFAR10 we improve on the state-of-the-art for few-shot distillation (with 100 images per class), despite using no data. Finally, we also propose a metric to quantify the degree of belief matching between teacher and student in the vicinity of decision boundaries, and observe a significantly higher match between our zero-shot student and the teacher, than between a student distilled with real data and the teacher. Code available at: https://github.com/polo5/ZeroShotKnowledgeTransfer