 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPC: A Benchmark Data Set for Learning with Graph-Structured Data
May 15, 2019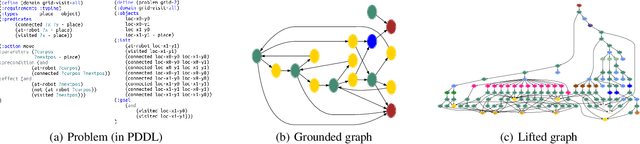
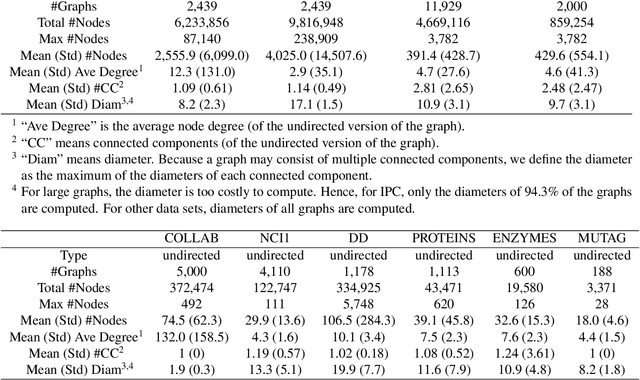
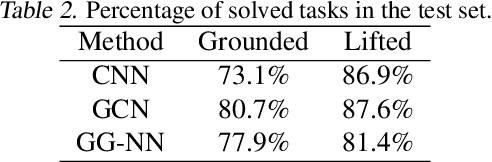
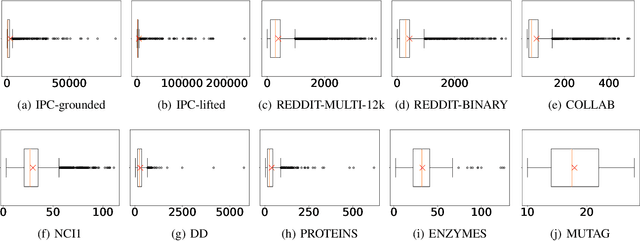
Benchmark data sets are an indispensable ingredient of the evaluation of graph-based machine learning methods. We release a new data set, compiled from International Planning Competitions (IPC), for benchmarking graph classification, regression, and related tasks. Apart from the graph construction (based on AI planning problems) that is interesting in its own right, the data set possesses distinctly different characteristics from popularly used benchmarks. The data set, named IPC, consists of two self-contained versions, grounded and lifted, both including graphs of large and skewedly distributed sizes, posing substantial challenges for the computation of graph models such as graph kernels and graph neural networks. The graphs in this data set are directed and the lifted version is acyclic, offering the opportunity of benchmarking specialized models for directed (acyclic) structures. Moreover, the graph generator and the labeling are computer programmed; thus, the data set may be extended easily if a larger scale is desired. The data set is accessible from \url{https://github.com/IBM/IPC-graph-data}.
Adaptive Planner Scheduling with Graph Neural Networks
Nov 03, 2018

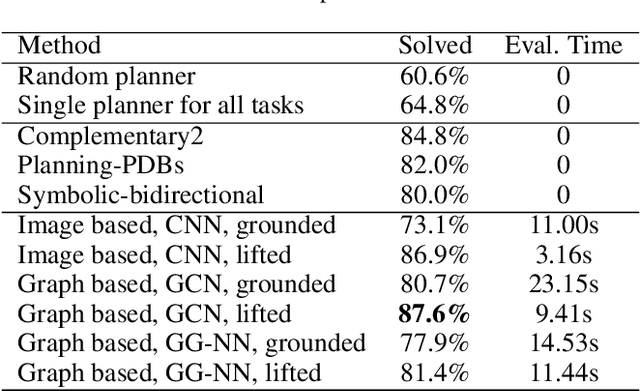

Automated planning is one of the foundational areas of AI. Since a single planner unlikely works well for all tasks and domains, portfolio-based techniques become increasingly popular recently. In particular, deep learning emerges as a promising methodology for online planner selection. Owing to the recent development of structural graph representations of planning tasks, we propose a graph neural network (GNN) approach to selecting candidate planners. GNNs are advantageous over a straightforward alternative, the convolutional neural networks, in that they are invariant to node permutations and that they incorporate node labels for better inference. Additionally, for cost-optimal planning, we propose a two-stage adaptive scheduling method to further improve the likelihood that a given task is solved in time. The scheduler may switch at halftime to a different planner, conditioned on the observed performance of the first one. Experimental results validate the effectiveness of the proposed method against strong baselines, both deep learning and non-deep learning based.