 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMM-COMET: Continual Source-Free Universal Domain Adaptation via a Mean Teacher and Gaussian Mixture Model-Based Pseudo-Labeling
Jan 16, 2026Unsupervised domain adaptation tackles the problem that domain shifts between training and test data impair the performance of neural networks in many real-world applications. Thereby, in realistic scenarios, the source data may no longer be available during adaptation, and the label space of the target domain may differ from the source label space. This setting, known as source-free universal domain adaptation (SF-UniDA), has recently gained attention, but all existing approaches only assume a single domain shift from source to target. In this work, we present the first study on continual SF-UniDA, where the model must adapt sequentially to a stream of multiple different unlabeled target domains. Building upon our previous methods for online SF-UniDA, we combine their key ideas by integrating Gaussian mixture model-based pseudo-labeling within a mean teacher framework for improved stability over long adaptation sequences. Additionally, we introduce consistency losses for further robustness. The resulting method GMM-COMET provides a strong first baseline for continual SF-UniDA and is the only approach in our experiments to consistently improve upon the source-only model across all evaluated scenarios. Our code is available at https://github.com/pascalschlachter/GMM-COMET.
Analysis of Pseudo-Labeling for Online Source-Free Universal Domain Adaptation
Apr 16, 2025A domain (distribution) shift between training and test data often hinders the real-world performance of deep neural networks, necessitating unsupervised domain adaptation (UDA) to bridge this gap. Online source-free UDA has emerged as a solution for practical scenarios where access to source data is restricted and target data is received as a continuous stream. However, the open-world nature of many real-world applications additionally introduces category shifts meaning that the source and target label spaces may differ. Online source-free universal domain adaptation (SF-UniDA) addresses this challenge. Existing methods mainly rely on self-training with pseudo-labels, yet the relationship between pseudo-labeling and adaptation outcomes has not been studied yet. To bridge this gap, we conduct a systematic analysis through controlled experiments with simulated pseudo-labeling, offering valuable insights into pseudo-labeling for online SF-UniDA. Our findings reveal a substantial gap between the current state-of-the-art and the upper bound of adaptation achieved with perfect pseudo-labeling. Moreover, we show that a contrastive loss enables effective adaptation even with moderate pseudo-label accuracy, while a cross-entropy loss, though less robust to pseudo-label errors, achieves superior results when pseudo-labeling approaches perfection. Lastly, our findings indicate that pseudo-label accuracy is in general more crucial than quantity, suggesting that prioritizing fewer but high-confidence pseudo-labels is beneficial. Overall, our study highlights the critical role of pseudo-labeling in (online) SF-UniDA and provides actionable insights to drive future advancements in the field. Our code is available at https://github.com/pascalschlachter/PLAnalysis.
Memory-Efficient Pseudo-Labeling for Online Source-Free Universal Domain Adaptation using a Gaussian Mixture Model
Jul 19, 2024



In practice, domain shifts are likely to occur between training and test data, necessitating domain adaptation (DA) to adjust the pre-trained source model to the target domain. Recently, universal domain adaptation (UniDA) has gained attention for addressing the possibility of an additional category (label) shift between the source and target domain. This means new classes can appear in the target data, some source classes may no longer be present, or both at the same time. For practical applicability, UniDA methods must handle both source-free and online scenarios, enabling adaptation without access to the source data and performing batch-wise updates in parallel with prediction. In an online setting, preserving knowledge across batches is crucial. However, existing methods often require substantial memory, e.g. by using memory queues, which is impractical because memory is limited and valuable, in particular on embedded systems. Therefore, we consider memory-efficiency as an additional constraint in this paper. To achieve memory-efficient online source-free universal domain adaptation (SF-UniDA), we propose a novel method that continuously captures the distribution of known classes in the feature space using a Gaussian mixture model (GMM). This approach, combined with entropy-based out-of-distribution detection, allows for the generation of reliable pseudo-labels. Finally, we combine a contrastive loss with a KL divergence loss to perform the adaptation. Our approach not only achieves state-of-the-art results in all experiments on the DomainNet dataset but also significantly outperforms the existing methods on the challenging VisDA-C dataset, setting a new benchmark for online SF-UniDA. Our code is available at https://github.com/pascalschlachter/GMM.
COMET: Contrastive Mean Teacher for Online Source-Free Universal Domain Adaptation
Jan 31, 2024



In real-world applications, there is often a domain shift from training to test data. This observation resulted in the development of test-time adaptation (TTA). It aims to adapt a pre-trained source model to the test data without requiring access to the source data. Thereby, most existing works are limited to the closed-set assumption, i.e. there is no category shift between source and target domain. We argue that in a realistic open-world setting a category shift can appear in addition to a domain shift. This means, individual source classes may not appear in the target domain anymore, samples of new classes may be part of the target domain or even both at the same time. Moreover, in many real-world scenarios the test data is not accessible all at once but arrives sequentially as a stream of batches demanding an immediate prediction. Hence, TTA must be applied in an online manner. To the best of our knowledge, the combination of these aspects, i.e. online source-free universal domain adaptation (online SF-UniDA), has not been studied yet. In this paper, we introduce a Contrastive Mean Teacher (COMET) tailored to this novel scenario. It applies a contrastive loss to rebuild a feature space where the samples of known classes build distinct clusters and the samples of new classes separate well from them. It is complemented by an entropy loss which ensures that the classifier output has a small entropy for samples of known classes and a large entropy for samples of new classes to be easily detected and rejected as unknown. To provide the losses with reliable pseudo labels, they are embedded into a mean teacher (MT) framework. We evaluate our method across two datasets and all category shifts to set an initial benchmark for online SF-UniDA. Thereby, COMET yields state-of-the-art performance and proves to be consistent and robust across a variety of different scenarios.
Indoor Positioning based on Active Radar Sensing and Passive Reflectors: Concepts & Initial Results
Oct 06, 2023
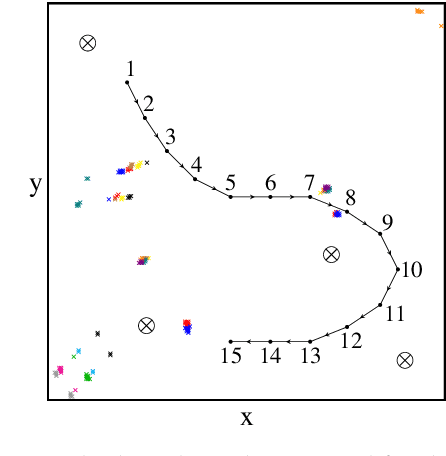
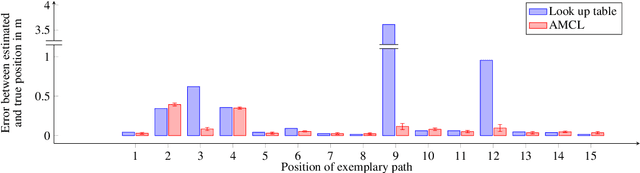
To navigate reliably in indoor environments, an industrial autonomous vehicle must know its position. However, current indoor vehicle positioning technologies either lack accuracy, usability or are too expensive. Thus, we propose a novel concept called local reference point assisted active radar positioning, which is able to overcome these drawbacks. It is based on distributing passive retroreflectors in the indoor environment such that each position of the vehicle can be identified by a unique reflection characteristic regarding the reflectors. To observe these characteristics, the autonomous vehicle is equipped with an active radar system. On one hand, this paper presents the basic idea and concept of our new approach towards indoor vehicle positioning and especially focuses on the crucial placement of the reflectors. On the other hand, it also provides a proof of concept by conducting a full system simulation including the placement of the local reference points, the radar-based distance estimation and the comparison of two different positioning methods. It successfully demonstrates the feasibility of our proposed approach.