 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable speech synthesis by learning discrete phoneme-level prosodic representations
Nov 29, 2022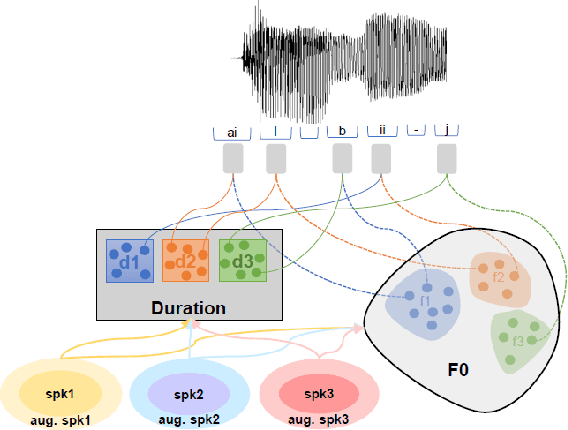
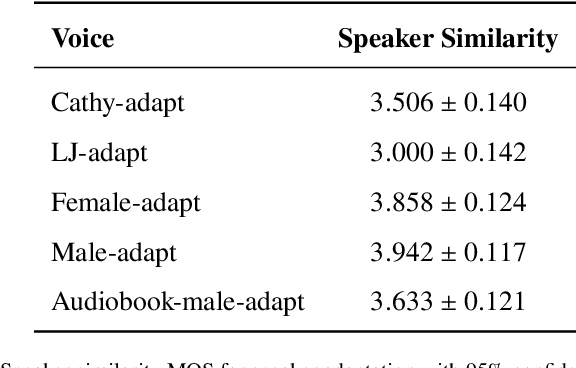
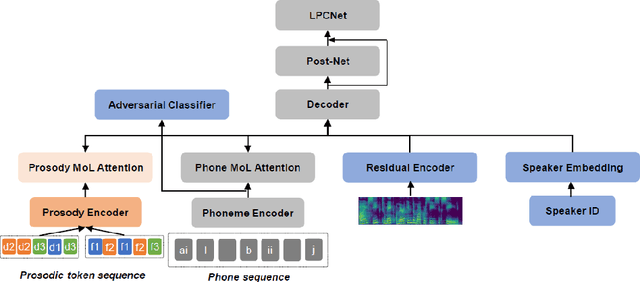
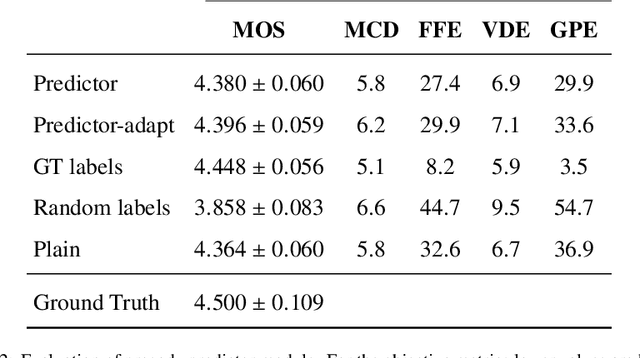
In this paper, we present a novel method for phoneme-level prosody control of F0 and duration using intuitive discrete labels. We propose an unsupervised prosodic clustering process which is used to discretize phoneme-level F0 and duration features from a multispeaker speech dataset. These features are fed as an input sequence of prosodic labels to a prosody encoder module which augments an autoregressive attention-based text-to-speech model. We utilize various methods in order to improve prosodic control range and coverage, such as augmentation, F0 normalization, balanced clustering for duration and speaker-independent clustering. The final model enables fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. Instead of relying on reference utterances for inference, we introduce a prior prosody encoder which learns the style of each speaker and enables speech synthesis without the requirement of reference audio. We also fine-tune the multispeaker model to unseen speakers with limited amounts of data, as a realistic application scenario and show that the prosody control capabilities are maintained, verifying that the speaker-independent prosodic clustering is effective. Experimental results show that the model has high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.