 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Gradient Flows with Provable Fixed-Time Convergence and Fast Evasion of Non-Degenerate Saddle Points
Dec 07, 2022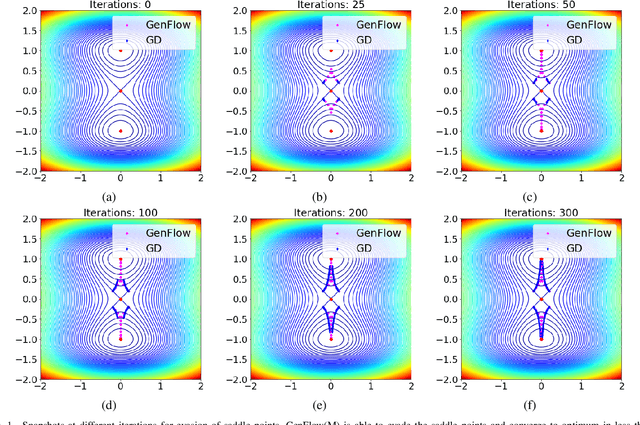
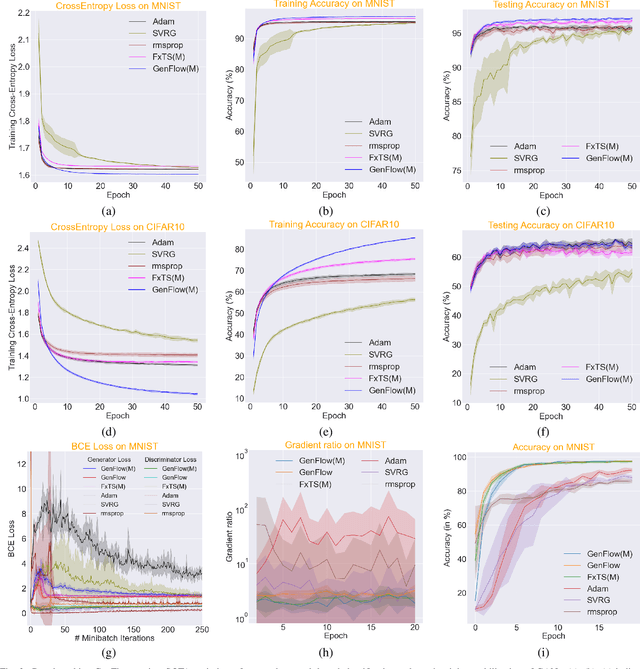

Gradient-based first-order convex optimization algorithms find widespread applicability in a variety of domains, including machine learning tasks. Motivated by the recent advances in fixed-time stability theory of continuous-time dynamical systems, we introduce a generalized framework for designing accelerated optimization algorithms with strongest convergence guarantees that further extend to a subclass of non-convex functions. In particular, we introduce the \emph{GenFlow} algorithm and its momentum variant that provably converge to the optimal solution of objective functions satisfying the Polyak-{\L}ojasiewicz (PL) inequality, in a fixed-time. Moreover for functions that admit non-degenerate saddle-points, we show that for the proposed GenFlow algorithm, the time required to evade these saddle-points is bounded uniformly for all initial conditions. Finally, for strongly convex-strongly concave minimax problems whose optimal solution is a saddle point, a similar scheme is shown to arrive at the optimal solution again in a fixed-time. The superior convergence properties of our algorithm are validated experimentally on a variety of benchmark datasets.
Breaking the Convergence Barrier: Optimization via Fixed-Time Convergent Flows
Dec 02, 2021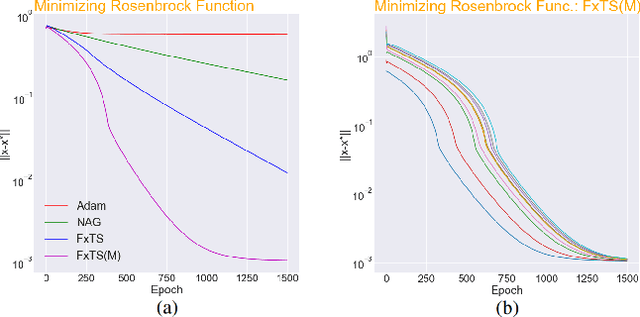
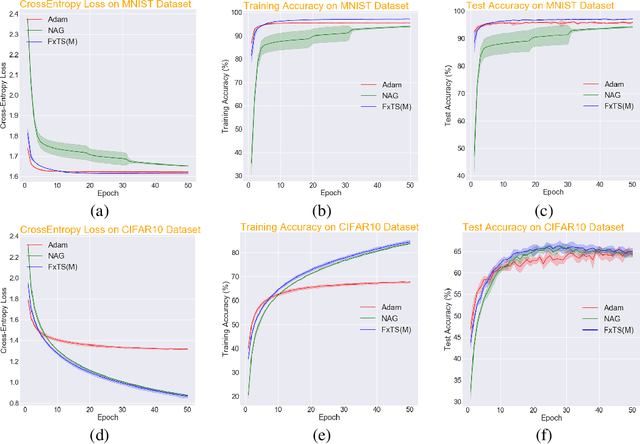
Accelerated gradient methods are the cornerstones of large-scale, data-driven optimization problems that arise naturally in machine learning and other fields concerning data analysis. We introduce a gradient-based optimization framework for achieving acceleration, based on the recently introduced notion of fixed-time stability of dynamical systems. The method presents itself as a generalization of simple gradient-based methods suitably scaled to achieve convergence to the optimizer in a fixed-time, independent of the initialization. We achieve this by first leveraging a continuous-time framework for designing fixed-time stable dynamical systems, and later providing a consistent discretization strategy, such that the equivalent discrete-time algorithm tracks the optimizer in a practically fixed number of iterations. We also provide a theoretical analysis of the convergence behavior of the proposed gradient flows, and their robustness to additive disturbances for a range of functions obeying strong convexity, strict convexity, and possibly nonconvexity but satisfying the Polyak-{\L}ojasiewicz inequality. We also show that the regret bound on the convergence rate is constant by virtue of the fixed-time convergence. The hyperparameters have intuitive interpretations and can be tuned to fit the requirements on the desired convergence rates. We validate the accelerated convergence properties of the proposed schemes on a range of numerical examples against the state-of-the-art optimization algorithms. Our work provides insights on developing novel optimization algorithms via discretization of continuous-time flows.