 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Device and Behavioral Heterogeneity in Federated Learning
Feb 15, 2021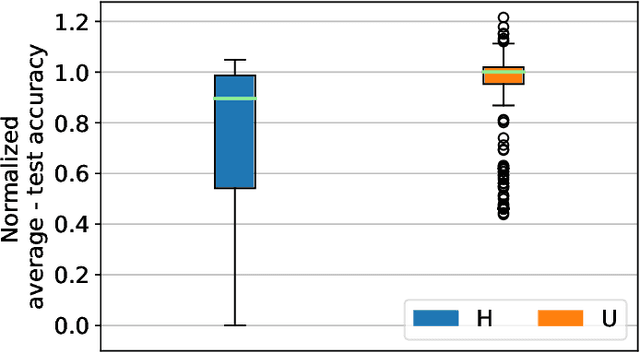

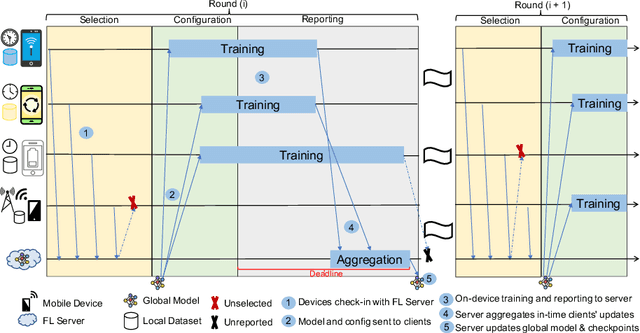
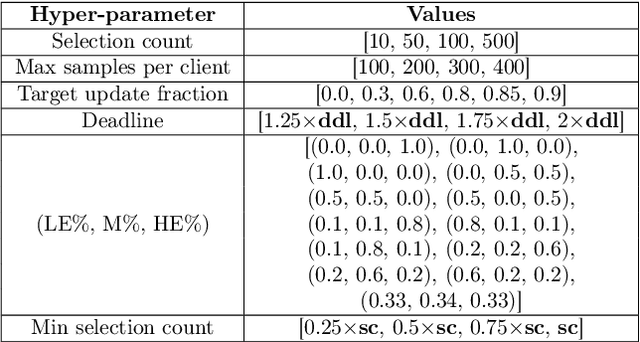
Federated learning (FL) is becoming a popular paradigm for collaborative learning over distributed, private datasets owned by non-trusting entities. FL has seen successful deployment in production environments, and it has been adopted in services such as virtual keyboards, auto-completion, item recommendation, and several IoT applications. However, FL comes with the challenge of performing training over largely heterogeneous datasets, devices, and networks that are out of the control of the centralized FL server. Motivated by this inherent setting, we make a first step towards characterizing the impact of device and behavioral heterogeneity on the trained model. We conduct an extensive empirical study spanning close to 1.5K unique configurations on five popular FL benchmarks. Our analysis shows that these sources of heterogeneity have a major impact on both model performance and fairness, thus sheds light on the importance of considering heterogeneity in FL system design.