 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Body Video-Based Self-Avatars for Mixed Reality: from E2E System to User Study
Aug 24, 2022

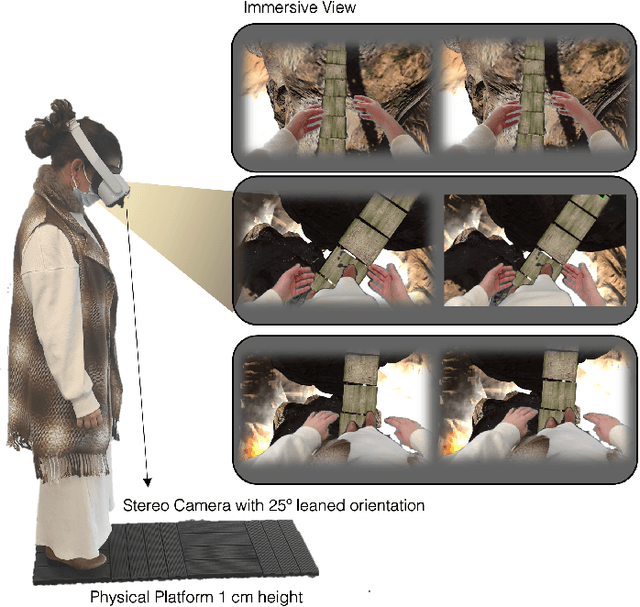
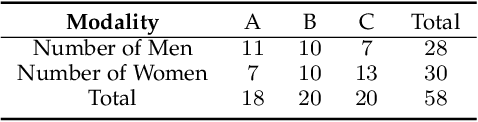
In this work we explore the creation of self-avatars through video pass-through in Mixed Reality (MR) applications. We present our end-to-end system, including: custom MR video pass-through implementation on a commercial head mounted display (HMD), our deep learning-based real-time egocentric body segmentation algorithm, and our optimized offloading architecture, to communicate the segmentation server with the HMD. To validate this technology, we designed an immersive VR experience where the user has to walk through a narrow tiles path over an active volcano crater. The study was performed under three body representation conditions: virtual hands, video pass-through with color-based full-body segmentation and video pass-through with deep learning full-body segmentation. This immersive experience was carried out by 30 women and 28 men. To the best of our knowledge, this is the first user study focused on evaluating video-based self-avatars to represent the user in a MR scene. Results showed no significant differences between the different body representations in terms of presence, with moderate improvements in some Embodiment components between the virtual hands and full-body representations. Visual Quality results showed better results from the deep-learning algorithms in terms of the whole body perception and overall segmentation quality. We provide some discussion regarding the use of video-based self-avatars, and some reflections on the evaluation methodology. The proposed E2E solution is in the boundary of the state of the art, so there is still room for improvement before it reaches maturity. However, this solution serves as a crucial starting point for novel MR distributed solutions.
Real Time Egocentric Segmentation for Video-self Avatar in Mixed Reality
Jul 04, 2022
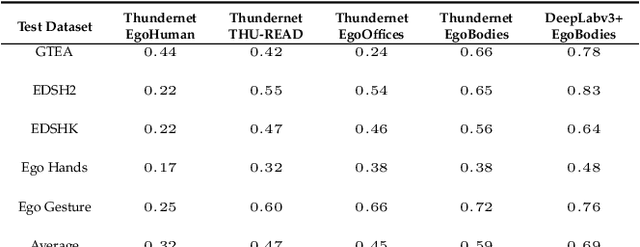
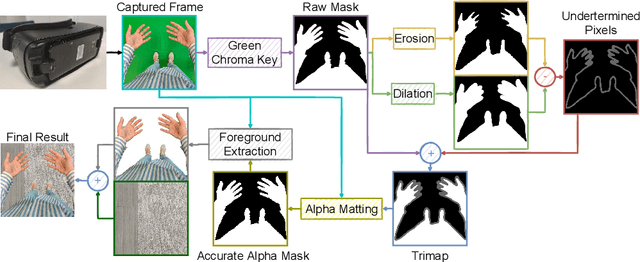

In this work we present our real-time egocentric body segmentation algorithm. Our algorithm achieves a frame rate of 66 fps for an input resolution of 640x480, thanks to our shallow network inspired in Thundernet's architecture. Besides, we put a strong emphasis on the variability of the training data. More concretely, we describe the creation process of our Egocentric Bodies (EgoBodies) dataset, composed of almost 10,000 images from three datasets, created both from synthetic methods and real capturing. We conduct experiments to understand the contribution of the individual datasets; compare Thundernet model trained with EgoBodies with simpler and more complex previous approaches and discuss their corresponding performance in a real-life setup in terms of segmentation quality and inference times. The described trained semantic segmentation algorithm is already integrated in an end-to-end system for Mixed Reality (MR), making it possible for users to see his/her own body while being immersed in a MR scene.
Enhanced Self-Perception in Mixed Reality: Egocentric Arm Segmentation and Database with Automatic Labelling
Mar 27, 2020



In this study, we focus on the egocentric segmentation of arms to improve self-perception in Augmented Virtuality (AV). The main contributions of this work are: i) a comprehensive survey of segmentation algorithms for AV; ii) an Egocentric Arm Segmentation Dataset, composed of more than 10, 000 images, comprising variations of skin color, and gender, among others. We provide all details required for the automated generation of groundtruth and semi-synthetic images; iii) the use of deep learning for the first time for segmenting arms in AV; iv) to showcase the usefulness of this database, we report results on different real egocentric hand datasets, including GTEA Gaze+, EDSH, EgoHands, Ego Youtube Hands, THU-Read, TEgO, FPAB, and Ego Gesture, which allow for direct comparisons with existing approaches utilizing color or depth. Results confirm the suitability of the EgoArm dataset for this task, achieving improvement up to 40% with respect to the original network, depending on the particular dataset. Results also suggest that, while approaches based on color or depth can work in controlled conditions (lack of occlusion, uniform lighting, only objects of interest in the near range, controlled background, etc.), egocentric segmentation based on deep learning is more robust in real AV applications.