 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: Glare or Gloom, I Can Still See You -- End-to-End Multimodal Object Detector
Feb 24, 2021
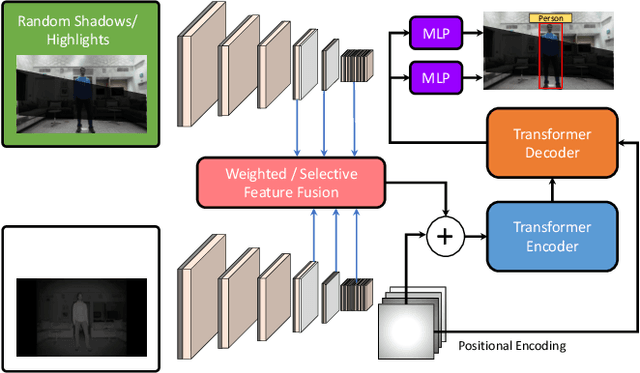
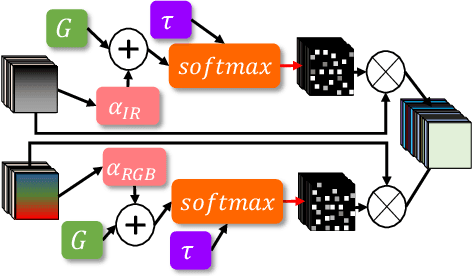
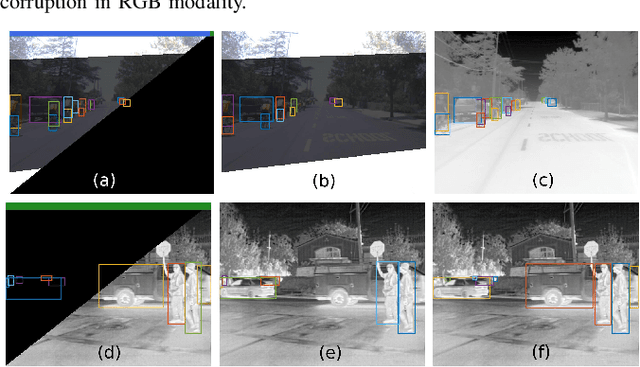
Deep neural networks designed for vision tasks are often prone to failure when they encounter environmental conditions not covered by the training data. Efficient fusion strategies for multi-sensor configurations can enhance the robustness of the detection algorithms by exploiting redundancy from different sensor streams. In this paper, we propose sensor-aware multi-modal fusion strategies for 2D object detection in harsh-lighting conditions. Our network learns to estimate the measurement reliability of each sensor modality in the form of scalar weights and masks, without prior knowledge of the sensor characteristics. The obtained weights are assigned to the extracted feature maps which are subsequently fused and passed to the transformer encoder-decoder network for object detection. This is critical in the case of asymmetric sensor failures and to prevent any tragic consequences. Through extensive experimentation, we show that the proposed strategies out-perform the existing state-of-the-art methods on the FLIR-Thermal dataset, improving the mAP up-to 25.2%. We also propose a new "r-blended" hybrid depth modality for RGB-D multi-modal detection tasks. Our proposed method also obtained promising results on the SUNRGB-D dataset.
Random Shadows and Highlights: A new data augmentation method for extreme lighting conditions
Jan 18, 2021
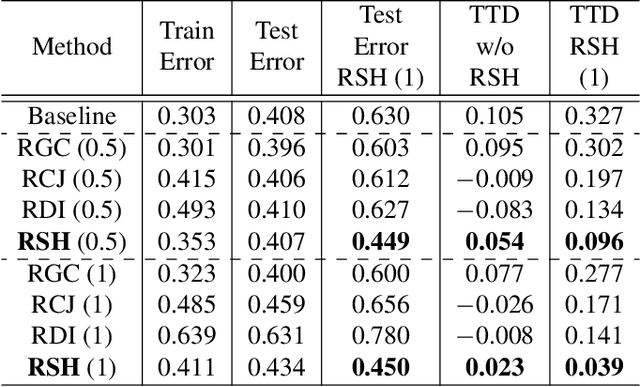
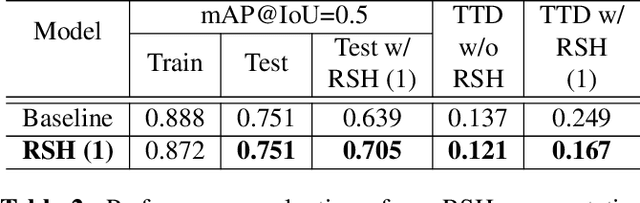
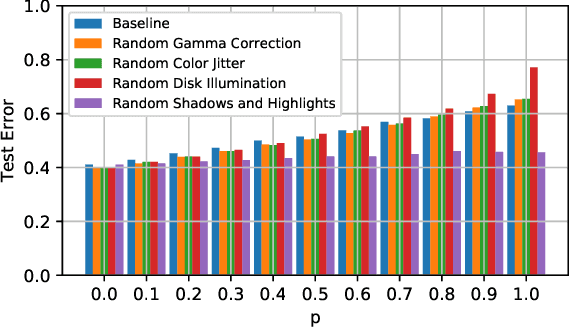
In this paper, we propose a new data augmentation method, Random Shadows and Highlights (RSH) to acquire robustness against lighting perturbations. Our method creates random shadows and highlights on images, thus challenging the neural network during the learning process such that it acquires immunity against such input corruptions in real world applications. It is a parameter-learning free method which can be integrated into most vision related learning applications effortlessly. With extensive experimentation, we demonstrate that RSH not only increases the robustness of the models against lighting perturbations, but also reduces over-fitting significantly. Thus RSH should be considered essential for all vision related learning systems. Code is available at: https://github.com/OsamaMazhar/Random-Shadows-Highlights.
A Deep Learning Framework for Recognizing both Static and Dynamic Gestures
Jun 11, 2020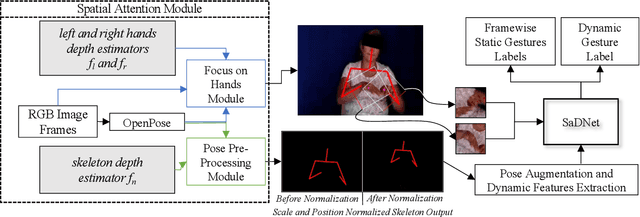
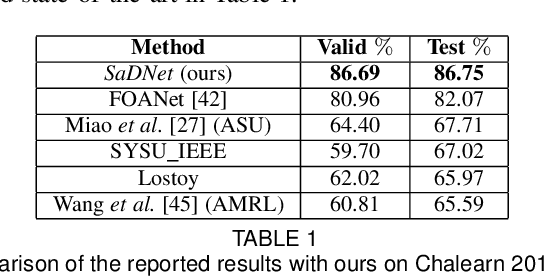


Intuitive user interfaces are indispensable to interact with human centric smart environments. In this paper, we propose a unified framework that recognizes both static and dynamic gestures, using simple RGB vision (without depth sensing). This feature makes it suitable for inexpensive human-machine interaction (HMI). We rely on a spatial attention-based strategy, which employs SaDNet, our proposed Static and Dynamic gestures Network. From the image of the human upper body, we estimate his/her depth, along with the region-of-interest around his/her hands. The Convolutional Neural Networks in SaDNet are fine-tuned on a background-substituted hand gestures dataset. They are utilized to detect 10 static gestures for each hand and to obtain hand image-embeddings from the last Fully Connected layer, which are subsequently fused with the augmented pose vector and then passed to stacked Long Short-Term Memory blocks. Thus, human-centered frame-wise information from the augmented pose vector and left/right hands image-embeddings are aggregated in time to predict the dynamic gestures of the performing person. In a number of experiments we show that the proposed approach surpasses the state-of-the-art results on large-scale Chalearn 2016 dataset. Moreover, we also transfer the knowledge learned through the proposed methodology to the Praxis gestures dataset, and the obtained results also outscore the state-of-the-art on this dataset.