 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDealing with Drift of Adaptation Spaces in Learning-based Self-Adaptive Systems using Lifelong Self-Adaptation
Nov 04, 2022Recently, machine learning (ML) has become a popular approach to support self-adaptation. ML has been used to deal with several problems in self-adaptation, such as maintaining an up-to-date runtime model under uncertainty and scalable decision-making. Yet, exploiting ML comes with inherent challenges. In this paper, we focus on a particularly important challenge for learning-based self-adaptive systems: drift in adaptation spaces. With adaptation space we refer to the set of adaptation options a self-adaptive system can select from at a given time to adapt based on the estimated quality properties of the adaptation options. Drift of adaptation spaces originates from uncertainties, affecting the quality properties of the adaptation options. Such drift may imply that eventually no adaptation option can satisfy the initial set of the adaptation goals, deteriorating the quality of the system, or adaptation options may emerge that allow enhancing the adaptation goals. In ML, such shift corresponds to novel class appearance, a type of concept drift in target data that common ML techniques have problems dealing with. To tackle this problem, we present a novel approach to self-adaptation that enhances learning-based self-adaptive systems with a lifelong ML layer. We refer to this approach as lifelong self-adaptation. The lifelong ML layer tracks the system and its environment, associates this knowledge with the current tasks, identifies new tasks based on differences, and updates the learning models of the self-adaptive system accordingly. A human stakeholder may be involved to support the learning process and adjust the learning and goal models. We present a reusable architecture for lifelong self-adaptation and apply it to the case of drift of adaptation spaces that affects the decision-making in self-adaptation. We validate the approach for a series of scenarios using the DeltaIoT exemplar.
Deep Learning for Effective and Efficient Reduction of Large Adaptation Spaces in Self-Adaptive Systems
Apr 13, 2022


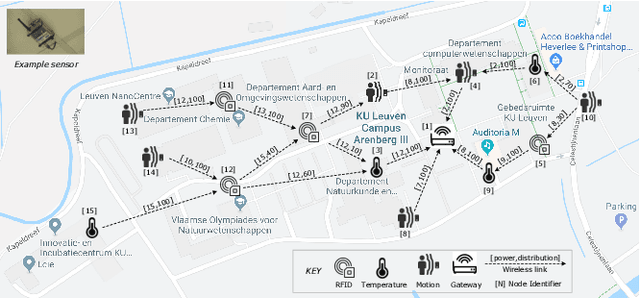
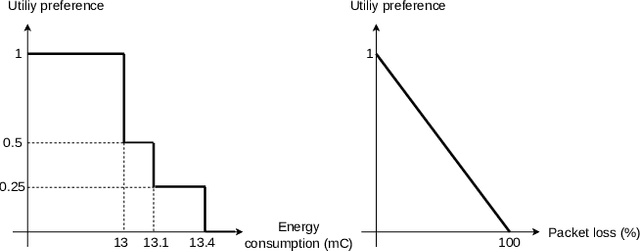
Many software systems today face uncertain operating conditions, such as sudden changes in the availability of resources or unexpected user behavior. Without proper mitigation these uncertainties can jeopardize the system goals. Self-adaptation is a common approach to tackle such uncertainties. When the system goals may be compromised, the self-adaptive system has to select the best adaptation option to reconfigure by analyzing the possible adaptation options, i.e., the adaptation space. Yet, analyzing large adaptation spaces using rigorous methods can be resource- and time-consuming, or even be infeasible. One approach to tackle this problem is by using online machine learning to reduce adaptation spaces. However, existing approaches require domain expertise to perform feature engineering to define the learner, and support online adaptation space reduction only for specific goals. To tackle these limitations, we present 'Deep Learning for Adaptation Space Reduction Plus' -- DLASeR+ in short. DLASeR+ offers an extendable learning framework for online adaptation space reduction that does not require feature engineering, while supporting three common types of adaptation goals: threshold, optimization, and set-point goals. We evaluate DLASeR+ on two instances of an Internet-of-Things application with increasing sizes of adaptation spaces for different combinations of adaptation goals. We compare DLASeR+ with a baseline that applies exhaustive analysis and two state-of-the-art approaches for adaptation space reduction that rely on learning. Results show that DLASeR+ is effective with a negligible effect on the realization of the adaptation goals compared to an exhaustive analysis approach, and supports three common types of adaptation goals beyond the state-of-the-art approaches.
Lifelong Self-Adaptation: Self-Adaptation Meets Lifelong Machine Learning
Apr 04, 2022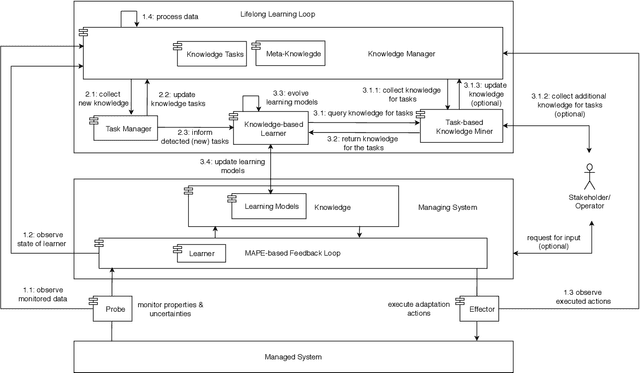
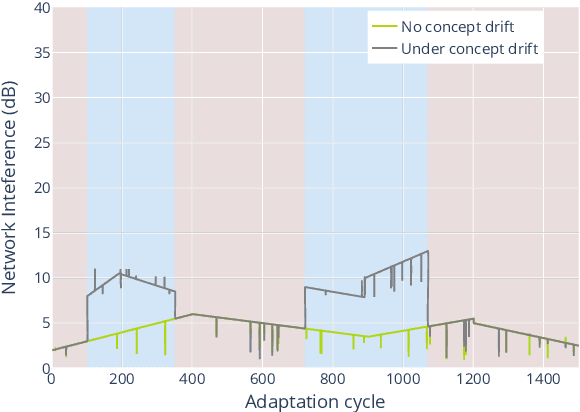
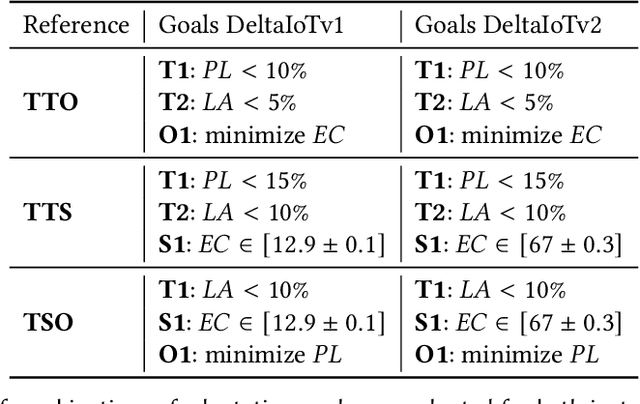
In the past years, machine learning (ML) has become a popular approach to support self-adaptation. While ML techniques enable dealing with several problems in self-adaptation, such as scalable decision-making, they are also subject to inherent challenges. In this paper, we focus on one such challenge that is particularly important for self-adaptation: ML techniques are designed to deal with a set of predefined tasks associated with an operational domain; they have problems to deal with new emerging tasks, such as concept shift in input data that is used for learning. To tackle this challenge, we present \textit{lifelong self-adaptation}: a novel approach to self-adaptation that enhances self-adaptive systems that use ML techniques with a lifelong ML layer. The lifelong ML layer tracks the running system and its environment, associates this knowledge with the current tasks, identifies new tasks based on differentiations, and updates the learning models of the self-adaptive system accordingly. We present a reusable architecture for lifelong self-adaptation and apply it to the case of concept drift caused by unforeseen changes of the input data of a learning model that is used for decision-making in self-adaptation. We validate lifelong self-adaptation for two types of concept drift using two cases.
On the Impact of Applying Machine Learning in the Decision-Making of Self-Adaptive Systems
Mar 18, 2021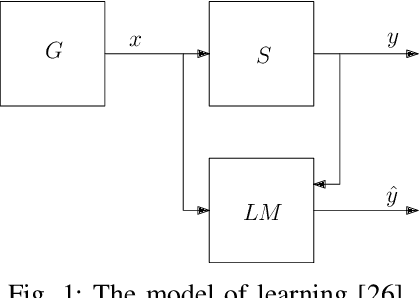



Recently, we have been witnessing an increasing use of machine learning methods in self-adaptive systems. Machine learning methods offer a variety of use cases for supporting self-adaptation, e.g., to keep runtime models up to date, reduce large adaptation spaces, or update adaptation rules. Yet, since machine learning methods apply in essence statistical methods, they may have an impact on the decisions made by a self-adaptive system. Given the wide use of formal approaches to provide guarantees for the decisions made by self-adaptive systems, it is important to investigate the impact of applying machine learning methods when such approaches are used. In this paper, we study one particular instance that combines linear regression to reduce the adaptation space of a self-adaptive system with statistical model checking to analyze the resulting adaptation options. We use computational learning theory to determine a theoretical bound on the impact of the machine learning method on the predictions made by the verifier. We illustrate and evaluate the theoretical result using a scenario of the DeltaIoT artifact. To conclude, we look at opportunities for future research in this area.
Applying Machine Learning in Self-Adaptive Systems: A Systematic Literature Review
Mar 06, 2021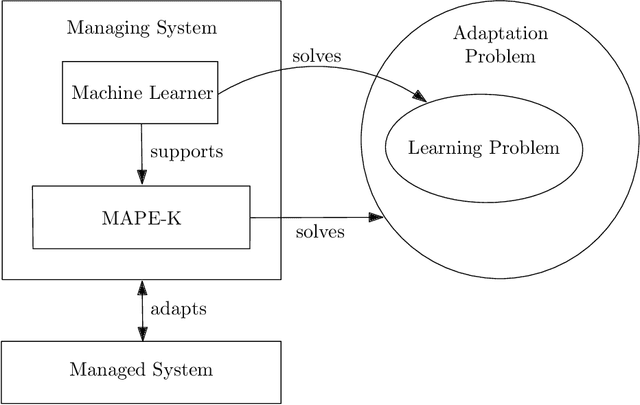
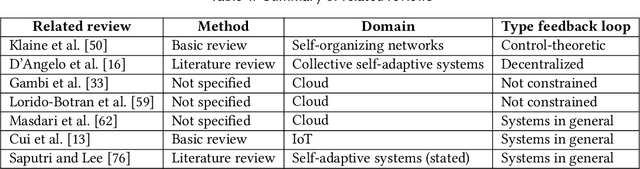
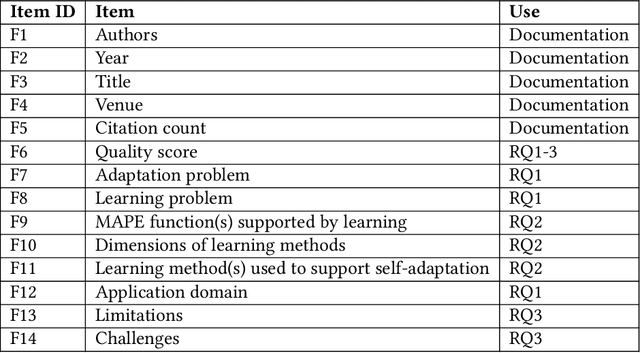
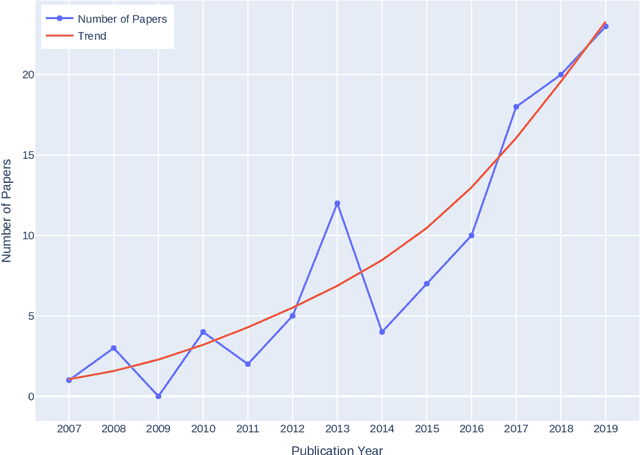
Recently, we witness a rapid increase in the use of machine learning in self-adaptive systems. Machine learning has been used for a variety of reasons, ranging from learning a model of the environment of a system during operation to filtering large sets of possible configurations before analysing them. While a body of work on the use of machine learning in self-adaptive systems exists, there is currently no systematic overview of this area. Such overview is important for researchers to understand the state of the art and direct future research efforts. This paper reports the results of a systematic literature review that aims at providing such an overview. We focus on self-adaptive systems that are based on a traditional Monitor-Analyze-Plan-Execute feedback loop (MAPE). The research questions are centred on the problems that motivate the use of machine learning in self-adaptive systems, the key engineering aspects of learning in self-adaptation, and open challenges. The search resulted in 6709 papers, of which 109 were retained for data collection. Analysis of the collected data shows that machine learning is mostly used for updating adaptation rules and policies to improve system qualities, and managing resources to better balance qualities and resources. These problems are primarily solved using supervised and interactive learning with classification, regression and reinforcement learning as the dominant methods. Surprisingly, unsupervised learning that naturally fits automation is only applied in a small number of studies. Key open challenges in this area include the performance of learning, managing the effects of learning, and dealing with more complex types of goals. From the insights derived from this systematic literature review we outline an initial design process for applying machine learning in self-adaptive systems that are based on MAPE feedback loops.