 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian batch normalization for SPD neural networks
Sep 12, 2019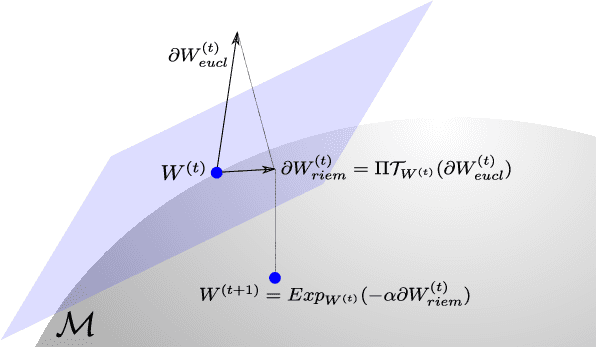

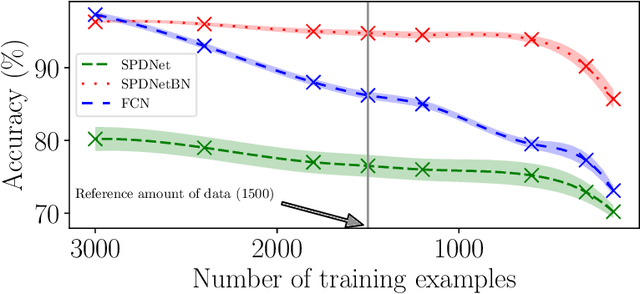

Covariance matrices have attracted attention for machine learning applications due to their capacity to capture interesting structure in the data. The main challenge is that one needs to take into account the particular geometry of the Riemannian manifold of symmetric positive definite (SPD) matrices they belong to. In the context of deep networks, several architectures for these matrices have recently been proposed. In our article, we introduce a Riemannian batch normalization (batchnorm) algorithm, which generalizes the one used in Euclidean nets. This novel layer makes use of geometric operations on the manifold, notably the Riemannian barycenter, parallel transport and non-linear structured matrix transformations. We derive a new manifold-constrained gradient descent algorithm working in the space of SPD matrices, allowing to learn the batchnorm layer. We validate our proposed approach with experiments in three different contexts on diverse data types: a drone recognition dataset from radar observations, and on emotion and action recognition datasets from video and motion capture data. Experiments show that the Riemannian batchnorm systematically gives better classification performance compared with leading methods and a remarkable robustness to lack of data.
Stochastic Adaptive Neural Architecture Search for Keyword Spotting
Nov 16, 2018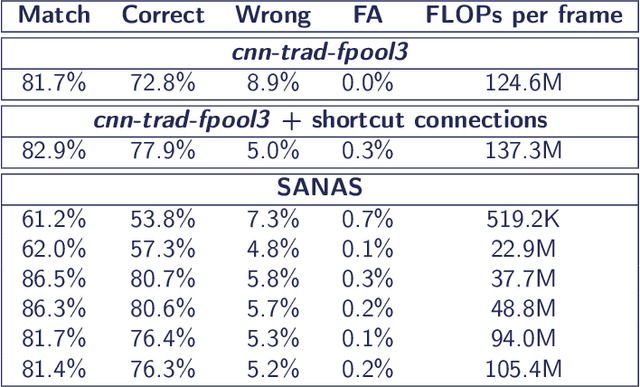
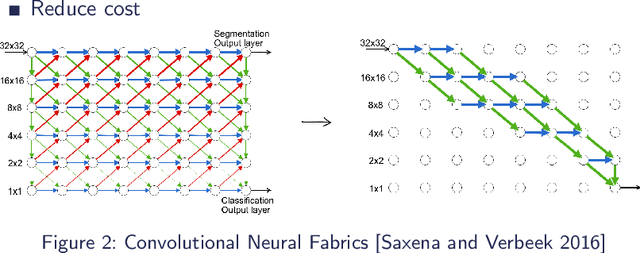
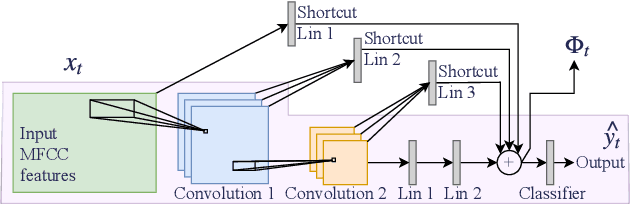
The problem of keyword spotting i.e. identifying keywords in a real-time audio stream is mainly solved by applying a neural network over successive sliding windows. Due to the difficulty of the task, baseline models are usually large, resulting in a high computational cost and energy consumption level. We propose a new method called SANAS (Stochastic Adaptive Neural Architecture Search) which is able to adapt the architecture of the neural network on-the-fly at inference time such that small architectures will be used when the stream is easy to process (silence, low noise, ...) and bigger networks will be used when the task becomes more difficult. We show that this adaptive model can be learned end-to-end by optimizing a trade-off between the prediction performance and the average computational cost per unit of time. Experiments on the Speech Commands dataset show that this approach leads to a high recognition level while being much faster (and/or energy saving) than classical approaches where the network architecture is static.