 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net Transformer: Self and Cross Attention for Medical Image Segmentation
Mar 12, 2021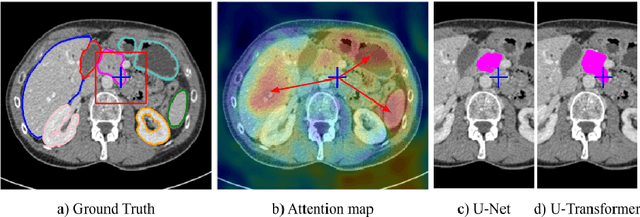


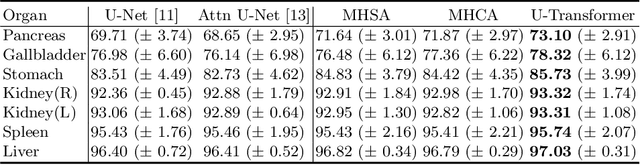
Medical image segmentation remains particularly challenging for complex and low-contrast anatomical structures. In this paper, we introduce the U-Transformer network, which combines a U-shaped architecture for image segmentation with self- and cross-attention from Transformers. U-Transformer overcomes the inability of U-Nets to model long-range contextual interactions and spatial dependencies, which are arguably crucial for accurate segmentation in challenging contexts. To this end, attention mechanisms are incorporated at two main levels: a self-attention module leverages global interactions between encoder features, while cross-attention in the skip connections allows a fine spatial recovery in the U-Net decoder by filtering out non-semantic features. Experiments on two abdominal CT-image datasets show the large performance gain brought out by U-Transformer compared to U-Net and local Attention U-Nets. We also highlight the importance of using both self- and cross-attention, and the nice interpretability features brought out by U-Transformer.