 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiometric Face Presentation Attack Detection with Multi-Channel Convolutional Neural Network
Sep 19, 2019
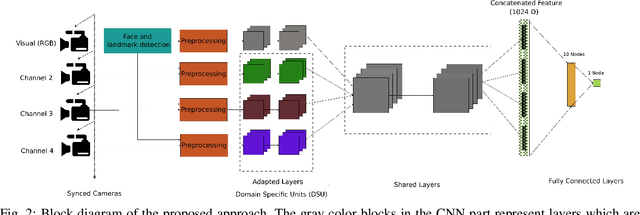

Face recognition is a mainstream biometric authentication method. However, vulnerability to presentation attacks (a.k.a spoofing) limits its usability in unsupervised applications. Even though there are many methods available for tackling presentation attacks (PA), most of them fail to detect sophisticated attacks such as silicone masks. As the quality of presentation attack instruments improves over time, achieving reliable PA detection with visual spectra alone remains very challenging. We argue that analysis in multiple channels might help to address this issue. In this context, we propose a multi-channel Convolutional Neural Network based approach for presentation attack detection (PAD). We also introduce the new Wide Multi-Channel presentation Attack (WMCA) database for face PAD which contains a wide variety of 2D and 3D presentation attacks for both impersonation and obfuscation attacks. Data from different channels such as color, depth, near-infrared and thermal are available to advance the research in face PAD. The proposed method was compared with feature-based approaches and found to outperform the baselines achieving an ACER of 0.3% on the introduced dataset. The database and the software to reproduce the results are made available publicly.
* 16 pages
Domain Adaptation in Multi-Channel Autoencoder based Features for Robust Face Anti-Spoofing
Jul 09, 2019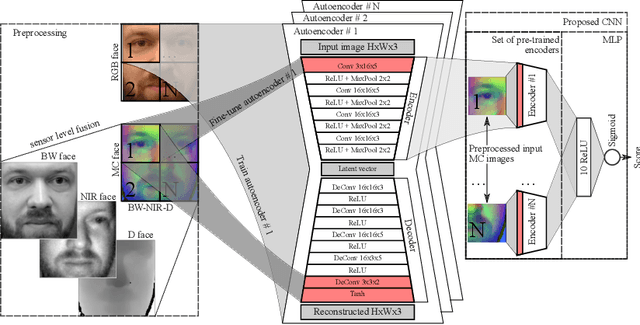
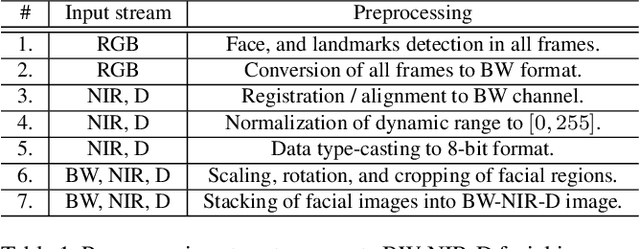
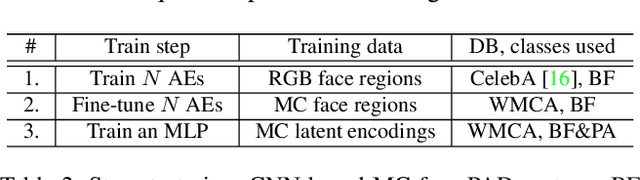

While the performance of face recognition systems has improved significantly in the last decade, they are proved to be highly vulnerable to presentation attacks (spoofing). Most of the research in the field of face presentation attack detection (PAD), was focused on boosting the performance of the systems within a single database. Face PAD datasets are usually captured with RGB cameras, and have very limited number of both bona-fide samples and presentation attack instruments. Training face PAD systems on such data leads to poor performance, even in the closed-set scenario, especially when sophisticated attacks are involved. We explore two paths to boost the performance of the face PAD system against challenging attacks. First, by using multi-channel (RGB, Depth and NIR) data, which is still easily accessible in a number of mass production devices. Second, we develop a novel Autoencoders + MLP based face PAD algorithm. Moreover, instead of collecting more data for training of the proposed deep architecture, the domain adaptation technique is proposed, transferring the knowledge of facial appearance from RGB to multi-channel domain. We also demonstrate, that learning the features of individual facial regions, is more discriminative than the features learned from an entire face. The proposed system is tested on a very recent publicly available multi-channel PAD database with a wide variety of presentation attacks.