 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying Database Activity Monitoring with Bandits
Oct 23, 2019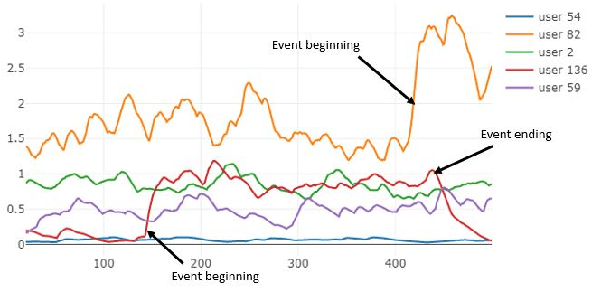
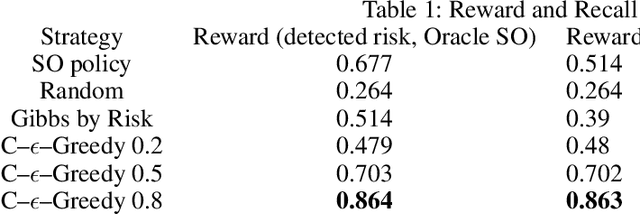
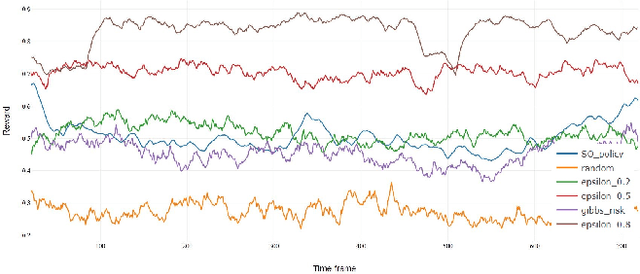
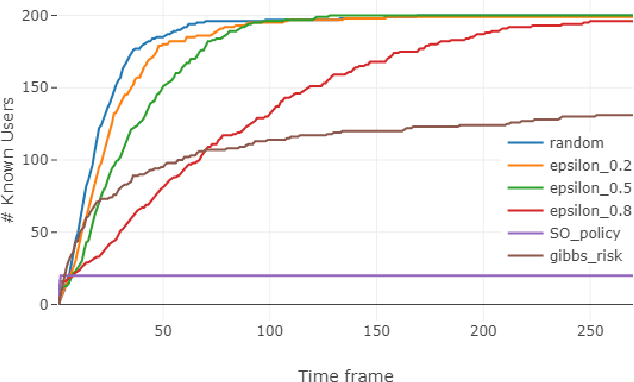
Database activity monitoring (DAM) systems are commonly used by organizations to protect the organizational data, knowledge and intellectual properties. In order to protect organizations database DAM systems have two main roles, monitoring (documenting activity) and alerting to anomalous activity. Due to high-velocity streams and operating costs, such systems are restricted to examining only a sample of the activity. Current solutions use policies, manually crafted by experts, to decide which transactions to monitor and log. This limits the diversity of the data collected. Bandit algorithms, which use reward functions as the basis for optimization while adding diversity to the recommended set, have gained increased attention in recommendation systems for improving diversity. In this work, we redefine the data sampling problem as a special case of the multi-armed bandit (MAB) problem and present a novel algorithm, which combines expert knowledge with random exploration. We analyze the effect of diversity on coverage and downstream event detection tasks using a simulated dataset. In doing so, we find that adding diversity to the sampling using the bandit-based approach works well for this task and maximizing population coverage without decreasing the quality in terms of issuing alerts about events.
Sampling High Throughput Data for Anomaly Detection of Data-Base Activity
Aug 14, 2017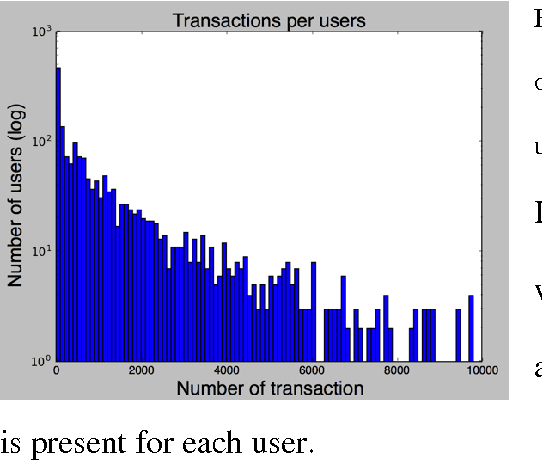
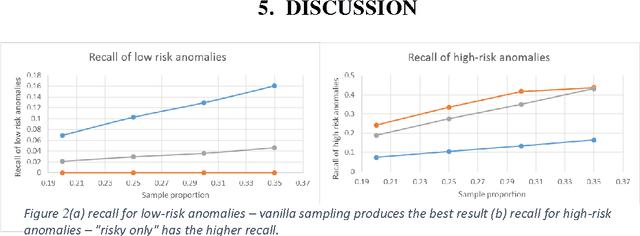
Data leakage and theft from databases is a dangerous threat to organizations. Data Security and Data Privacy protection systems (DSDP) monitor data access and usage to identify leakage or suspicious activities that should be investigated. Because of the high velocity nature of database systems, such systems audit only a portion of the vast number of transactions that take place. Anomalies are investigated by a Security Officer (SO) in order to choose the proper response. In this paper we investigate the effect of sampling methods based on the risk the transaction poses and propose a new method for "combined sampling" for capturing a more varied sample.
Temporal anomaly detection: calibrating the surprise
May 29, 2017
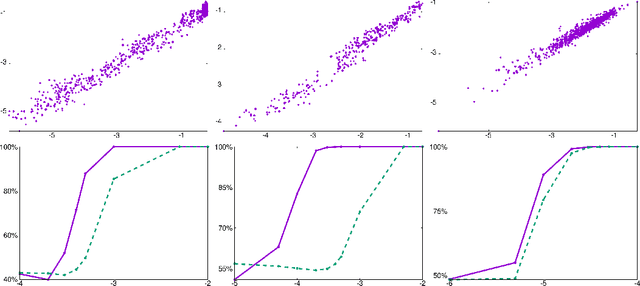
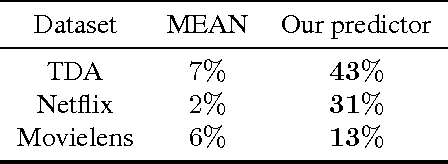
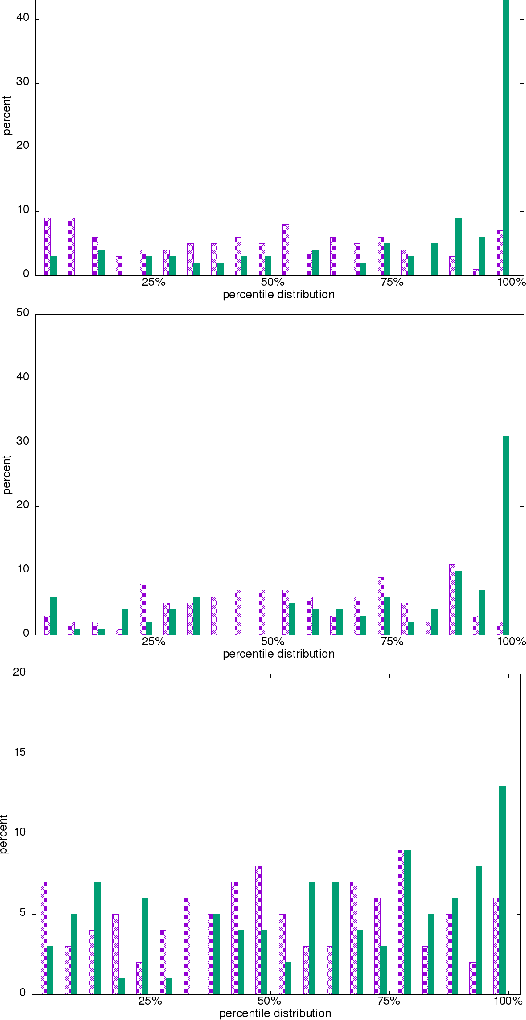
We propose a hybrid approach to temporal anomaly detection in user-database access data -- or more generally, any kind of subject-object co-occurrence data. Our methodology allows identifying anomalies based on a single stationary model, instead of requiring a full temporal one, which would be prohibitive in our setting. We learn our low-rank stationary model from the high-dimensional training data, and then fit a regression model for predicting the expected likelihood score of normal access patterns in the future. The disparity between the predicted and the observed likelihood scores is used to assess the "surprise". This approach enables calibration of the anomaly score so that time-varying normal behavior patterns are not considered anomalous. We provide a detailed description of the algorithm, including a convergence analysis, and report encouraging empirical results. One of the datasets we tested is new for the public domain. It consists of two months' worth of database access records from a live system. This dataset will be made publicly available, and is provided in the supplementary material.