 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Low-Resource Quechua ASR Improvement
Jul 14, 2022
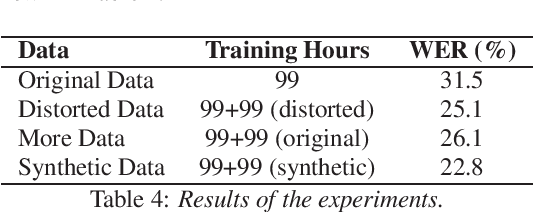
Automatic Speech Recognition (ASR) is a key element in new services that helps users to interact with an automated system. Deep learning methods have made it possible to deploy systems with word error rates below 5% for ASR of English. However, the use of these methods is only available for languages with hundreds or thousands of hours of audio and their corresponding transcriptions. For the so-called low-resource languages to speed up the availability of resources that can improve the performance of their ASR systems, methods of creating new resources on the basis of existing ones are being investigated. In this paper we describe our data augmentation approach to improve the results of ASR models for low-resource and agglutinative languages. We carry out experiments developing an ASR for Quechua using the wav2letter++ model. We reduced WER by 8.73% through our approach to the base model. The resulting ASR model obtained 22.75% WER and was trained with 99 hours of original resources and 99 hours of synthetic data obtained with a combination of text augmentation and synthetic speech generati