 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Feature Gap for Adversarial Robustness by Feature Disentanglement
Jan 26, 2024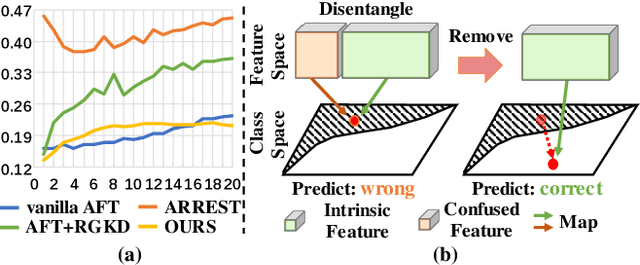
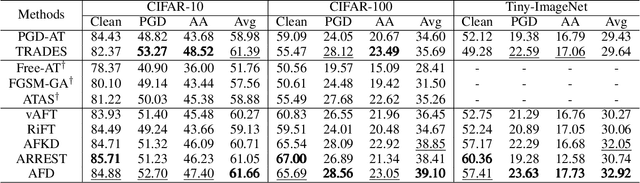
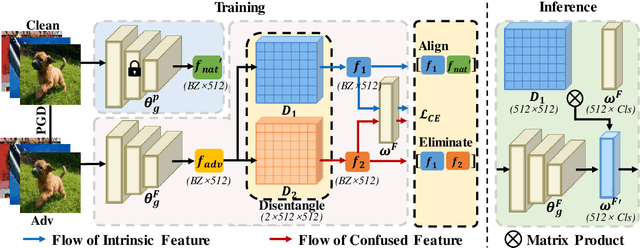
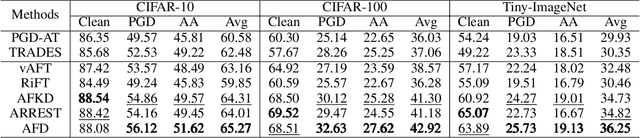
Deep neural networks are vulnerable to adversarial samples. Adversarial fine-tuning methods aim to enhance adversarial robustness through fine-tuning the naturally pre-trained model in an adversarial training manner. However, we identify that some latent features of adversarial samples are confused by adversarial perturbation and lead to an unexpectedly increasing gap between features in the last hidden layer of natural and adversarial samples. To address this issue, we propose a disentanglement-based approach to explicitly model and further remove the latent features that cause the feature gap. Specifically, we introduce a feature disentangler to separate out the latent features from the features of the adversarial samples, thereby boosting robustness by eliminating the latent features. Besides, we align features in the pre-trained model with features of adversarial samples in the fine-tuned model, to further benefit from the features from natural samples without confusion. Empirical evaluations on three benchmark datasets demonstrate that our approach surpasses existing adversarial fine-tuning methods and adversarial training baselines.
Robust Representation Learning via Asymmetric Negative Contrast and Reverse Attention
Oct 05, 2023Deep neural networks are vulnerable to adversarial noise. Adversarial training (AT) has been demonstrated to be the most effective defense strategy to protect neural networks from being fooled. However, we find AT omits to learning robust features, resulting in poor performance of adversarial robustness. To address this issue, we highlight two characteristics of robust representation: (1) $\bf{exclusion}$: the feature of natural examples keeps away from that of other classes; (2) $\bf{alignment}$: the feature of natural and corresponding adversarial examples is close to each other. These motivate us to propose a generic framework of AT to gain robust representation, by the asymmetric negative contrast and reverse attention. Specifically, we design an asymmetric negative contrast based on predicted probabilities, to push away examples of different classes in the feature space. Moreover, we propose to weight feature by parameters of the linear classifier as the reverse attention, to obtain class-aware feature and pull close the feature of the same class. Empirical evaluations on three benchmark datasets show our methods greatly advance the robustness of AT and achieve state-of-the-art performance. Code is available at <https://github.com/changzhang777/ANCRA>.